



Vishakh Padmakumar
@vishakhpk.bsky.social
PhD Student @nyudatascience.bsky.social, working with He He on NLP and Human-AI Collaboration.
Also hanging out @ai2.bsky.social
Website - https://vishakhpk.github.io/
Also hanging out @ai2.bsky.social
Website - https://vishakhpk.github.io/
Pinned
Vishakh Padmakumar
@vishakhpk.bsky.social
· Apr 29
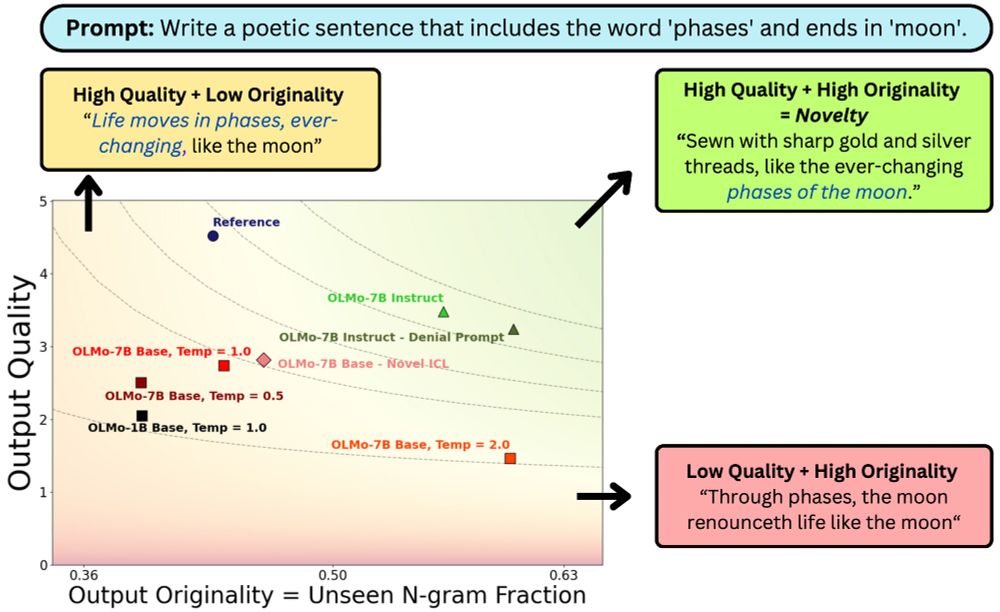
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Last year I worked at @adobe.com and @ai2.bsky.social, exploring how we can help users read, organize and understand long documents. This piece covers what we learned on modelling user intent and combining LLMs with principled tools when building complex pipelines for it!
CDS PhD alum Vishakh Padmakumar (@vishakhpk.bsky.social), now at Stanford, tackled the hard part of summarization — deciding what matters.
At Adobe, he built diversity-aware summarizers; at AI2, intent-based tools for literature review tables.
nyudatascience.medium.com/supercharged...
At Adobe, he built diversity-aware summarizers; at AI2, intent-based tools for literature review tables.
nyudatascience.medium.com/supercharged...

Supercharged Information Synthesis: CDS Alum Teaches AI Models What Information Actually Matters
CDS PhD alum Vishakh Padmakumar tackled summarization’s hardest challenge: choosing what matters.
nyudatascience.medium.com
November 7, 2025 at 5:47 PM
Last year I worked at @adobe.com and @ai2.bsky.social, exploring how we can help users read, organize and understand long documents. This piece covers what we learned on modelling user intent and combining LLMs with principled tools when building complex pipelines for it!
Reposted by Vishakh Padmakumar

CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
Read more: nyudatascience.medium.com/in-ai-genera...
In AI-Generated Content, A Trade-Off Between Quality and Originality
New research from CDS researchers maps the trade-off between originality and quality in LLM outputs.
nyudatascience.medium.com
May 30, 2025 at 4:07 PM
CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
Read more: nyudatascience.medium.com/in-ai-genera...
Reposted by Vishakh Padmakumar

I wrote a post on how to connect with people (i.e., make friends) at CS conferences. These events can be intimidating so here's some suggestions on how to navigate them
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...

Tips on How to Connect at Academic Conferences
I was a kinda awkward teenager. If you are a CS researcher reading this post, then chances are, you were too. How to navigate social situations and make friends is not always intuitive, and has to …
kamathematics.wordpress.com
May 1, 2025 at 12:57 PM
I wrote a post on how to connect with people (i.e., make friends) at CS conferences. These events can be intimidating so here's some suggestions on how to navigate them
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
I'm late for #ICLR2025 #NAACL2025, but in time for #AISTATS2025 #ICML2025! 1/3
kamathematics.wordpress.com/2025/05/01/t...
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
April 29, 2025 at 4:35 PM
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Reposted by Vishakh Padmakumar

When using LLM-as-a-judge, practitioners often use greedy decoding to get the most likely judgment. But we found that deriving a score from the judgment distribution (like taking the mean) works better!
❌LLM-as-a-judge with greedy decoding
😎Using the distribution of the judge’s labels
❌LLM-as-a-judge with greedy decoding
😎Using the distribution of the judge’s labels
LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)

March 6, 2025 at 10:04 PM
When using LLM-as-a-judge, practitioners often use greedy decoding to get the most likely judgment. But we found that deriving a score from the judgment distribution (like taking the mean) works better!
❌LLM-as-a-judge with greedy decoding
😎Using the distribution of the judge’s labels
❌LLM-as-a-judge with greedy decoding
😎Using the distribution of the judge’s labels
Reposted by Vishakh Padmakumar

LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
March 6, 2025 at 2:32 PM
LLM judges have become ubiquitous, but valuable signal is often ignored at inference.
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
We analyze design decisions for leveraging judgment distributions from LLM-as-a-judge: 🧵
(w/ Michael J.Q. Zhang, @eunsol.bsky.social)
Reposted by Vishakh Padmakumar

Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!

February 25, 2025 at 10:33 PM
Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!
Reposted by Vishakh Padmakumar

🚨New Paper! So o3-mini and R1 seem to excel on math & coding. But how good are they on other domains where verifiable rewards are not easily available, such as theory of mind (ToM)? Do they show similar behavioral patterns? 🤔 What if I told you it's...interesting, like the below?🧵

February 20, 2025 at 5:34 PM
🚨New Paper! So o3-mini and R1 seem to excel on math & coding. But how good are they on other domains where verifiable rewards are not easily available, such as theory of mind (ToM)? Do they show similar behavioral patterns? 🤔 What if I told you it's...interesting, like the below?🧵
Reposted by Vishakh Padmakumar

🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N

February 18, 2025 at 12:31 PM
🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
Reposted by Vishakh Padmakumar

(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @tomerullman.bsky.social and @jennhu.bsky.social, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427

February 10, 2025 at 5:20 PM
(1/9) Excited to share my recent work on "Alignment reduces LM's conceptual diversity" with @tomerullman.bsky.social and @jennhu.bsky.social, to appear at #NAACL2025! 🐟
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
We want models that match our values...but could this hurt their diversity of thought?
Preprint: arxiv.org/abs/2411.04427
Reposted by Vishakh Padmakumar

« appending "Wait" multiple times to the model's generation » is our current most likely path to AGI :)
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.

February 3, 2025 at 2:31 PM
« appending "Wait" multiple times to the model's generation » is our current most likely path to AGI :)
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
See the fresh arxiv.org/abs/2501.19393 by Niklas Muennighoff et al.
Reposted by Vishakh Padmakumar
CDS' He He, @vishakhpk.bsky.social, & former CDS postdoc Abulhair Saparov, et al, find major AI limits in “Transformers Struggle to Learn to Search.”
AI models excel at single-step reasoning but fail in systematic exploration as tasks grow in complexity.
nyudatascience.medium.com/even-simple-...
AI models excel at single-step reasoning but fail in systematic exploration as tasks grow in complexity.
nyudatascience.medium.com/even-simple-...

Even Simple Search Tasks Reveal Fundamental Limits in AI Language Models
Research by CDS’ He He, Vishakh Padmakumar, and others shows that LLMs’ reasoning relies on heuristics, not systematic exploration.
nyudatascience.medium.com
January 31, 2025 at 5:30 PM
CDS' He He, @vishakhpk.bsky.social, & former CDS postdoc Abulhair Saparov, et al, find major AI limits in “Transformers Struggle to Learn to Search.”
AI models excel at single-step reasoning but fail in systematic exploration as tasks grow in complexity.
nyudatascience.medium.com/even-simple-...
AI models excel at single-step reasoning but fail in systematic exploration as tasks grow in complexity.
nyudatascience.medium.com/even-simple-...
Reposted by Vishakh Padmakumar

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

January 28, 2025 at 2:55 PM
People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Reposted by Vishakh Padmakumar

🔥While LLM reasoning is on people's minds...
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4

January 20, 2025 at 7:28 PM
🔥While LLM reasoning is on people's minds...
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4