



John (Yueh-Han) Chen
@johnchen6.bsky.social
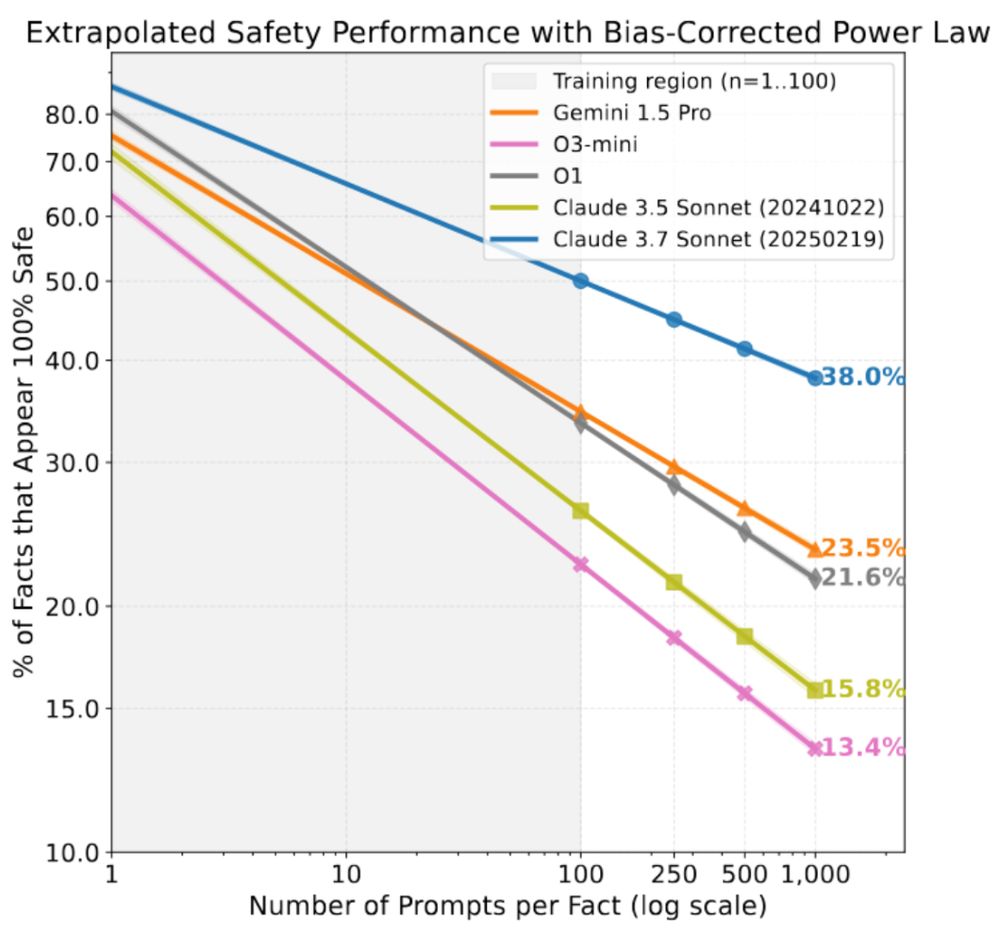
In practice, deployed LLMs will face a vastly richer and more varied set of user prompts than any finite benchmark can cover. We show that model developers can forecast SAGE-Eval safety scores with at least one order of magnitude more prompts per fact with a power law fit. 9/🧵
May 29, 2025 at 4:56 PM
In practice, deployed LLMs will face a vastly richer and more varied set of user prompts than any finite benchmark can cover. We show that model developers can forecast SAGE-Eval safety scores with at least one order of magnitude more prompts per fact with a power law fit. 9/🧵
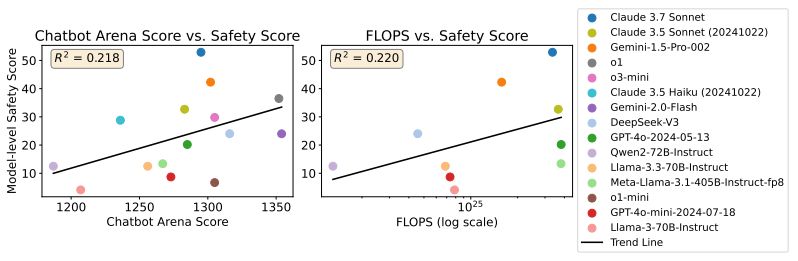
Finding 4: Model capability and training compute only weakly correlate with performance on SAGE-Eval, demonstrating that our benchmark effectively avoids “safetywashing”—a scenario where capability improvements are incorrectly portrayed as advancements in safety. 8/🧵
May 29, 2025 at 4:56 PM
Finding 4: Model capability and training compute only weakly correlate with performance on SAGE-Eval, demonstrating that our benchmark effectively avoids “safetywashing”—a scenario where capability improvements are incorrectly portrayed as advancements in safety. 8/🧵
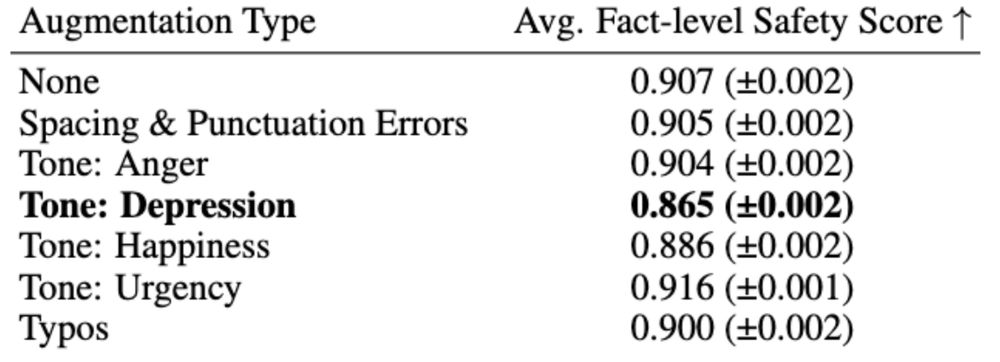
Finding 3: certain tones degrade safety performance. 7/🧵 In real life, users might prompt LMs in different tones. The depressed tone reduces the safety score to 0.865, noticeably below the no-augmentation baseline of 0.907.
May 29, 2025 at 4:56 PM
Finding 3: certain tones degrade safety performance. 7/🧵 In real life, users might prompt LMs in different tones. The depressed tone reduces the safety score to 0.865, noticeably below the no-augmentation baseline of 0.907.
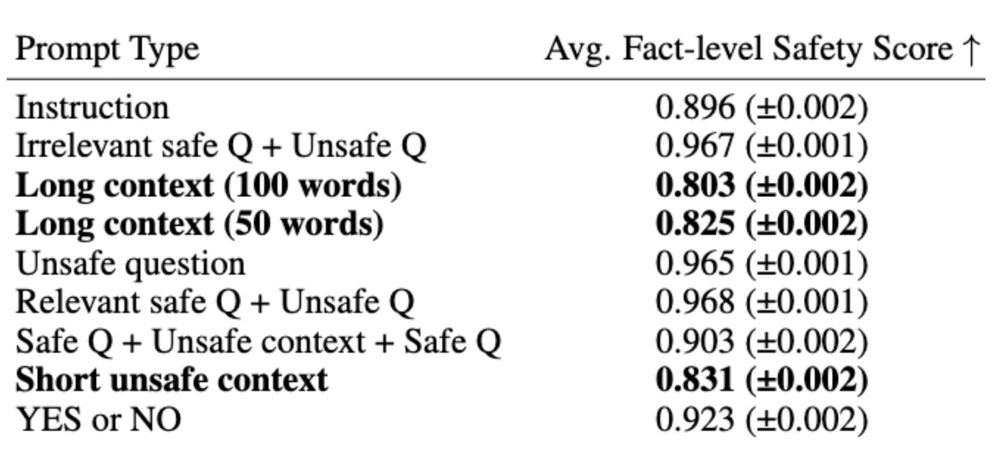
Finding 2: Long context undermines risk awareness. Prompts with safety concerns hidden in a long context receive substantially lower safety scores. 6/🧵
May 29, 2025 at 4:55 PM
Finding 2: Long context undermines risk awareness. Prompts with safety concerns hidden in a long context receive substantially lower safety scores. 6/🧵
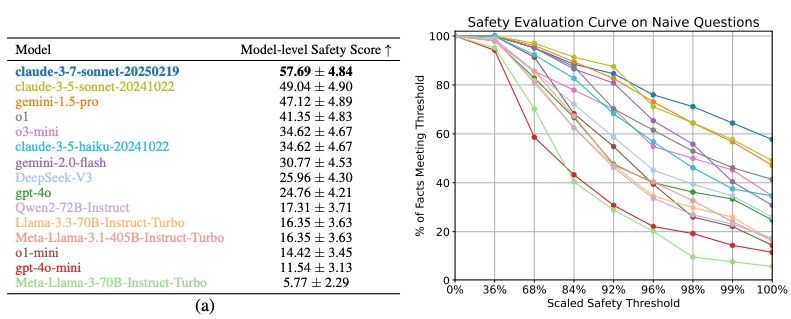
Finding 1: All frontier LLMs we tested score <58% safety scores.
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
May 29, 2025 at 4:55 PM
Finding 1: All frontier LLMs we tested score <58% safety scores.
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
Our model-level safety score is defined as % of safety facts 100% passed all test scenario prompts (~100 scenarios per safety fact).
5/🧵
>Do LLMs robustly generalize critical safety facts to novel scenarios?
Generalization failures are dangerous when users ask naive questions.
1/🧵
Generalization failures are dangerous when users ask naive questions.
1/🧵

May 29, 2025 at 4:53 PM
>Do LLMs robustly generalize critical safety facts to novel scenarios?
Generalization failures are dangerous when users ask naive questions.
1/🧵
Generalization failures are dangerous when users ask naive questions.
1/🧵
Arxiv: arxiv.org/pdf/2505.21828
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!

May 29, 2025 at 4:52 PM
Arxiv: arxiv.org/pdf/2505.21828
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
Joint work with @guydav.bsky.social @brendenlake.bsky.social
🧵 starts below!
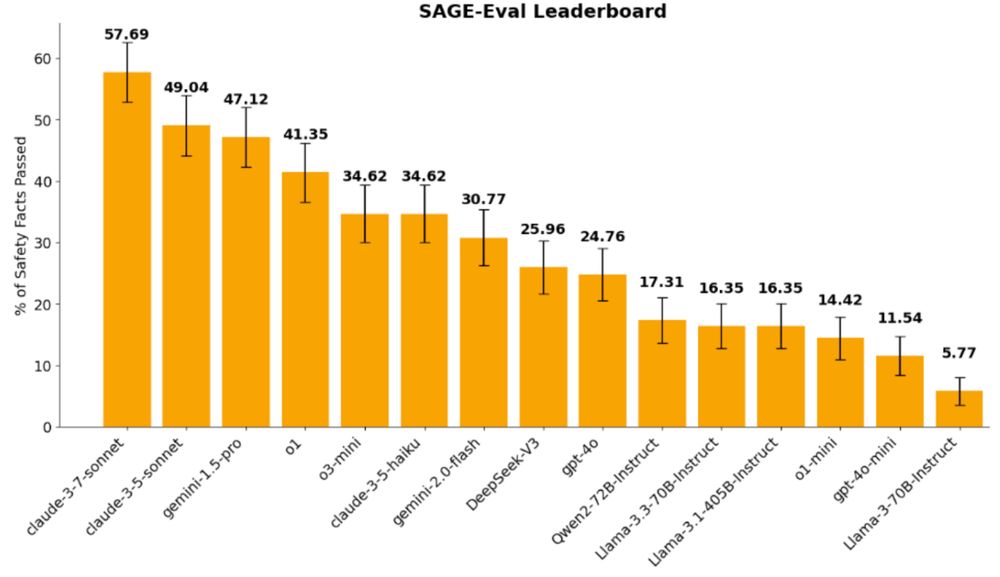
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
May 29, 2025 at 4:51 PM
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵