




Caleb Ziems
@calebziems.com
PhD student at Stanford NLP. Working on Social NLP and CSS. Previously at GaTech, Meta AI, Emory.
📍Palo Alto, CA
🔗 calebziems.com
📍Palo Alto, CA
🔗 calebziems.com
Thanks to many @stanfordnlp.bsky.social members for feedback! @juliakruk.bsky.social @yanzhe.bsky.social @myra.bsky.social @jaredlcm.bsky.social
May be of interest to @paul-rottger.bsky.social @monadiab77.bsky.social @vinodkpg.bsky.social @dbamman.bsky.social @davidjurgens.bsky.social and you
May be of interest to @paul-rottger.bsky.social @monadiab77.bsky.social @vinodkpg.bsky.social @dbamman.bsky.social @davidjurgens.bsky.social and you
November 4, 2025 at 6:04 PM
Thanks to many @stanfordnlp.bsky.social members for feedback! @juliakruk.bsky.social @yanzhe.bsky.social @myra.bsky.social @jaredlcm.bsky.social
May be of interest to @paul-rottger.bsky.social @monadiab77.bsky.social @vinodkpg.bsky.social @dbamman.bsky.social @davidjurgens.bsky.social and you
May be of interest to @paul-rottger.bsky.social @monadiab77.bsky.social @vinodkpg.bsky.social @dbamman.bsky.social @davidjurgens.bsky.social and you
Our implementation of Culture Cartography is based on Farsight (Wang et al., 2024).
This was an interdisciplinary effort across computer science (@diyiyang.bsky.social, @williamheld.com, Jane Yu) and sociology (David Grusky and Amir Goldberg), and the research process taught me so much!
This was an interdisciplinary effort across computer science (@diyiyang.bsky.social, @williamheld.com, Jane Yu) and sociology (David Grusky and Amir Goldberg), and the research process taught me so much!

November 4, 2025 at 5:38 PM
Our implementation of Culture Cartography is based on Farsight (Wang et al., 2024).
This was an interdisciplinary effort across computer science (@diyiyang.bsky.social, @williamheld.com, Jane Yu) and sociology (David Grusky and Amir Goldberg), and the research process taught me so much!
This was an interdisciplinary effort across computer science (@diyiyang.bsky.social, @williamheld.com, Jane Yu) and sociology (David Grusky and Amir Goldberg), and the research process taught me so much!
Finally, Culture Cartography is aligned with prior notions of culture evals in our field.
We observe positive transfer performance from Cartography to two leading benchmarks: BLEnD (Myung et al., 2024) and CulturalBench (Chiu et al., 2024).
We observe positive transfer performance from Cartography to two leading benchmarks: BLEnD (Myung et al., 2024) and CulturalBench (Chiu et al., 2024).

November 4, 2025 at 5:35 PM
Finally, Culture Cartography is aligned with prior notions of culture evals in our field.
We observe positive transfer performance from Cartography to two leading benchmarks: BLEnD (Myung et al., 2024) and CulturalBench (Chiu et al., 2024).
We observe positive transfer performance from Cartography to two leading benchmarks: BLEnD (Myung et al., 2024) and CulturalBench (Chiu et al., 2024).
Compared to knowledge extraction, Culture Cartography is less prone to test-set contamination.
We evaluate GPT-4o with and without search and find no significant difference in their recall on Cartography data.
Culture Cartography is "Google proof" since search doesn't help.
We evaluate GPT-4o with and without search and find no significant difference in their recall on Cartography data.
Culture Cartography is "Google proof" since search doesn't help.

November 4, 2025 at 5:34 PM
Compared to knowledge extraction, Culture Cartography is less prone to test-set contamination.
We evaluate GPT-4o with and without search and find no significant difference in their recall on Cartography data.
Culture Cartography is "Google proof" since search doesn't help.
We evaluate GPT-4o with and without search and find no significant difference in their recall on Cartography data.
Culture Cartography is "Google proof" since search doesn't help.
Compared to traditional annotation, Culture Cartography more often elicits knowledge that is unknown to LLMs.
Qwen-2 72 B recalls 21% less Cartography data than it recalls traditional data (p < .0001)
Even a strong reasoning model (R1) is challenged more by our data.
Qwen-2 72 B recalls 21% less Cartography data than it recalls traditional data (p < .0001)
Even a strong reasoning model (R1) is challenged more by our data.

November 4, 2025 at 5:33 PM
Compared to traditional annotation, Culture Cartography more often elicits knowledge that is unknown to LLMs.
Qwen-2 72 B recalls 21% less Cartography data than it recalls traditional data (p < .0001)
Even a strong reasoning model (R1) is challenged more by our data.
Qwen-2 72 B recalls 21% less Cartography data than it recalls traditional data (p < .0001)
Even a strong reasoning model (R1) is challenged more by our data.
We propose a mixed-initiative method called Culture Cartography.
And to find challenging questions, we let the LLM steer towards topics it has low confidence in.
To find culturally-representative knowledge, we let the human steer towards what they find most salient.
And to find challenging questions, we let the LLM steer towards topics it has low confidence in.
To find culturally-representative knowledge, we let the human steer towards what they find most salient.

November 4, 2025 at 5:33 PM
We propose a mixed-initiative method called Culture Cartography.
And to find challenging questions, we let the LLM steer towards topics it has low confidence in.
To find culturally-representative knowledge, we let the human steer towards what they find most salient.
And to find challenging questions, we let the LLM steer towards topics it has low confidence in.
To find culturally-representative knowledge, we let the human steer towards what they find most salient.
Other benchmarks use knowledge extracted from the rich cultural artifacts that humans actively produce on the web.
Still this is a single-initiative process.
Researchers can’t steer the distribution towards questions of interest (i.e., those that challenge LLMs).
Still this is a single-initiative process.
Researchers can’t steer the distribution towards questions of interest (i.e., those that challenge LLMs).

November 4, 2025 at 5:32 PM
Other benchmarks use knowledge extracted from the rich cultural artifacts that humans actively produce on the web.
Still this is a single-initiative process.
Researchers can’t steer the distribution towards questions of interest (i.e., those that challenge LLMs).
Still this is a single-initiative process.
Researchers can’t steer the distribution towards questions of interest (i.e., those that challenge LLMs).
How are prior benchmarks constructed?
In traditional annotation, the researcher picks some questions and the annotator passively provides ground truth answers.
This is single-initiative.
Annotators don't steer the process, so their interests and culture may not be represented.
In traditional annotation, the researcher picks some questions and the annotator passively provides ground truth answers.
This is single-initiative.
Annotators don't steer the process, so their interests and culture may not be represented.

November 4, 2025 at 5:32 PM
How are prior benchmarks constructed?
In traditional annotation, the researcher picks some questions and the annotator passively provides ground truth answers.
This is single-initiative.
Annotators don't steer the process, so their interests and culture may not be represented.
In traditional annotation, the researcher picks some questions and the annotator passively provides ground truth answers.
This is single-initiative.
Annotators don't steer the process, so their interests and culture may not be represented.
Can we map out gaps in LLMs’ cultural knowledge?
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672

November 4, 2025 at 5:31 PM
Can we map out gaps in LLMs’ cultural knowledge?
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Reposted by Caleb Ziems

AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.

October 3, 2025 at 10:53 PM
AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.
Reposted by Caleb Ziems

I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419

June 23, 2025 at 2:45 PM
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419
Reposted by Caleb Ziems

AI companions aren’t science fiction anymore 🤖💬❤️
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.

June 18, 2025 at 4:27 PM
AI companions aren’t science fiction anymore 🤖💬❤️
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Reposted by Caleb Ziems

Introducing CAVA: The Comprehensive Assessment for Voice Assistants
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
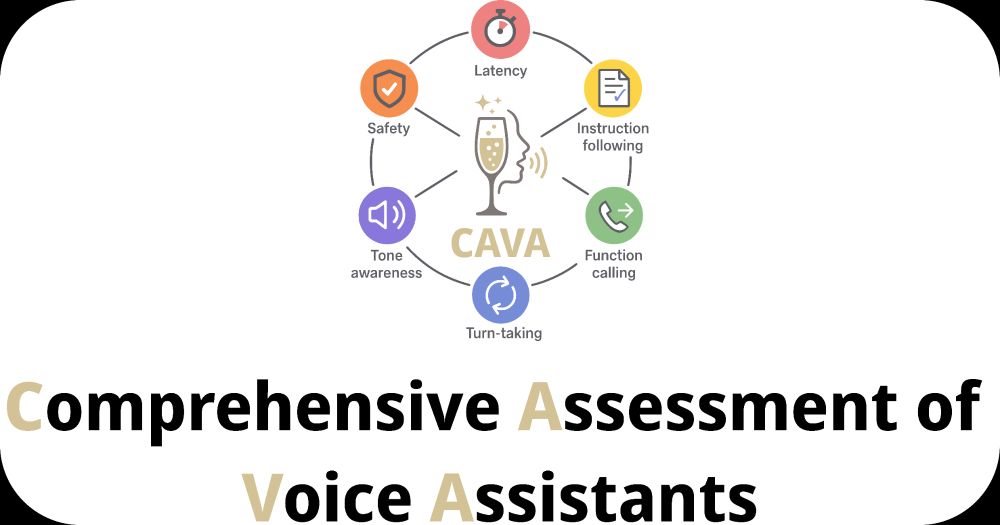
Comprehensive Assessment for Voice Assistants
CAVA is a new benchmark for assessing how well Large Audio Models support voice assistant capabilities.
TalkArena.org
May 7, 2025 at 4:15 PM
Introducing CAVA: The Comprehensive Assessment for Voice Assistants
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
Reposted by Caleb Ziems

Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)

March 6, 2025 at 7:49 PM
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
March 4, 2025 at 4:44 AM
EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
Reposted by Caleb Ziems

There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n

February 18, 2025 at 8:45 PM
There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
Reposted by Caleb Ziems

LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)

January 17, 2025 at 5:44 PM
LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Reposted by Caleb Ziems

Bill Labov died this morning. I'm not coherent enough to talk about how important and influential and brilliant he was. I am very sad.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
December 18, 2024 at 2:08 AM
Bill Labov died this morning. I'm not coherent enough to talk about how important and influential and brilliant he was. I am very sad.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
Reposted by Caleb Ziems
With an increasing number of Large *Audio* Models 🔊, which one do users like the most?
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)

December 10, 2024 at 12:01 AM
With an increasing number of Large *Audio* Models 🔊, which one do users like the most?
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Maybe some starter packs for the Dyirbal noun classes?
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)

Some starter packs I plan to do when I get around to it

November 24, 2024 at 5:53 PM
Maybe some starter packs for the Dyirbal noun classes?
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
Reposted by Caleb Ziems

Hi Bluesky! You get to be the very first internet people to see my standup comedy debut. Because I know you’ll be nicer to me than the 12 year olds on TikTok. youtu.be/KqL2ahOvAgg?...

AI is not the GOAT. (Uh oh, your professor is attempting stand up comedy.)
YouTube video by Casey Fiesler
youtu.be
November 23, 2024 at 6:52 PM
Hi Bluesky! You get to be the very first internet people to see my standup comedy debut. Because I know you’ll be nicer to me than the 12 year olds on TikTok. youtu.be/KqL2ahOvAgg?...
Reposted by Caleb Ziems

I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
November 23, 2024 at 7:54 PM
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
@butanium.bsky.social I nominate @aryaman.io
November 19, 2024 at 4:57 PM
@butanium.bsky.social I nominate @aryaman.io