




Dávid Komorowicz
@dawars.me
PhD candidate @Jena_DH & @TU_Muenchen working on 3D Reconstruction from Historic Imagery. @TU_Muenchen graduate.
📍 Munich
📍 Munich
Reposted by Dávid Komorowicz

Choosing the right colormap is tricky, too often, they hide subtle details or distort the data. Our new method transforms colormaps to boost local contrast and reveal just noticeable differences, all while keeping the visualization perceptually accurate and accessible.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...

August 15, 2025 at 3:44 PM
Choosing the right colormap is tricky, too often, they hide subtle details or distort the data. Our new method transforms colormaps to boost local contrast and reveal just noticeable differences, all while keeping the visualization perceptually accurate and accessible.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...
Reposted by Dávid Komorowicz

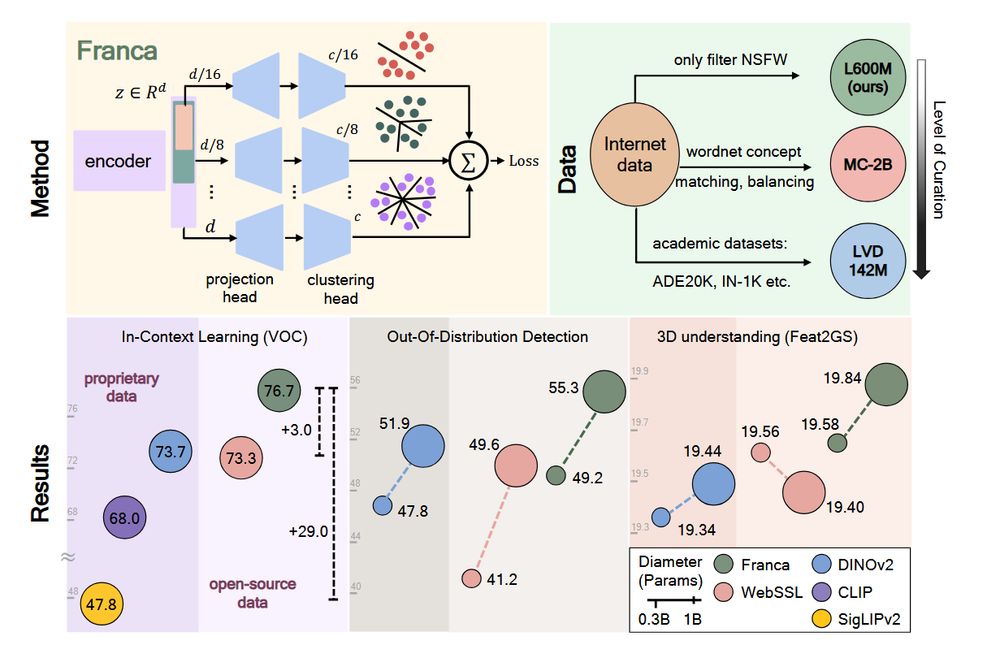
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
July 21, 2025 at 2:47 PM
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
Reposted by Dávid Komorowicz

How can one reconstruct the complete 3D interior of a wood block using only photos of its surfaces? 🪵
At SIGGRAPH'25 (Thursday!), Maria Larsson will present *Mokume*: a dataset of 190 diverse wood samples and a pipeline that solves this inverse texturing challenge. 🧵👇
At SIGGRAPH'25 (Thursday!), Maria Larsson will present *Mokume*: a dataset of 190 diverse wood samples and a pipeline that solves this inverse texturing challenge. 🧵👇

August 8, 2025 at 11:53 AM
How can one reconstruct the complete 3D interior of a wood block using only photos of its surfaces? 🪵
At SIGGRAPH'25 (Thursday!), Maria Larsson will present *Mokume*: a dataset of 190 diverse wood samples and a pipeline that solves this inverse texturing challenge. 🧵👇
At SIGGRAPH'25 (Thursday!), Maria Larsson will present *Mokume*: a dataset of 190 diverse wood samples and a pipeline that solves this inverse texturing challenge. 🧵👇
Reposted by Dávid Komorowicz

VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization
Sania Waheed, Na Min An, Michael Milford , Sarvapali D. Ramchurn, Shoaib Ehsan
tl;dr: in title
arxiv.org/abs/2507.17455
Sania Waheed, Na Min An, Michael Milford , Sarvapali D. Ramchurn, Shoaib Ehsan
tl;dr: in title
arxiv.org/abs/2507.17455
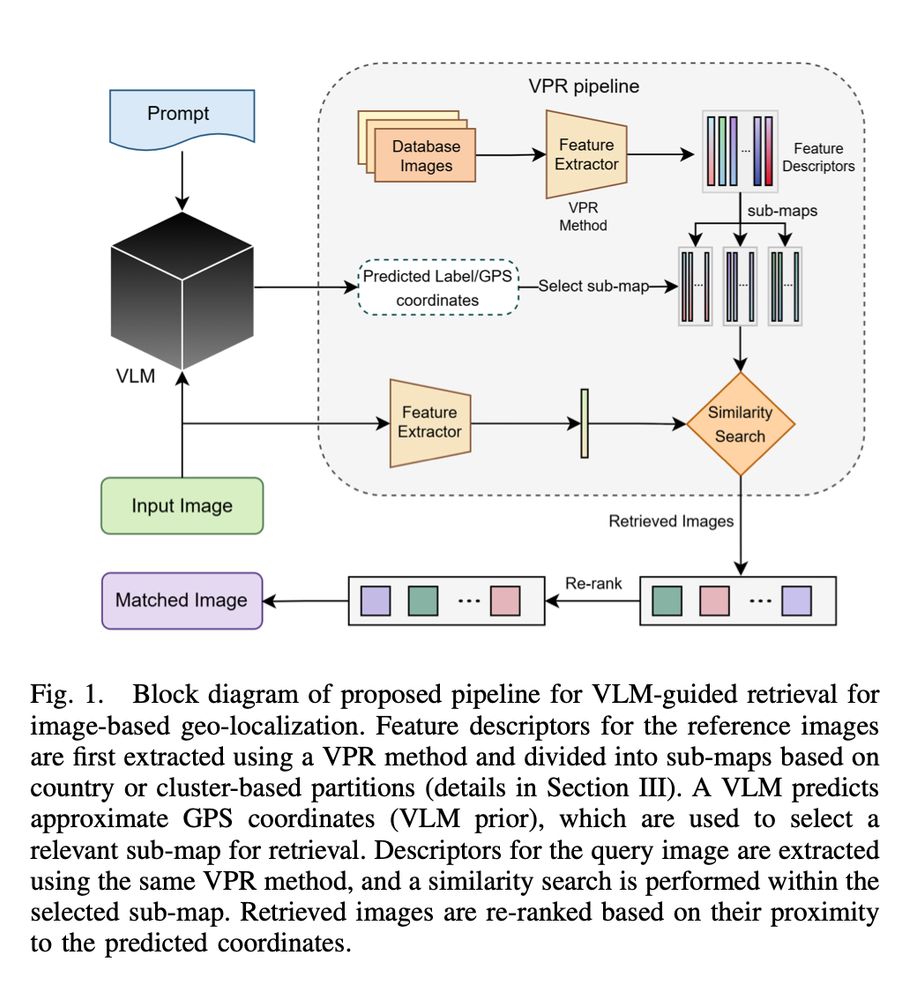

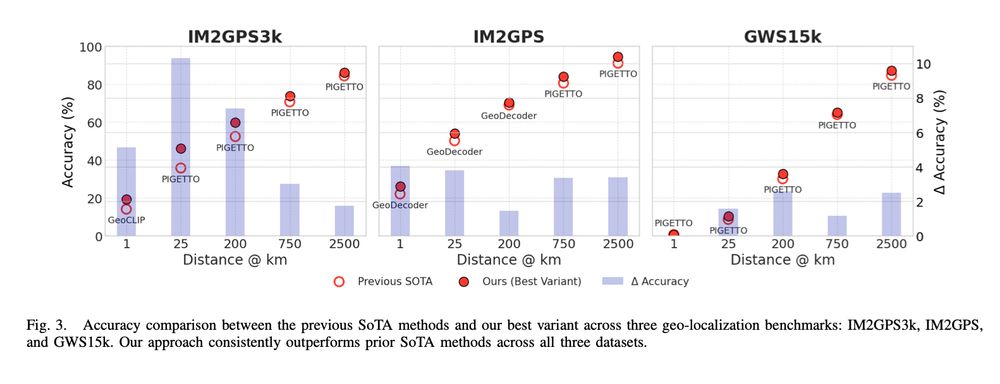

August 5, 2025 at 8:11 AM
VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization
Sania Waheed, Na Min An, Michael Milford , Sarvapali D. Ramchurn, Shoaib Ehsan
tl;dr: in title
arxiv.org/abs/2507.17455
Sania Waheed, Na Min An, Michael Milford , Sarvapali D. Ramchurn, Shoaib Ehsan
tl;dr: in title
arxiv.org/abs/2507.17455
Reposted by Dávid Komorowicz

Unposed 3DGS Reconstruction with Probabilistic Procrustes Mapping
Chong Cheng, Zijian Wang, Sicheng Yu, Yu Hu, Nanjie Yao, Hao Wang
tl;dr: submap alignment->point cloud registration->robust Umeyama algorithm->global point cloud and camera trajectory
arxiv.org/abs/2507.18541
Chong Cheng, Zijian Wang, Sicheng Yu, Yu Hu, Nanjie Yao, Hao Wang
tl;dr: submap alignment->point cloud registration->robust Umeyama algorithm->global point cloud and camera trajectory
arxiv.org/abs/2507.18541
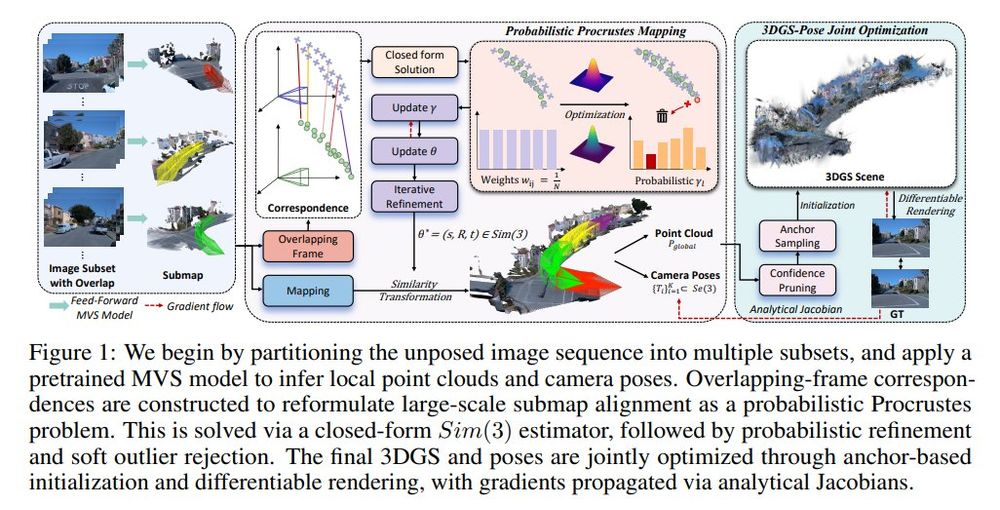
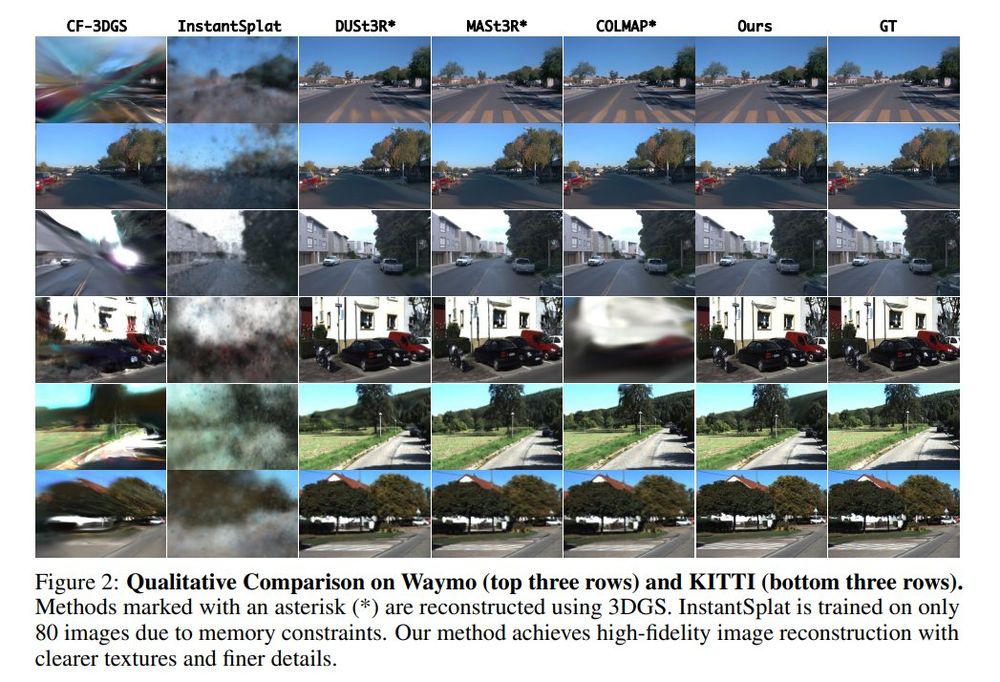
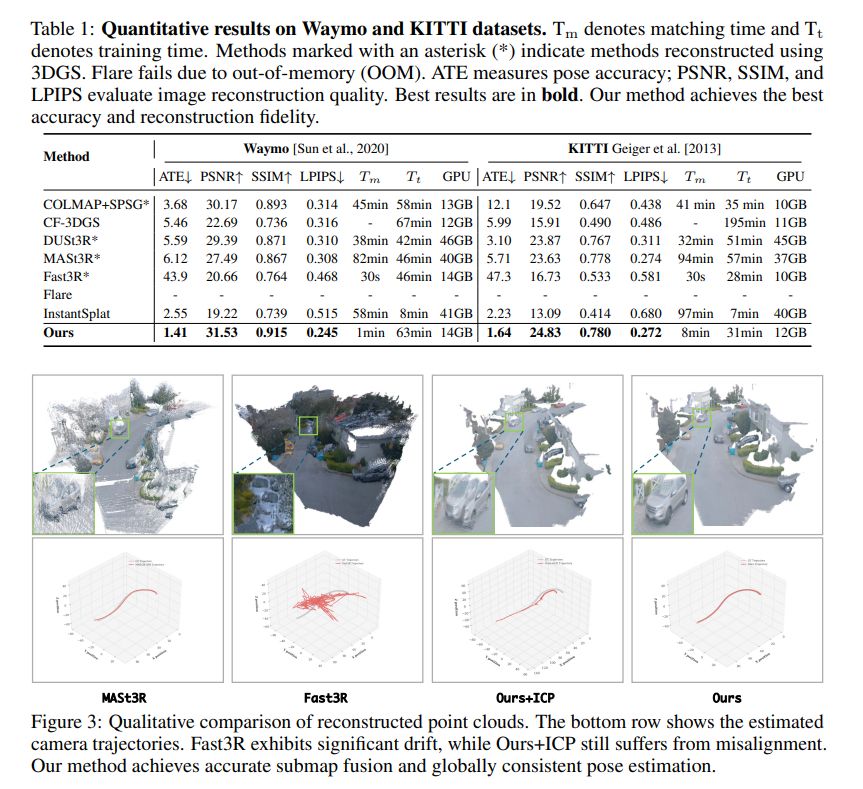
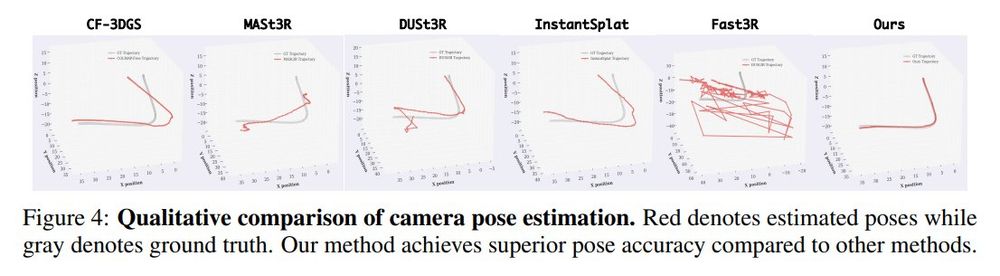
July 25, 2025 at 12:43 PM
Unposed 3DGS Reconstruction with Probabilistic Procrustes Mapping
Chong Cheng, Zijian Wang, Sicheng Yu, Yu Hu, Nanjie Yao, Hao Wang
tl;dr: submap alignment->point cloud registration->robust Umeyama algorithm->global point cloud and camera trajectory
arxiv.org/abs/2507.18541
Chong Cheng, Zijian Wang, Sicheng Yu, Yu Hu, Nanjie Yao, Hao Wang
tl;dr: submap alignment->point cloud registration->robust Umeyama algorithm->global point cloud and camera trajectory
arxiv.org/abs/2507.18541
Reposted by Dávid Komorowicz

New 3D foundation model dropped.
Note: Seems they might have messed up their image matching metrics (seems like acc rather than auc), but should be at least as good as mast3r.
Note: Seems they might have messed up their image matching metrics (seems like acc rather than auc), but should be at least as good as mast3r.

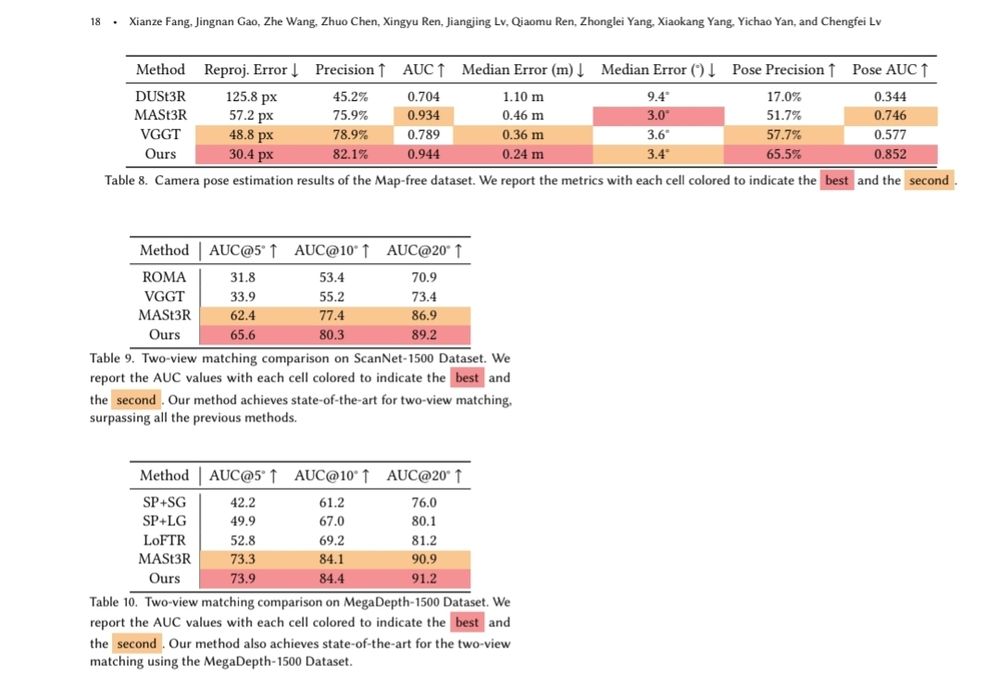
July 24, 2025 at 10:50 PM
New 3D foundation model dropped.
Note: Seems they might have messed up their image matching metrics (seems like acc rather than auc), but should be at least as good as mast3r.
Note: Seems they might have messed up their image matching metrics (seems like acc rather than auc), but should be at least as good as mast3r.
Turns out that by default huggingface models run on the CPU...
July 20, 2025 at 12:10 PM
Turns out that by default huggingface models run on the CPU...
Reposted by Dávid Komorowicz
Reposted by Dávid Komorowicz

Sofar it doesn’t look good: neurips.cc/FAQ/AuthorRe...
“At least one author of each accepted paper must register for the main conference. A ‘Virtual Only Pass’ is not sufficient.”
“At least one author of each accepted paper must register for the main conference. A ‘Virtual Only Pass’ is not sufficient.”

July 17, 2025 at 7:32 AM
Sofar it doesn’t look good: neurips.cc/FAQ/AuthorRe...
“At least one author of each accepted paper must register for the main conference. A ‘Virtual Only Pass’ is not sufficient.”
“At least one author of each accepted paper must register for the main conference. A ‘Virtual Only Pass’ is not sufficient.”
Reposted by Dávid Komorowicz

WeTransfer just changed their TOS giving themselves permission to train AI on any content you transfer and produce derivative works based on content you transfer that they are allowed to monetize and you are not allowed payment for.
Stop using WeTransfer.
Stop using WeTransfer.
July 14, 2025 at 11:05 PM
WeTransfer just changed their TOS giving themselves permission to train AI on any content you transfer and produce derivative works based on content you transfer that they are allowed to monetize and you are not allowed payment for.
Stop using WeTransfer.
Stop using WeTransfer.
Reposted by Dávid Komorowicz

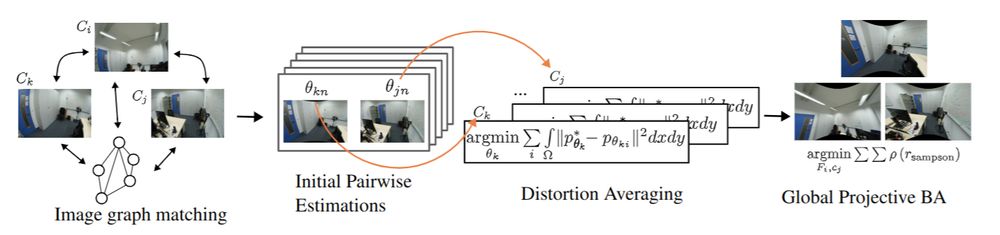
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
July 9, 2025 at 1:54 PM
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Reposted by Dávid Komorowicz

🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
July 9, 2025 at 1:18 PM
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
Reposted by Dávid Komorowicz

We just released COLMAP v3.12, which adds long-awaited, end-to-end support for multi-camera rigs and 360° panoramas 👀 COLMAP just got better at handling your robotics, AR/VR, or 360 data - try it yourself and let us know! github.com/colmap/colma... Kudos to Johannes & team for this great work 🚀


July 1, 2025 at 4:33 PM
We just released COLMAP v3.12, which adds long-awaited, end-to-end support for multi-camera rigs and 360° panoramas 👀 COLMAP just got better at handling your robotics, AR/VR, or 360 data - try it yourself and let us know! github.com/colmap/colma... Kudos to Johannes & team for this great work 🚀
Reposted by Dávid Komorowicz
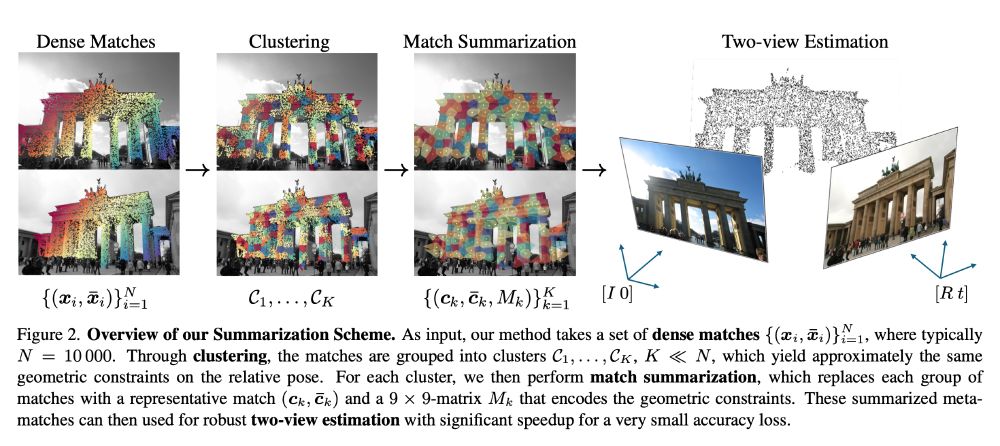
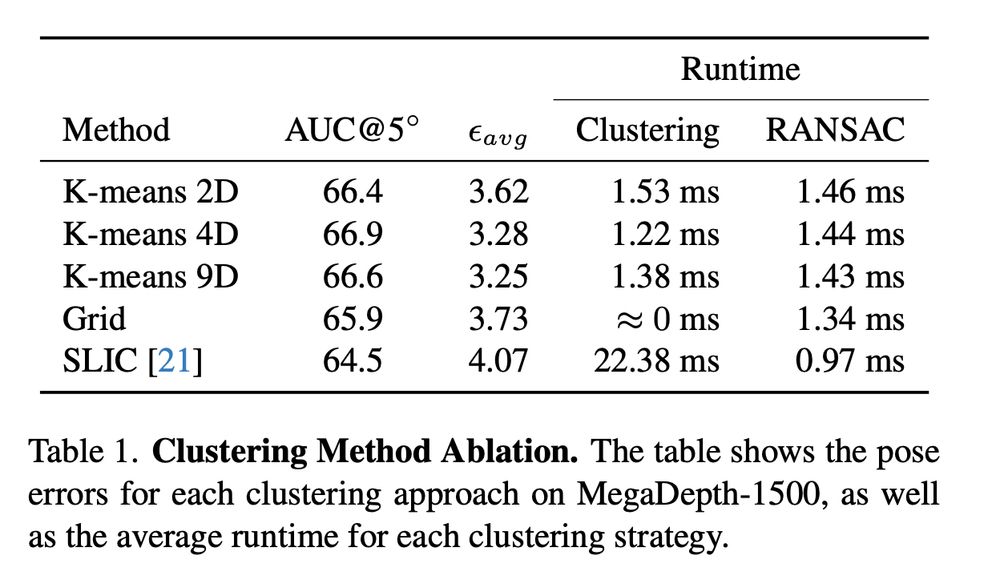
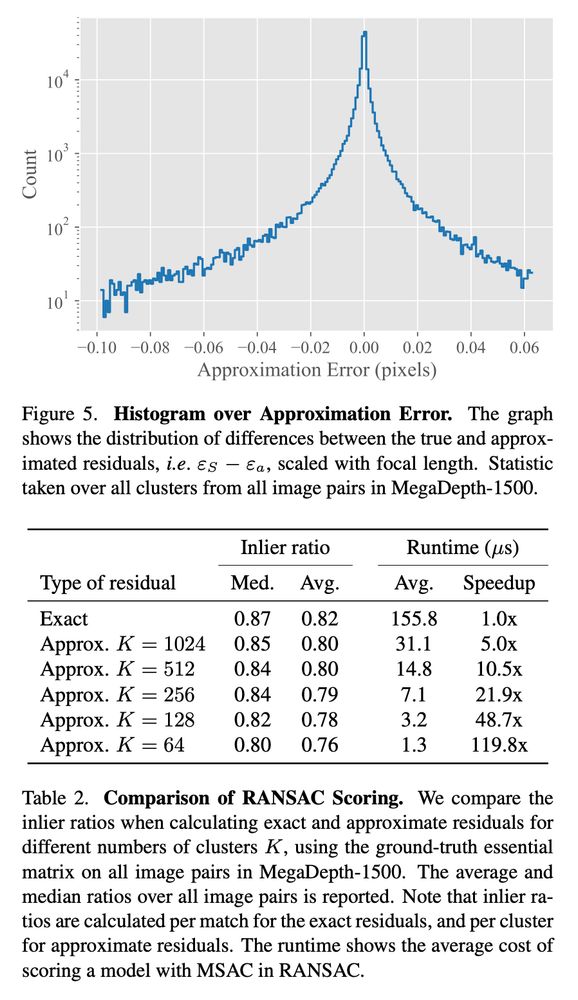
Dense Match Summarization for Faster Two-view Estimation
Jonathan Astermark, Anders Heyden, Viktor Larsson
tl;dr: use clustering to reduce RANSAC time when using dense methods like RoMa.
Kudos for eval on WxBS.
P.S. now the same, but for BA?
arxiv.org/abs/2506.028...
Jonathan Astermark, Anders Heyden, Viktor Larsson
tl;dr: use clustering to reduce RANSAC time when using dense methods like RoMa.
Kudos for eval on WxBS.
P.S. now the same, but for BA?
arxiv.org/abs/2506.028...
June 24, 2025 at 12:22 PM
Dense Match Summarization for Faster Two-view Estimation
Jonathan Astermark, Anders Heyden, Viktor Larsson
tl;dr: use clustering to reduce RANSAC time when using dense methods like RoMa.
Kudos for eval on WxBS.
P.S. now the same, but for BA?
arxiv.org/abs/2506.028...
Jonathan Astermark, Anders Heyden, Viktor Larsson
tl;dr: use clustering to reduce RANSAC time when using dense methods like RoMa.
Kudos for eval on WxBS.
P.S. now the same, but for BA?
arxiv.org/abs/2506.028...
Reposted by Dávid Komorowicz

🤗 I’m excited to share our recent work: TwoSquared: 4D Reconstruction from 2D Image Pairs.
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
April 23, 2025 at 4:48 PM
🤗 I’m excited to share our recent work: TwoSquared: 4D Reconstruction from 2D Image Pairs.
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
🔥 Our method produces geometry, texture-consistent, and physically plausible 4D reconstructions
📰 Check our project page sangluisme.github.io/TwoSquared/
❤️ @ricmarin.bsky.social @dcremers.bsky.social
Reposted by Dávid Komorowicz

Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
June 3, 2025 at 9:27 AM
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Reposted by Dávid Komorowicz

Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
May 13, 2025 at 8:11 AM
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Reposted by Dávid Komorowicz

We also found that this allows the CTM to decide to spend less time thinking on simpler images, thus saving energy. When identifying a gorilla, for example, the CTM’s attention moves from eyes to nose to mouth in a pattern remarkably similar to human visual attention.
May 12, 2025 at 2:42 AM
We also found that this allows the CTM to decide to spend less time thinking on simpler images, thus saving energy. When identifying a gorilla, for example, the CTM’s attention moves from eyes to nose to mouth in a pattern remarkably similar to human visual attention.
Reposted by Dávid Komorowicz
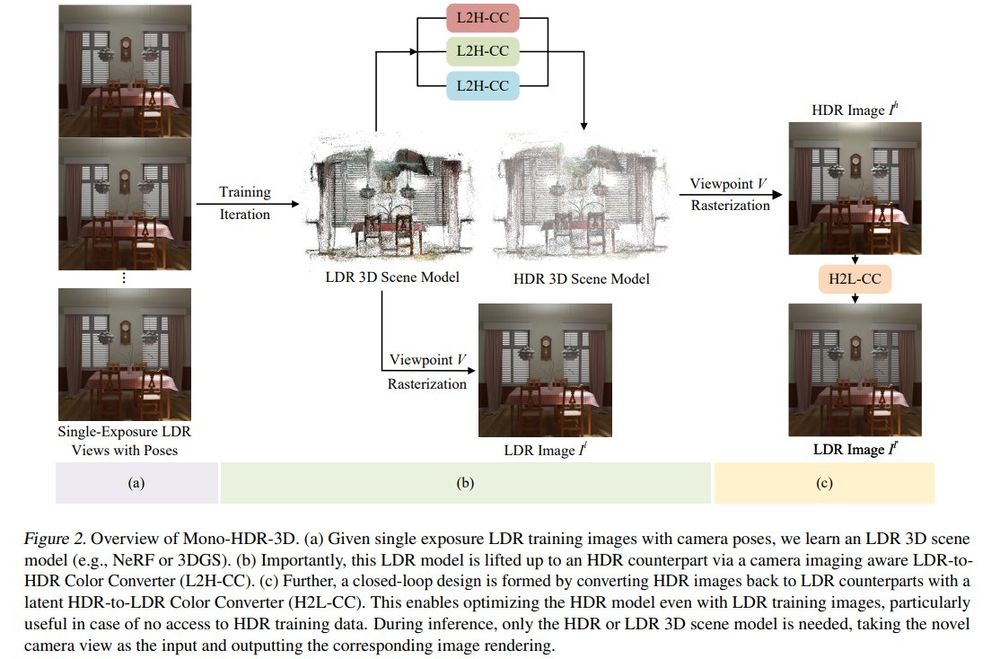
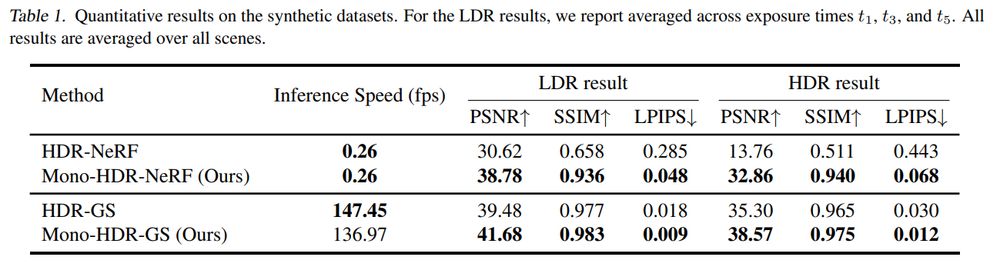
High Dynamic Range Novel View Synthesis with Single Exposure
Kaixuan Zhang, Hu Wang, Minxian Li, Mingwu Ren, Mao Ye, Xiatian Zhu
tl;dr:single exposure LDR images in training; LDR image->model+lift->HDR colors; HDR image->LDR image->additional supervision
arxiv.org/abs/2505.01212
Kaixuan Zhang, Hu Wang, Minxian Li, Mingwu Ren, Mao Ye, Xiatian Zhu
tl;dr:single exposure LDR images in training; LDR image->model+lift->HDR colors; HDR image->LDR image->additional supervision
arxiv.org/abs/2505.01212


May 5, 2025 at 8:52 PM
High Dynamic Range Novel View Synthesis with Single Exposure
Kaixuan Zhang, Hu Wang, Minxian Li, Mingwu Ren, Mao Ye, Xiatian Zhu
tl;dr:single exposure LDR images in training; LDR image->model+lift->HDR colors; HDR image->LDR image->additional supervision
arxiv.org/abs/2505.01212
Kaixuan Zhang, Hu Wang, Minxian Li, Mingwu Ren, Mao Ye, Xiatian Zhu
tl;dr:single exposure LDR images in training; LDR image->model+lift->HDR colors; HDR image->LDR image->additional supervision
arxiv.org/abs/2505.01212
Reposted by Dávid Komorowicz

📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
May 5, 2025 at 1:00 PM
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Reposted by Dávid Komorowicz

8th ZurichCV is on the 29th of April. We have two fantastic speakers: Linus Scheibenreif (ETH Zurich) will talk about self-supervised learning for satellite imagery, and Pascal Chang (Disney Research) will give us a preview of his soon-to-be-published work.
RSVP: www.zurichai.ch/events/zuric...
RSVP: www.zurichai.ch/events/zuric...

ZurichCV #9 | ZurichAI
Linus Scheibenreif (ETH Zurich) will talk about self-supervised learning for satellite imagery, and Pascal Chang (ETH Zurich/Disney Research) will present his recent work (topic to be announced).
www.zurichai.ch
April 20, 2025 at 6:31 AM
8th ZurichCV is on the 29th of April. We have two fantastic speakers: Linus Scheibenreif (ETH Zurich) will talk about self-supervised learning for satellite imagery, and Pascal Chang (Disney Research) will give us a preview of his soon-to-be-published work.
RSVP: www.zurichai.ch/events/zuric...
RSVP: www.zurichai.ch/events/zuric...
Reposted by Dávid Komorowicz

No meal has ever sustained me for more than a few hours, a mere blip on the timeline of my life, 0.001% of my expected lifespan. So therefore I'll no longer be paying at restaurants


April 17, 2025 at 11:53 AM
No meal has ever sustained me for more than a few hours, a mere blip on the timeline of my life, 0.001% of my expected lifespan. So therefore I'll no longer be paying at restaurants
Reposted by Dávid Komorowicz

The Visual Recognition Group at CTU in Prague organizes the 49th Pattern Recognition and Computer Vision Colloquium with D. Karatzas, M. Masana, T. Tommasi, P. Mettes @pascalmettes.bsky.social , E. Brachmann @ericbrachmann.bsky.social and V. Stojnic @stojnicv.xyz
cmp.felk.cvut.cz/colloquium/#...
cmp.felk.cvut.cz/colloquium/#...

April 7, 2025 at 1:57 PM
The Visual Recognition Group at CTU in Prague organizes the 49th Pattern Recognition and Computer Vision Colloquium with D. Karatzas, M. Masana, T. Tommasi, P. Mettes @pascalmettes.bsky.social , E. Brachmann @ericbrachmann.bsky.social and V. Stojnic @stojnicv.xyz
cmp.felk.cvut.cz/colloquium/#...
cmp.felk.cvut.cz/colloquium/#...
Reposted by Dávid Komorowicz

3D Gaussian splatting relies on depth-sorting of splats, which is costly and prone to artifacts (e.g., "popping"). In our latest work, "StochasticSplats", we replace sorted alpha blending by stochastic transparency, an unbiased Monte Carlo estimator from the real-time rendering literature.
April 7, 2025 at 7:57 AM
3D Gaussian splatting relies on depth-sorting of splats, which is costly and prone to artifacts (e.g., "popping"). In our latest work, "StochasticSplats", we replace sorted alpha blending by stochastic transparency, an unbiased Monte Carlo estimator from the real-time rendering literature.
Reposted by Dávid Komorowicz
𝗠𝗖𝗠𝗟 𝗕𝗹𝗼𝗴: Robots & self-driving cars rely on scene understanding, but AI models for understanding these scenes need costly human annotations. Daniel Cremers & his team introduce 🥤🥤 CUPS: a scene-centric unsupervised panoptic segmentation approach to reduce this dependency. 🔗 mcml.ai/news/2025-04...

April 3, 2025 at 9:45 AM
𝗠𝗖𝗠𝗟 𝗕𝗹𝗼𝗴: Robots & self-driving cars rely on scene understanding, but AI models for understanding these scenes need costly human annotations. Daniel Cremers & his team introduce 🥤🥤 CUPS: a scene-centric unsupervised panoptic segmentation approach to reduce this dependency. 🔗 mcml.ai/news/2025-04...