




Amir Mesbah
@amirmesbah.bsky.social
Reposted by Amir Mesbah

📣 #ICML tutorials: We want to know what *you* would like to learn. This year, Adam White and I are calling for nominations of topics and/or presenters.
Until December 7th, you can send us your suggestions, and we will use them to shape the program.
icml.cc/Conferences/...
Until December 7th, you can send us your suggestions, and we will use them to shape the program.
icml.cc/Conferences/...
ICML 20256 Call For Tutorials
icml.cc
November 12, 2025 at 8:12 AM
📣 #ICML tutorials: We want to know what *you* would like to learn. This year, Adam White and I are calling for nominations of topics and/or presenters.
Until December 7th, you can send us your suggestions, and we will use them to shape the program.
icml.cc/Conferences/...
Until December 7th, you can send us your suggestions, and we will use them to shape the program.
icml.cc/Conferences/...
Reposted by Amir Mesbah

🚨The Formalism-Implementation Gap in RL research🚨
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X

October 28, 2025 at 1:56 PM
🚨The Formalism-Implementation Gap in RL research🚨
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
Reposted by Amir Mesbah

I am happy to share that our paper "Put CASH on Bandits: A Max K-Armed Problem for Automated Machine Learning" has been accepted at NeurIPS 2025!
Endless thanks to my amazing co-authors @claireve.bsky.social and @keggensperger.bsky.social
📄 Read it on arXiv: arxiv.org/abs/2505.05226
(1/3)
Endless thanks to my amazing co-authors @claireve.bsky.social and @keggensperger.bsky.social
📄 Read it on arXiv: arxiv.org/abs/2505.05226
(1/3)

Put CASH on Bandits: A Max K-Armed Problem for Automated Machine Learning
The Combined Algorithm Selection and Hyperparameter optimization (CASH) is a challenging resource allocation problem in the field of AutoML. We propose MaxUCB, a max $k$-armed bandit method to trade o...
arxiv.org
October 6, 2025 at 4:54 PM
I am happy to share that our paper "Put CASH on Bandits: A Max K-Armed Problem for Automated Machine Learning" has been accepted at NeurIPS 2025!
Endless thanks to my amazing co-authors @claireve.bsky.social and @keggensperger.bsky.social
📄 Read it on arXiv: arxiv.org/abs/2505.05226
(1/3)
Endless thanks to my amazing co-authors @claireve.bsky.social and @keggensperger.bsky.social
📄 Read it on arXiv: arxiv.org/abs/2505.05226
(1/3)
Reposted by Amir Mesbah

cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!

a close up of a sad cat with the words pleeeaasse written below it
ALT: a close up of a sad cat with the words pleeeaasse written below it
media.tenor.com
October 2, 2025 at 9:34 PM
cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
Reposted by Amir Mesbah
Reposted by Amir Mesbah


August 3, 2025 at 8:14 PM
What if all mathematicians had great visualization skills, tools, and public notes!
July 31, 2025 at 4:22 PM
What if all mathematicians had great visualization skills, tools, and public notes!
Reposted by Amir Mesbah
Onno and I will be presenting our poster at # W1005 tomorrow (Wed) morning.
He made a great thread about it, come chat with us about POMDP theory :)
He made a great thread about it, come chat with us about POMDP theory :)

I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
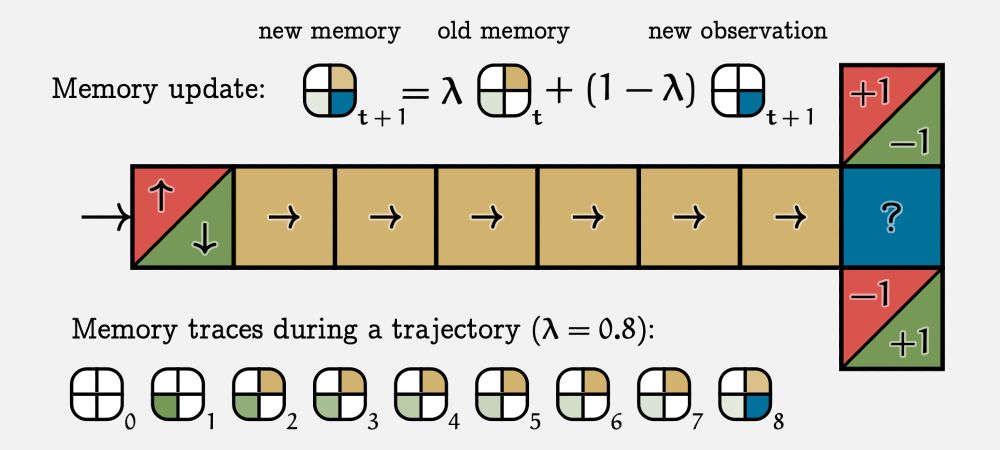
July 16, 2025 at 3:45 AM
Onno and I will be presenting our poster at # W1005 tomorrow (Wed) morning.
He made a great thread about it, come chat with us about POMDP theory :)
He made a great thread about it, come chat with us about POMDP theory :)
Reposted by Amir Mesbah
I will not be at #ICML2025 this year, but 3 of my PhD students at 🤖 Adage (Adaptive Agents Lab) 🤖 are, presenting 3 papers.
⭐ Avery Ma
⭐ Claas Voelcker (cvoelcker.bsky.social)
⭐ Tyler Kastner
Meet them to talk about Model-based RL, Distributional RL, and Jailbreaking LLMs.
⭐ Avery Ma
⭐ Claas Voelcker (cvoelcker.bsky.social)
⭐ Tyler Kastner
Meet them to talk about Model-based RL, Distributional RL, and Jailbreaking LLMs.
July 14, 2025 at 6:54 PM
I will not be at #ICML2025 this year, but 3 of my PhD students at 🤖 Adage (Adaptive Agents Lab) 🤖 are, presenting 3 papers.
⭐ Avery Ma
⭐ Claas Voelcker (cvoelcker.bsky.social)
⭐ Tyler Kastner
Meet them to talk about Model-based RL, Distributional RL, and Jailbreaking LLMs.
⭐ Avery Ma
⭐ Claas Voelcker (cvoelcker.bsky.social)
⭐ Tyler Kastner
Meet them to talk about Model-based RL, Distributional RL, and Jailbreaking LLMs.
Reposted by Amir Mesbah

Levine's take on the success of LLMs compared to video models is interesting, but I'll expand on how efforts toward AI could take two different paths, and why I think AI and NeuroAI could take different approaches moving forward. 🧵
🧠🤖 #MLSky
🧠🤖 #MLSky
AI may still need some neuroscience:
"AI systems will not acquire the flexibility and adaptability of human intelligence until they can actually learn like humans do, shining brightly with their own light rather than observing a shadow from ours."
🧠🤖
sergeylevine.substack.com/p/language-m...
"AI systems will not acquire the flexibility and adaptability of human intelligence until they can actually learn like humans do, shining brightly with their own light rather than observing a shadow from ours."
🧠🤖
sergeylevine.substack.com/p/language-m...

Language Models in Plato's Cave
Why language models succeeded where video models failed, and what that teaches us about AI
sergeylevine.substack.com
June 12, 2025 at 2:30 PM
Levine's take on the success of LLMs compared to video models is interesting, but I'll expand on how efforts toward AI could take two different paths, and why I think AI and NeuroAI could take different approaches moving forward. 🧵
🧠🤖 #MLSky
🧠🤖 #MLSky
Reposted by Amir Mesbah

Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)

May 14, 2025 at 12:53 PM
Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Reposted by Amir Mesbah

cleanrl is amazing (github.com/vwxyzjn/clea...) and its structure makes sense for teaching but an actual research codebase should not inherit this style! you do not want this amount of code duplication

GitHub - vwxyzjn/cleanrl: High-quality single file implementation of Deep Reinforcement Learning algorithms with research-friendly features (PPO, DQN, C51, DDPG, TD3, SAC, PPG)
High-quality single file implementation of Deep Reinforcement Learning algorithms with research-friendly features (PPO, DQN, C51, DDPG, TD3, SAC, PPG) - vwxyzjn/cleanrl
github.com
May 11, 2025 at 8:01 PM
cleanrl is amazing (github.com/vwxyzjn/clea...) and its structure makes sense for teaching but an actual research codebase should not inherit this style! you do not want this amount of code duplication
Reposted by Amir Mesbah

rlhfbook also available on arxiv for SEO 😀 happy friday
arxiv.org/abs/2504.12501
arxiv.org/abs/2504.12501

Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) has become an important technical and storytelling tool to deploy the latest machine learning systems. In this book, we hope to give a gentle…
arxiv.org
April 18, 2025 at 4:07 PM
rlhfbook also available on arxiv for SEO 😀 happy friday
arxiv.org/abs/2504.12501
arxiv.org/abs/2504.12501
Reposted by Amir Mesbah

Recorded a recent "talk" / rant about RL fine-tuning of LLMs for a guest lecture in Stanford CSE234: youtube.com/watch?v=NTSY.... Covers some of my lab's recent work on personalized RLHF, as well as some mild Schmidhubering about my own early contributions to this space

Reinforcement Learning (RL) for LLMs
YouTube video by Natasha Jaques
youtube.com
March 27, 2025 at 9:32 PM
Recorded a recent "talk" / rant about RL fine-tuning of LLMs for a guest lecture in Stanford CSE234: youtube.com/watch?v=NTSY.... Covers some of my lab's recent work on personalized RLHF, as well as some mild Schmidhubering about my own early contributions to this space
Reposted by Amir Mesbah

PQN puts Q-learning back on the map and now comes with a blog post + Colab demo! Also, congrats to the team for the spotlight at #ICLR2025

PQN blog 3/3 👉take a look at Matteo's 5-minute blog covering PQN’s key features, plus a Colab demo with JAX & PyTorch implementations mttga.github.io/posts/pqn/
🔎 For a deeper dive into the theory:
blog.foersterlab.com/fixing-td-pa...
blog.foersterlab.com/fixing-td-pa...
See you in Singapore! 🇸🇬
🔎 For a deeper dive into the theory:
blog.foersterlab.com/fixing-td-pa...
blog.foersterlab.com/fixing-td-pa...
See you in Singapore! 🇸🇬
Simplifying Deep Temporal Difference Learning
A modern implementation of Deep Q-Network without target networks and replay buffers.
mttga.github.io
March 20, 2025 at 11:51 AM
PQN puts Q-learning back on the map and now comes with a blog post + Colab demo! Also, congrats to the team for the spotlight at #ICLR2025
Reposted by Amir Mesbah
I’ve put together a short list of opportunities for early career academics willing to come to Europe: www.cvernade.com/miscellaneou...
This mostly covers France and Germany for now but I’m willing to extend it. I build on @ellis.eu resources and my own knowledge of these systems.
This mostly covers France and Germany for now but I’m willing to extend it. I build on @ellis.eu resources and my own knowledge of these systems.

Claire Vernade - European career opportunities
European Academic Career Opportunities in 2025
www.cvernade.com
March 11, 2025 at 9:19 AM
I’ve put together a short list of opportunities for early career academics willing to come to Europe: www.cvernade.com/miscellaneou...
This mostly covers France and Germany for now but I’m willing to extend it. I build on @ellis.eu resources and my own knowledge of these systems.
This mostly covers France and Germany for now but I’m willing to extend it. I build on @ellis.eu resources and my own knowledge of these systems.
Reposted by Amir Mesbah

Reposted by Amir Mesbah
First 11 chapters of RLHF Book have v0 draft done. Should be useful now.
Next:
* Crafting more blog content into future topics,
* DPO+ chapter,
* Meeting with publishers to get wheels turning on physical copies,
* Cleaning & cohesiveness
rlhfbook.com
Next:
* Crafting more blog content into future topics,
* DPO+ chapter,
* Meeting with publishers to get wheels turning on physical copies,
* Cleaning & cohesiveness
rlhfbook.com

February 26, 2025 at 4:35 PM
First 11 chapters of RLHF Book have v0 draft done. Should be useful now.
Next:
* Crafting more blog content into future topics,
* DPO+ chapter,
* Meeting with publishers to get wheels turning on physical copies,
* Cleaning & cohesiveness
rlhfbook.com
Next:
* Crafting more blog content into future topics,
* DPO+ chapter,
* Meeting with publishers to get wheels turning on physical copies,
* Cleaning & cohesiveness
rlhfbook.com
Reposted by Amir Mesbah

🚨 Neuromatch Academy Course Applications are OPEN for 2025!! 🚨
Get your application in early to be a student or teaching assistant for this year’s courses!
Applications are due Sunday, March 23.
Apply & learn more: neuromatch.io/courses/
#mlsky #compneurosky #ai #climatesolutions #ScienceEdu 🧪
Get your application in early to be a student or teaching assistant for this year’s courses!
Applications are due Sunday, March 23.
Apply & learn more: neuromatch.io/courses/
#mlsky #compneurosky #ai #climatesolutions #ScienceEdu 🧪

February 24, 2025 at 5:58 PM
🚨 Neuromatch Academy Course Applications are OPEN for 2025!! 🚨
Get your application in early to be a student or teaching assistant for this year’s courses!
Applications are due Sunday, March 23.
Apply & learn more: neuromatch.io/courses/
#mlsky #compneurosky #ai #climatesolutions #ScienceEdu 🧪
Get your application in early to be a student or teaching assistant for this year’s courses!
Applications are due Sunday, March 23.
Apply & learn more: neuromatch.io/courses/
#mlsky #compneurosky #ai #climatesolutions #ScienceEdu 🧪
Reposted by Amir Mesbah

2014 GoogLeNet: The best image classifier was only trainable using weeks of Google's custom infrastructure.
2018 ResNet: A more accurate model is trainable in a 1/2 hour on a single GPU.
What stops this from happening for LLMs?
2018 ResNet: A more accurate model is trainable in a 1/2 hour on a single GPU.
What stops this from happening for LLMs?
Machine learning progresses when complicated breakthroughs are soon dramatically simplified as people figure out the salient parts.
What a world we're in where this well-trodden pattern rocks financial markets and escalates geopolitical conflict.
What a world we're in where this well-trodden pattern rocks financial markets and escalates geopolitical conflict.
January 27, 2025 at 3:16 PM
2014 GoogLeNet: The best image classifier was only trainable using weeks of Google's custom infrastructure.
2018 ResNet: A more accurate model is trainable in a 1/2 hour on a single GPU.
What stops this from happening for LLMs?
2018 ResNet: A more accurate model is trainable in a 1/2 hour on a single GPU.
What stops this from happening for LLMs?
Reposted by Amir Mesbah

I am teaching a class on #FoundationalModels for #robotics and Scaling #DeepRL algorithms. This class expands on last year's class and my generalist robotics policies tutorial and code. I plan to share the lectures and code assignments. Starting with the first lectures below.

January 19, 2025 at 7:14 PM
I am teaching a class on #FoundationalModels for #robotics and Scaling #DeepRL algorithms. This class expands on last year's class and my generalist robotics policies tutorial and code. I plan to share the lectures and code assignments. Starting with the first lectures below.
I wonder why ML conferences insist on uploading workshop videos on SlideShare while they can use YouTube and the benefits of monetization.
Talks on SlideShare are really hard to track!
Talks on SlideShare are really hard to track!
January 18, 2025 at 11:17 AM
I wonder why ML conferences insist on uploading workshop videos on SlideShare while they can use YouTube and the benefits of monetization.
Talks on SlideShare are really hard to track!
Talks on SlideShare are really hard to track!
Reposted by Amir Mesbah
i was recently asked to provide 4 "desert island" RL papers.
if i were stuck on a desert island i'd hope to have something better to read than #RL papers... but anyway, here's a thread with my choices, maybe you can read them on your flight to @neuripsconf.bsky.social #NeurIPS2024 .
Enjoy!
if i were stuck on a desert island i'd hope to have something better to read than #RL papers... but anyway, here's a thread with my choices, maybe you can read them on your flight to @neuripsconf.bsky.social #NeurIPS2024 .
Enjoy!
December 6, 2024 at 8:56 PM
i was recently asked to provide 4 "desert island" RL papers.
if i were stuck on a desert island i'd hope to have something better to read than #RL papers... but anyway, here's a thread with my choices, maybe you can read them on your flight to @neuripsconf.bsky.social #NeurIPS2024 .
Enjoy!
if i were stuck on a desert island i'd hope to have something better to read than #RL papers... but anyway, here's a thread with my choices, maybe you can read them on your flight to @neuripsconf.bsky.social #NeurIPS2024 .
Enjoy!
Reposted by Amir Mesbah
If you're an RL researcher or RL adjacent, pipe up to make sure I've added you here!
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg
November 9, 2024 at 4:42 PM
If you're an RL researcher or RL adjacent, pipe up to make sure I've added you here!
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg