



Dominik Schnaus
@schnaus.bsky.social
PhD student @ TUM with Daniel Cremers
Reposted by Dominik Schnaus

🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
July 9, 2025 at 1:18 PM
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
🌍: visinf.github.io/scenedino/
📃: arxiv.org/abs/2507.06230
🤗: huggingface.co/spaces/jev-a...
@jev-aleks.bsky.social @fwimbauer.bsky.social @olvrhhn.bsky.social @stefanroth.bsky.social @dcremers.bsky.social
Reposted by Dominik Schnaus

The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
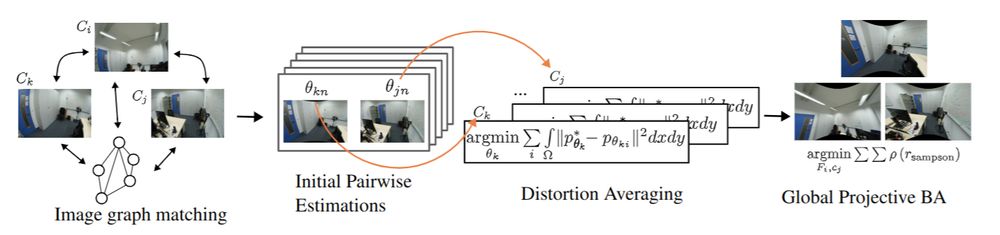
July 9, 2025 at 1:54 PM
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
arxiv.org/abs/2504.16499
github.com/DaniilSinits...
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
June 3, 2025 at 9:27 AM
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Surprisingly, yes!
Our #CVPR2025 paper with @neekans.bsky.social and @dcremers.bsky.social shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️ 1/4
Reposted by Dominik Schnaus

Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
May 13, 2025 at 8:11 AM
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Reposted by Dominik Schnaus
Check out our latest recent #CVPR2025 paper AnyCam, a fast method for pose estimation in casual videos!
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
Code and more info: ⏩ fwmb.github.io/anycam/
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
Code and more info: ⏩ fwmb.github.io/anycam/
April 23, 2025 at 3:52 PM
Check out our latest recent #CVPR2025 paper AnyCam, a fast method for pose estimation in casual videos!
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
Code and more info: ⏩ fwmb.github.io/anycam/
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
Code and more info: ⏩ fwmb.github.io/anycam/
Reposted by Dominik Schnaus

We are thrilled to have 12 papers accepted to #CVPR2025. Thanks to all our students and collaborators for this great achievement!
For more details check out cvg.cit.tum.de
For more details check out cvg.cit.tum.de

March 13, 2025 at 1:11 PM
We are thrilled to have 12 papers accepted to #CVPR2025. Thanks to all our students and collaborators for this great achievement!
For more details check out cvg.cit.tum.de
For more details check out cvg.cit.tum.de
Reposted by Dominik Schnaus
Indeed - everyone had a blast - thank you all for the great talks, discussions and Ski/snowboarding!

This week we had our winter retreat jointly with Daniel Cremer's group in Montafon, Austria. 46 talks, 100 Km of slopes and night sledding with some occasionally lost and found. It has been fun!




January 16, 2025 at 5:56 PM
Indeed - everyone had a blast - thank you all for the great talks, discussions and Ski/snowboarding!