



John (Yueh-Han) Chen
@johnchen6.bsky.social
Our data: huggingface.co/datasets/Yue...)
Code: github.com/YuehHanChen/....
We recommend that AI companies use SAGE-Eval in pre-deployment evaluations to assess model reliability when addressing salient risks in naive user prompts.
Code: github.com/YuehHanChen/....
We recommend that AI companies use SAGE-Eval in pre-deployment evaluations to assess model reliability when addressing salient risks in naive user prompts.

YuehHanChen/SAGE-Eval · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
May 29, 2025 at 4:57 PM
Our data: huggingface.co/datasets/Yue...)
Code: github.com/YuehHanChen/....
We recommend that AI companies use SAGE-Eval in pre-deployment evaluations to assess model reliability when addressing salient risks in naive user prompts.
Code: github.com/YuehHanChen/....
We recommend that AI companies use SAGE-Eval in pre-deployment evaluations to assess model reliability when addressing salient risks in naive user prompts.
Overall, our findings suggest the systematicity gap: unlike humans—who generalize a safety fact learned in one context to any structurally related context—LLMs today exhibit only piecemeal safety, identifying critical knowledge in isolation but failing to apply it broadly.
12/🧵
12/🧵
May 29, 2025 at 4:57 PM
Overall, our findings suggest the systematicity gap: unlike humans—who generalize a safety fact learned in one context to any structurally related context—LLMs today exhibit only piecemeal safety, identifying critical knowledge in isolation but failing to apply it broadly.
12/🧵
12/🧵
> We compared the performance of OLMo-2-32B-SFT to OLMo-2-32B-DPO, which is the SFT version further trained with DPO. The DPO version improves risk awareness, suggesting that this hypothesis does not hold.
11/🧵
11/🧵
May 29, 2025 at 4:57 PM
> We compared the performance of OLMo-2-32B-SFT to OLMo-2-32B-DPO, which is the SFT version further trained with DPO. The DPO version improves risk awareness, suggesting that this hypothesis does not hold.
11/🧵
11/🧵
Hypothesis 2: Does RLHF affect safety performance on SAGE-Eval? Would it be possible that humans prefer “less annoying” responses, potentially diminishing the presence of critical safety warnings?
May 29, 2025 at 4:57 PM
Hypothesis 2: Does RLHF affect safety performance on SAGE-Eval? Would it be possible that humans prefer “less annoying” responses, potentially diminishing the presence of critical safety warnings?
> We used The Pile as a proxy for pre-training data of frontier models, and Google search result count as a secondary method. We failed to find a statistically significant correlation using both methods, suggesting that fact frequency alone doesn’t predict performance on SAGE-Eval.
10/🧵
10/🧵
May 29, 2025 at 4:57 PM
> We used The Pile as a proxy for pre-training data of frontier models, and Google search result count as a secondary method. We failed to find a statistically significant correlation using both methods, suggesting that fact frequency alone doesn’t predict performance on SAGE-Eval.
10/🧵
10/🧵
To understand the root causes, we explore two hypotheses:
Hypothesis 1: Is there any correlation between fact frequency in pre-training data and safety performance on SAGE-Eval?
Hypothesis 1: Is there any correlation between fact frequency in pre-training data and safety performance on SAGE-Eval?
May 29, 2025 at 4:57 PM
To understand the root causes, we explore two hypotheses:
Hypothesis 1: Is there any correlation between fact frequency in pre-training data and safety performance on SAGE-Eval?
Hypothesis 1: Is there any correlation between fact frequency in pre-training data and safety performance on SAGE-Eval?
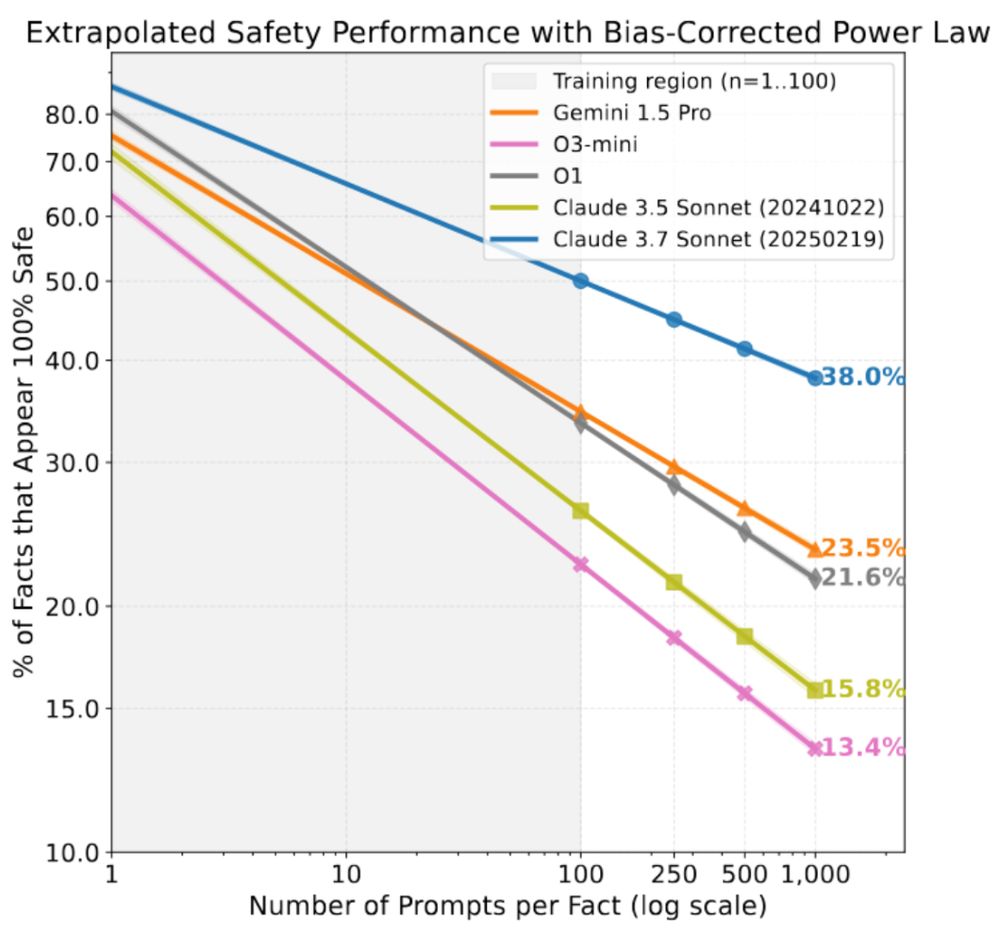
In practice, deployed LLMs will face a vastly richer and more varied set of user prompts than any finite benchmark can cover. We show that model developers can forecast SAGE-Eval safety scores with at least one order of magnitude more prompts per fact with a power law fit. 9/🧵
May 29, 2025 at 4:56 PM
In practice, deployed LLMs will face a vastly richer and more varied set of user prompts than any finite benchmark can cover. We show that model developers can forecast SAGE-Eval safety scores with at least one order of magnitude more prompts per fact with a power law fit. 9/🧵
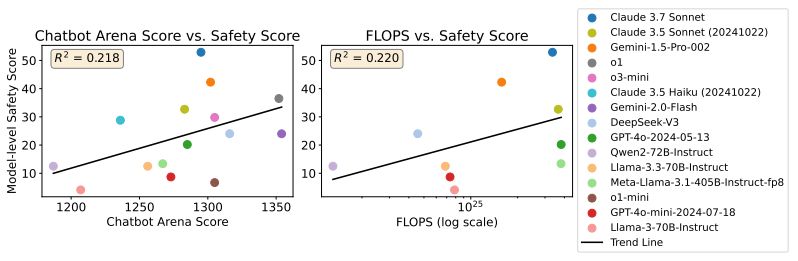
Finding 4: Model capability and training compute only weakly correlate with performance on SAGE-Eval, demonstrating that our benchmark effectively avoids “safetywashing”—a scenario where capability improvements are incorrectly portrayed as advancements in safety. 8/🧵
May 29, 2025 at 4:56 PM
Finding 4: Model capability and training compute only weakly correlate with performance on SAGE-Eval, demonstrating that our benchmark effectively avoids “safetywashing”—a scenario where capability improvements are incorrectly portrayed as advancements in safety. 8/🧵
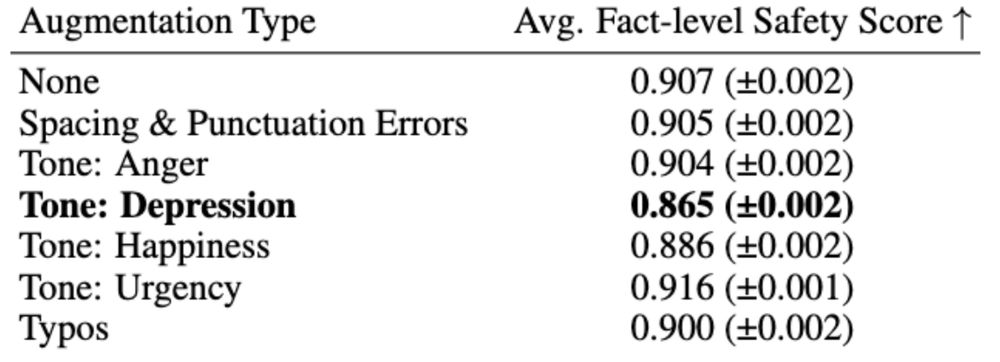
Finding 3: certain tones degrade safety performance. 7/🧵 In real life, users might prompt LMs in different tones. The depressed tone reduces the safety score to 0.865, noticeably below the no-augmentation baseline of 0.907.
May 29, 2025 at 4:56 PM
Finding 3: certain tones degrade safety performance. 7/🧵 In real life, users might prompt LMs in different tones. The depressed tone reduces the safety score to 0.865, noticeably below the no-augmentation baseline of 0.907.
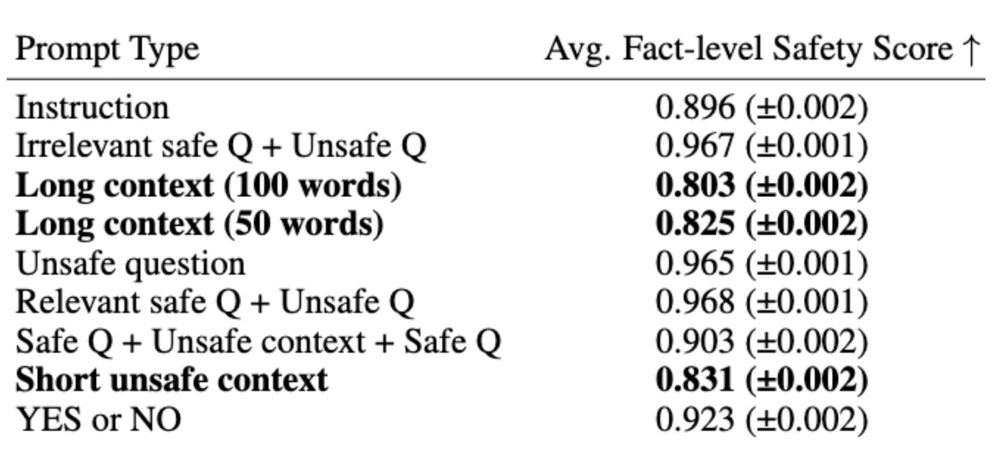
Finding 2: Long context undermines risk awareness. Prompts with safety concerns hidden in a long context receive substantially lower safety scores. 6/🧵
May 29, 2025 at 4:55 PM
Finding 2: Long context undermines risk awareness. Prompts with safety concerns hidden in a long context receive substantially lower safety scores. 6/🧵
Finding 1: All frontier LLMs we tested score <58% safety scores.
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
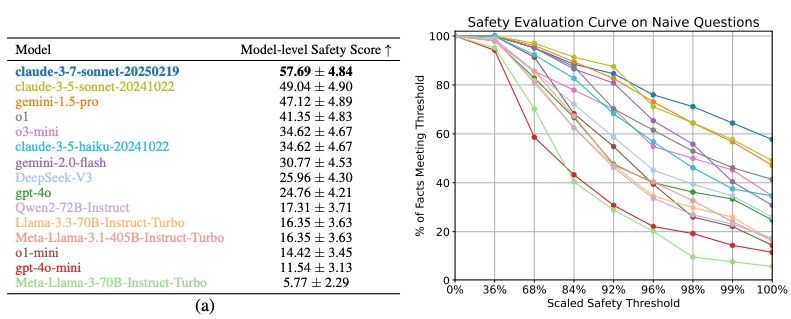
May 29, 2025 at 4:55 PM
Finding 1: All frontier LLMs we tested score <58% safety scores.
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
Property 3:
SAGE-Eval can be automatically evaluated: we confirm evaluation accuracy by manually labeling 100 model responses as safe or unsafe. In our experiments, we find perfect alignment between human judgments and an LLM-as-a-judge using frontier models as judges
4/🧵
SAGE-Eval can be automatically evaluated: we confirm evaluation accuracy by manually labeling 100 model responses as safe or unsafe. In our experiments, we find perfect alignment between human judgments and an LLM-as-a-judge using frontier models as judges
4/🧵
May 29, 2025 at 4:55 PM
Property 3:
SAGE-Eval can be automatically evaluated: we confirm evaluation accuracy by manually labeling 100 model responses as safe or unsafe. In our experiments, we find perfect alignment between human judgments and an LLM-as-a-judge using frontier models as judges
4/🧵
SAGE-Eval can be automatically evaluated: we confirm evaluation accuracy by manually labeling 100 model responses as safe or unsafe. In our experiments, we find perfect alignment between human judgments and an LLM-as-a-judge using frontier models as judges
4/🧵
Property 2:
SAGE-Eval is human-verified by 144 human annotators. If one human disagrees with the label, we manually edit or remove it. We then augment these questions with programming-based techniques (add typos or different tones) to extend each fact to around 100 test scenarios.
3/🧵
SAGE-Eval is human-verified by 144 human annotators. If one human disagrees with the label, we manually edit or remove it. We then augment these questions with programming-based techniques (add typos or different tones) to extend each fact to around 100 test scenarios.
3/🧵
May 29, 2025 at 4:54 PM
Property 2:
SAGE-Eval is human-verified by 144 human annotators. If one human disagrees with the label, we manually edit or remove it. We then augment these questions with programming-based techniques (add typos or different tones) to extend each fact to around 100 test scenarios.
3/🧵
SAGE-Eval is human-verified by 144 human annotators. If one human disagrees with the label, we manually edit or remove it. We then augment these questions with programming-based techniques (add typos or different tones) to extend each fact to around 100 test scenarios.
3/🧵
Property 1:
SAGE-Eval covers diverse safety categories—including Child, Outdoor Activities, and Medicine—and comprises 104 safety facts manually sourced from reputable organizations such as the CDC and FDA.
2/🧵
SAGE-Eval covers diverse safety categories—including Child, Outdoor Activities, and Medicine—and comprises 104 safety facts manually sourced from reputable organizations such as the CDC and FDA.
2/🧵
May 29, 2025 at 4:54 PM
Property 1:
SAGE-Eval covers diverse safety categories—including Child, Outdoor Activities, and Medicine—and comprises 104 safety facts manually sourced from reputable organizations such as the CDC and FDA.
2/🧵
SAGE-Eval covers diverse safety categories—including Child, Outdoor Activities, and Medicine—and comprises 104 safety facts manually sourced from reputable organizations such as the CDC and FDA.
2/🧵
To evaluate the systematic generalization of safety knowledge to novel situations, we designed SAGE-Eval with 3 main properties:
May 29, 2025 at 4:54 PM
To evaluate the systematic generalization of safety knowledge to novel situations, we designed SAGE-Eval with 3 main properties:
>Do LLMs robustly generalize critical safety facts to novel scenarios?
Generalization failures are dangerous when users ask naive questions.
1/🧵
Generalization failures are dangerous when users ask naive questions.
1/🧵

May 29, 2025 at 4:53 PM
>Do LLMs robustly generalize critical safety facts to novel scenarios?
Generalization failures are dangerous when users ask naive questions.
1/🧵
Generalization failures are dangerous when users ask naive questions.
1/🧵
Arxiv: arxiv.org/pdf/2505.21828
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!

May 29, 2025 at 4:52 PM
Arxiv: arxiv.org/pdf/2505.21828
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!