




valeo.ai
@valeoai.bsky.social
We are a research team on artificial intelligence for automotive applications working toward assisted and autonomous driving.
--> https://valeoai.github.io/ <--
--> https://valeoai.github.io/ <--
Privileged to the diffusion master @nicolasdufour.bsky.social give to our team (full house) a tour of his excellent works in data and compute efficient diffusion models and a sneak preview of his latest MIRO work.
Check it out 👌
Check it out 👌




October 31, 2025 at 7:28 PM
Privileged to the diffusion master @nicolasdufour.bsky.social give to our team (full house) a tour of his excellent works in data and compute efficient diffusion models and a sneak preview of his latest MIRO work.
Check it out 👌
Check it out 👌
Analyzing Fine-tuning Representation Shift for Multimodal LLMs Steering Alignment
tl;dr: a new method for understanding and controlling how MLLMs adapt during fine-tuning
by: P. Khayatan, M. Shukor, J. Parekh, A. Dapogny, @matthieucord.bsky.social
📄: arxiv.org/abs/2501.03012
tl;dr: a new method for understanding and controlling how MLLMs adapt during fine-tuning
by: P. Khayatan, M. Shukor, J. Parekh, A. Dapogny, @matthieucord.bsky.social
📄: arxiv.org/abs/2501.03012

October 17, 2025 at 10:31 PM
Analyzing Fine-tuning Representation Shift for Multimodal LLMs Steering Alignment
tl;dr: a new method for understanding and controlling how MLLMs adapt during fine-tuning
by: P. Khayatan, M. Shukor, J. Parekh, A. Dapogny, @matthieucord.bsky.social
📄: arxiv.org/abs/2501.03012
tl;dr: a new method for understanding and controlling how MLLMs adapt during fine-tuning
by: P. Khayatan, M. Shukor, J. Parekh, A. Dapogny, @matthieucord.bsky.social
📄: arxiv.org/abs/2501.03012
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
tl;dr: a simple trick to boost open-vocabulary semantic segmentation by identifying class expert prompt templates
by: Y. Benigmim, M. Fahes, @tuanhungvu.bsky.social, @abursuc.bsky.social, R. de Charette.
📄: arxiv.org/abs/2504.10487
tl;dr: a simple trick to boost open-vocabulary semantic segmentation by identifying class expert prompt templates
by: Y. Benigmim, M. Fahes, @tuanhungvu.bsky.social, @abursuc.bsky.social, R. de Charette.
📄: arxiv.org/abs/2504.10487

October 17, 2025 at 10:30 PM
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
tl;dr: a simple trick to boost open-vocabulary semantic segmentation by identifying class expert prompt templates
by: Y. Benigmim, M. Fahes, @tuanhungvu.bsky.social, @abursuc.bsky.social, R. de Charette.
📄: arxiv.org/abs/2504.10487
tl;dr: a simple trick to boost open-vocabulary semantic segmentation by identifying class expert prompt templates
by: Y. Benigmim, M. Fahes, @tuanhungvu.bsky.social, @abursuc.bsky.social, R. de Charette.
📄: arxiv.org/abs/2504.10487
MoSiC: Optimal-Transport Motion Trajectories for Dense Self-Supervised Learning
tl;dr: a self-supervised learning of temporally consistent representations from video w/ motion cues
by: M. Salehi, S. Venkataramanan, I. Simion, E. Gavves, @cgmsnoek.bsky.social, Y. Asano
📄: arxiv.org/abs/2506.08694
tl;dr: a self-supervised learning of temporally consistent representations from video w/ motion cues
by: M. Salehi, S. Venkataramanan, I. Simion, E. Gavves, @cgmsnoek.bsky.social, Y. Asano
📄: arxiv.org/abs/2506.08694

October 17, 2025 at 10:30 PM
MoSiC: Optimal-Transport Motion Trajectories for Dense Self-Supervised Learning
tl;dr: a self-supervised learning of temporally consistent representations from video w/ motion cues
by: M. Salehi, S. Venkataramanan, I. Simion, E. Gavves, @cgmsnoek.bsky.social, Y. Asano
📄: arxiv.org/abs/2506.08694
tl;dr: a self-supervised learning of temporally consistent representations from video w/ motion cues
by: M. Salehi, S. Venkataramanan, I. Simion, E. Gavves, @cgmsnoek.bsky.social, Y. Asano
📄: arxiv.org/abs/2506.08694
GaussRender: Learning 3D Occupancy with Gaussian Rendering
tl;dr: a module for 3D occupancy learning that enforces 2D-3D consistency through differentiable Gaussian rendering
by: L. Chambon, @eloizablocki.bsky.social, @alexandreboulch.bsky.social, M. Chen, M. Cord
📄: arxiv.org/abs/2502.05040
tl;dr: a module for 3D occupancy learning that enforces 2D-3D consistency through differentiable Gaussian rendering
by: L. Chambon, @eloizablocki.bsky.social, @alexandreboulch.bsky.social, M. Chen, M. Cord
📄: arxiv.org/abs/2502.05040

October 17, 2025 at 10:29 PM
GaussRender: Learning 3D Occupancy with Gaussian Rendering
tl;dr: a module for 3D occupancy learning that enforces 2D-3D consistency through differentiable Gaussian rendering
by: L. Chambon, @eloizablocki.bsky.social, @alexandreboulch.bsky.social, M. Chen, M. Cord
📄: arxiv.org/abs/2502.05040
tl;dr: a module for 3D occupancy learning that enforces 2D-3D consistency through differentiable Gaussian rendering
by: L. Chambon, @eloizablocki.bsky.social, @alexandreboulch.bsky.social, M. Chen, M. Cord
📄: arxiv.org/abs/2502.05040
Our recent research will be presented at @iccv.bsky.social! #ICCV2025
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...

October 17, 2025 at 10:10 PM
Our recent research will be presented at @iccv.bsky.social! #ICCV2025
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
“Has anyone heard about DUSt3R?”
All hands and hearts up in the room.
Honored to welcome @gabrielacsurka.bsky.social today to speak about the amazing work @naverlabseurope.bsky.social towards 3D Foundation Models
All hands and hearts up in the room.
Honored to welcome @gabrielacsurka.bsky.social today to speak about the amazing work @naverlabseurope.bsky.social towards 3D Foundation Models




October 6, 2025 at 12:38 PM
“Has anyone heard about DUSt3R?”
All hands and hearts up in the room.
Honored to welcome @gabrielacsurka.bsky.social today to speak about the amazing work @naverlabseurope.bsky.social towards 3D Foundation Models
All hands and hearts up in the room.
Honored to welcome @gabrielacsurka.bsky.social today to speak about the amazing work @naverlabseurope.bsky.social towards 3D Foundation Models
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀

October 6, 2025 at 12:09 PM
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
PPT: Pretraining with Pseudo-Labeled Trajectories for Motion Forecasting
📄 Paper: arxiv.org/abs/2412.06491
by Y. Xu, @yuanyinnn.bsky.social, @eloizablocki.bsky.social, @tuanhungvu.bsky.social , @alexandreboulch.bsky.social, M. Cord
📄 Paper: arxiv.org/abs/2412.06491
by Y. Xu, @yuanyinnn.bsky.social, @eloizablocki.bsky.social, @tuanhungvu.bsky.social , @alexandreboulch.bsky.social, M. Cord

September 24, 2025 at 5:11 PM
PPT: Pretraining with Pseudo-Labeled Trajectories for Motion Forecasting
📄 Paper: arxiv.org/abs/2412.06491
by Y. Xu, @yuanyinnn.bsky.social, @eloizablocki.bsky.social, @tuanhungvu.bsky.social , @alexandreboulch.bsky.social, M. Cord
📄 Paper: arxiv.org/abs/2412.06491
by Y. Xu, @yuanyinnn.bsky.social, @eloizablocki.bsky.social, @tuanhungvu.bsky.social , @alexandreboulch.bsky.social, M. Cord
VaViM & VaVAM: Autonomous Driving through Video Generative Modeling
🔗 Project page: valeoai.github.io/vavim-vavam/
📄 Paper: arxiv.org/abs/2502.15672
💻 Code: github.com/valeoai/Vide...
by F. Bartoccioni, E. Ramzi, et al.
🔗 Project page: valeoai.github.io/vavim-vavam/
📄 Paper: arxiv.org/abs/2502.15672
💻 Code: github.com/valeoai/Vide...
by F. Bartoccioni, E. Ramzi, et al.

September 24, 2025 at 5:11 PM
VaViM & VaVAM: Autonomous Driving through Video Generative Modeling
🔗 Project page: valeoai.github.io/vavim-vavam/
📄 Paper: arxiv.org/abs/2502.15672
💻 Code: github.com/valeoai/Vide...
by F. Bartoccioni, E. Ramzi, et al.
🔗 Project page: valeoai.github.io/vavim-vavam/
📄 Paper: arxiv.org/abs/2502.15672
💻 Code: github.com/valeoai/Vide...
by F. Bartoccioni, E. Ramzi, et al.
CoRL 2025 is just around the corner in Seoul, Korea!
🤖 🚗
We're excited to present our latest research and connect with the community.
#CoRL2025
🤖 🚗
We're excited to present our latest research and connect with the community.
#CoRL2025

September 24, 2025 at 4:47 PM
CoRL 2025 is just around the corner in Seoul, Korea!
🤖 🚗
We're excited to present our latest research and connect with the community.
#CoRL2025
🤖 🚗
We're excited to present our latest research and connect with the community.
#CoRL2025
Just back from CVPR@Paris 🥐, what a fantastic event!
Great talks, great posters, and great to connect with the French & European vision community.
Kudos to the organizers, hoping that it returns next year! 🤞
#CVPR2025 @cvprconference.bsky.social
Great talks, great posters, and great to connect with the French & European vision community.
Kudos to the organizers, hoping that it returns next year! 🤞
#CVPR2025 @cvprconference.bsky.social




June 6, 2025 at 5:41 PM
Just back from CVPR@Paris 🥐, what a fantastic event!
Great talks, great posters, and great to connect with the French & European vision community.
Kudos to the organizers, hoping that it returns next year! 🤞
#CVPR2025 @cvprconference.bsky.social
Great talks, great posters, and great to connect with the French & European vision community.
Kudos to the organizers, hoping that it returns next year! 🤞
#CVPR2025 @cvprconference.bsky.social


MOCA ☕: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
by S. Gidaris, A. Bursuc, O. Simeoni, A. Vobecky, N. Komodakis, M. Cord, P. Pérez
Unify mask-and-predict & contrastive SSL objectives -> better performance w/ 3x faster training
by S. Gidaris, A. Bursuc, O. Simeoni, A. Vobecky, N. Komodakis, M. Cord, P. Pérez
Unify mask-and-predict & contrastive SSL objectives -> better performance w/ 3x faster training

April 9, 2025 at 9:38 AM
MOCA ☕: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
by S. Gidaris, A. Bursuc, O. Simeoni, A. Vobecky, N. Komodakis, M. Cord, P. Pérez
Unify mask-and-predict & contrastive SSL objectives -> better performance w/ 3x faster training
by S. Gidaris, A. Bursuc, O. Simeoni, A. Vobecky, N. Komodakis, M. Cord, P. Pérez
Unify mask-and-predict & contrastive SSL objectives -> better performance w/ 3x faster training
Learning a Neural Solver for Parametric PDE to Enhance Physics-Informed Methods
by L. Le Boudec, E. de Bézenac, @louisserrano.bsky.social, R. D. Regueiro-Espino, @yuanyinnn.bsky.social, P. Gallinari
A physics-informed neural PDE solver capable of solving a distribution of PDE instances
by L. Le Boudec, E. de Bézenac, @louisserrano.bsky.social, R. D. Regueiro-Espino, @yuanyinnn.bsky.social, P. Gallinari
A physics-informed neural PDE solver capable of solving a distribution of PDE instances

April 9, 2025 at 9:38 AM
Learning a Neural Solver for Parametric PDE to Enhance Physics-Informed Methods
by L. Le Boudec, E. de Bézenac, @louisserrano.bsky.social, R. D. Regueiro-Espino, @yuanyinnn.bsky.social, P. Gallinari
A physics-informed neural PDE solver capable of solving a distribution of PDE instances
by L. Le Boudec, E. de Bézenac, @louisserrano.bsky.social, R. D. Regueiro-Espino, @yuanyinnn.bsky.social, P. Gallinari
A physics-informed neural PDE solver capable of solving a distribution of PDE instances
ToddlerDiffusion: Interactive Structured Image Generation with Cascaded Schrödinger Bridge
by E. Abdelrahman, L. Zhao, @vtaohu.bsky.social, @matthieucord.bsky.social, @ptrkprz.bsky.social, M. Elhoseiny
A diffusion framework to generate high-quality RGB images more efficiently than Stable Diffusion
by E. Abdelrahman, L. Zhao, @vtaohu.bsky.social, @matthieucord.bsky.social, @ptrkprz.bsky.social, M. Elhoseiny
A diffusion framework to generate high-quality RGB images more efficiently than Stable Diffusion

April 9, 2025 at 9:38 AM
ToddlerDiffusion: Interactive Structured Image Generation with Cascaded Schrödinger Bridge
by E. Abdelrahman, L. Zhao, @vtaohu.bsky.social, @matthieucord.bsky.social, @ptrkprz.bsky.social, M. Elhoseiny
A diffusion framework to generate high-quality RGB images more efficiently than Stable Diffusion
by E. Abdelrahman, L. Zhao, @vtaohu.bsky.social, @matthieucord.bsky.social, @ptrkprz.bsky.social, M. Elhoseiny
A diffusion framework to generate high-quality RGB images more efficiently than Stable Diffusion
LLM-wrapper: Black-Box Semantic-Aware Adaptation of VLMs for Referring Expression Comprehension (REC), by A. Cardiel, @eloizablocki.bsky.social, E. Ramzi, O. Simeoni, @matthieucord.bsky.social
Boost VLM perf by tuning an LLM to reason on its outputs! It's black-box🔒 & efficient⚡ (< 7h on 1 GPU)
Boost VLM perf by tuning an LLM to reason on its outputs! It's black-box🔒 & efficient⚡ (< 7h on 1 GPU)

April 9, 2025 at 9:38 AM
LLM-wrapper: Black-Box Semantic-Aware Adaptation of VLMs for Referring Expression Comprehension (REC), by A. Cardiel, @eloizablocki.bsky.social, E. Ramzi, O. Simeoni, @matthieucord.bsky.social
Boost VLM perf by tuning an LLM to reason on its outputs! It's black-box🔒 & efficient⚡ (< 7h on 1 GPU)
Boost VLM perf by tuning an LLM to reason on its outputs! It's black-box🔒 & efficient⚡ (< 7h on 1 GPU)
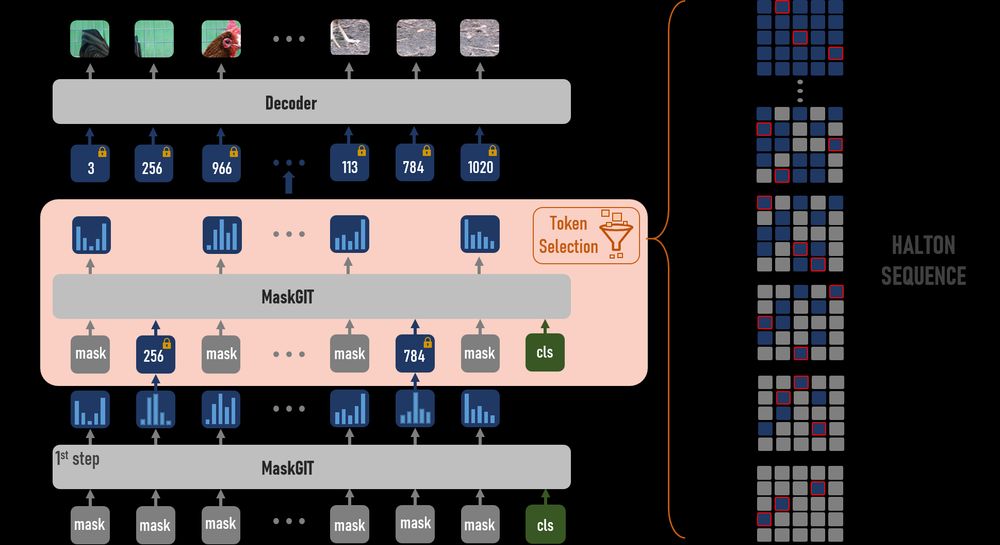
Halton Scheduler for Masked Generative Image Transformer
by V. Besnier, @mickaelchen.bsky.social, D. Hurych, E. Valle, @matthieucord.bsky.social
⭐️Halton Scheduler⭐️ fixes original MaskGIT’s sampling flaws by using a low-discrepancy sequences, distributing token selection uniformly across the image🚀
by V. Besnier, @mickaelchen.bsky.social, D. Hurych, E. Valle, @matthieucord.bsky.social
⭐️Halton Scheduler⭐️ fixes original MaskGIT’s sampling flaws by using a low-discrepancy sequences, distributing token selection uniformly across the image🚀
April 9, 2025 at 9:38 AM
Halton Scheduler for Masked Generative Image Transformer
by V. Besnier, @mickaelchen.bsky.social, D. Hurych, E. Valle, @matthieucord.bsky.social
⭐️Halton Scheduler⭐️ fixes original MaskGIT’s sampling flaws by using a low-discrepancy sequences, distributing token selection uniformly across the image🚀
by V. Besnier, @mickaelchen.bsky.social, D. Hurych, E. Valle, @matthieucord.bsky.social
⭐️Halton Scheduler⭐️ fixes original MaskGIT’s sampling flaws by using a low-discrepancy sequences, distributing token selection uniformly across the image🚀
Our recent research will be presented at #ICLR2025 @iclr_conf: VLMs, LLMs, diffusion models, self-supervised learning, physics-informed learning…
Find out more below 🧵
valeoai.github.io/posts/2025-0...
Find out more below 🧵
valeoai.github.io/posts/2025-0...

April 9, 2025 at 9:38 AM
Our recent research will be presented at #ICLR2025 @iclr_conf: VLMs, LLMs, diffusion models, self-supervised learning, physics-informed learning…
Find out more below 🧵
valeoai.github.io/posts/2025-0...
Find out more below 🧵
valeoai.github.io/posts/2025-0...
We have a very special guest visiting us today: the one and only Alyosha Efros



March 20, 2025 at 10:16 PM
We have a very special guest visiting us today: the one and only Alyosha Efros
We’re just scratching the surface of the "big models + raw video + closed-loop sim" stack.
More to come! 🚀
Retweet if you’re excited, and follow @valeoai.bsky.social for updates! 💚
🙏 Thanks for reading!
[10/10]
More to come! 🚀
Retweet if you’re excited, and follow @valeoai.bsky.social for updates! 💚
🙏 Thanks for reading!
[10/10]

February 24, 2025 at 12:53 PM
We’re just scratching the surface of the "big models + raw video + closed-loop sim" stack.
More to come! 🚀
Retweet if you’re excited, and follow @valeoai.bsky.social for updates! 💚
🙏 Thanks for reading!
[10/10]
More to come! 🚀
Retweet if you’re excited, and follow @valeoai.bsky.social for updates! 💚
🙏 Thanks for reading!
[10/10]
The results?
🔄 Validated through closed-loop testing using NeuroNCAP
Our model achieves:
🏆 SOTA on NeuroNCAP safety benchmark in frontal scenario
🤔 But scaling is inconsistent: see more in the paper and project page
[7/10]
🔄 Validated through closed-loop testing using NeuroNCAP
Our model achieves:
🏆 SOTA on NeuroNCAP safety benchmark in frontal scenario
🤔 But scaling is inconsistent: see more in the paper and project page
[7/10]
February 24, 2025 at 12:53 PM
The results?
🔄 Validated through closed-loop testing using NeuroNCAP
Our model achieves:
🏆 SOTA on NeuroNCAP safety benchmark in frontal scenario
🤔 But scaling is inconsistent: see more in the paper and project page
[7/10]
🔄 Validated through closed-loop testing using NeuroNCAP
Our model achieves:
🏆 SOTA on NeuroNCAP safety benchmark in frontal scenario
🤔 But scaling is inconsistent: see more in the paper and project page
[7/10]
Video Features + Flow Matching = Driving 🚙
VaVAM’s action module draws from π0: a flow matching approach for action prediction
Kudos to the π0 team! (and to @remicadene.bsky.social)
[6/10]
VaVAM’s action module draws from π0: a flow matching approach for action prediction
Kudos to the π0 team! (and to @remicadene.bsky.social)
[6/10]

February 24, 2025 at 12:53 PM
Video Features + Flow Matching = Driving 🚙
VaVAM’s action module draws from π0: a flow matching approach for action prediction
Kudos to the π0 team! (and to @remicadene.bsky.social)
[6/10]
VaVAM’s action module draws from π0: a flow matching approach for action prediction
Kudos to the π0 team! (and to @remicadene.bsky.social)
[6/10]
We visualized VaViM's semantic features using PCA projection 🎨
Each color represents different learned concepts:
🚶 Pedestrians
🏢 Buildings & structures
🚸Crosswalks
Pure emergent semantic grouping!
Future works will study this in more detail 🕵️
[5/10]
Each color represents different learned concepts:
🚶 Pedestrians
🏢 Buildings & structures
🚸Crosswalks
Pure emergent semantic grouping!
Future works will study this in more detail 🕵️
[5/10]


February 24, 2025 at 12:53 PM
We visualized VaViM's semantic features using PCA projection 🎨
Each color represents different learned concepts:
🚶 Pedestrians
🏢 Buildings & structures
🚸Crosswalks
Pure emergent semantic grouping!
Future works will study this in more detail 🕵️
[5/10]
Each color represents different learned concepts:
🚶 Pedestrians
🏢 Buildings & structures
🚸Crosswalks
Pure emergent semantic grouping!
Future works will study this in more detail 🕵️
[5/10]
Indeed, scale matters 📈
We computed the scaling law and optimal frontier for you 😉
Spoiler: we need even more driving data!
⇨ Bigger models + more data = better generation
⇨ Better driving? let's see...
All details in our report:
🔗 arxiv.org/abs/2502.15672
[4/10]
We computed the scaling law and optimal frontier for you 😉
Spoiler: we need even more driving data!
⇨ Bigger models + more data = better generation
⇨ Better driving? let's see...
All details in our report:
🔗 arxiv.org/abs/2502.15672
[4/10]

February 24, 2025 at 12:53 PM
Indeed, scale matters 📈
We computed the scaling law and optimal frontier for you 😉
Spoiler: we need even more driving data!
⇨ Bigger models + more data = better generation
⇨ Better driving? let's see...
All details in our report:
🔗 arxiv.org/abs/2502.15672
[4/10]
We computed the scaling law and optimal frontier for you 😉
Spoiler: we need even more driving data!
⇨ Bigger models + more data = better generation
⇨ Better driving? let's see...
All details in our report:
🔗 arxiv.org/abs/2502.15672
[4/10]