



Marianne de Heer Kloots
@mdhk.net
Linguist in AI & CogSci 🧠👩💻🤖 PhD student @ ILLC, University of Amsterdam
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
Pinned
Marianne de Heer Kloots
@mdhk.net
· Jul 8
✨ Do current neural speech models show human-like linguistic biases in speech perception?
We took inspiration from classic phonetic categorization experiments to explore where sensitivity to phonotactic context emerges in Wav2Vec2 models 🔍
(w/ @wzuidema.bsky.social)
📑 arxiv.org/abs/2407.03005
⬇️
We took inspiration from classic phonetic categorization experiments to explore where sensitivity to phonotactic context emerges in Wav2Vec2 models 🔍
(w/ @wzuidema.bsky.social)
📑 arxiv.org/abs/2407.03005
⬇️
Reposted by Marianne de Heer Kloots

The Multilingual Minds & Machines Meetings call for abstracts is now open! Everything you need to know is here -> mmmm2026.github.io
November 18, 2025 at 10:05 AM
The Multilingual Minds & Machines Meetings call for abstracts is now open! Everything you need to know is here -> mmmm2026.github.io
Reposted by Marianne de Heer Kloots

happy to share our new paper, out now in Neuron! led by the incredible Yizhen Zhang, we explore how the brain segments continuous speech into word-forms and uses adaptive dynamics to code for relative time - www.sciencedirect.com/science/arti...

Human cortical dynamics of auditory word form encoding
We perceive continuous speech as a series of discrete words, despite the lack of clear acoustic boundaries. The superior temporal gyrus (STG) encodes …
www.sciencedirect.com
November 7, 2025 at 6:16 PM
happy to share our new paper, out now in Neuron! led by the incredible Yizhen Zhang, we explore how the brain segments continuous speech into word-forms and uses adaptive dynamics to code for relative time - www.sciencedirect.com/science/arti...
Reposted by Marianne de Heer Kloots
Delighted to share our new paper, now out in PNAS! www.pnas.org/doi/10.1073/...
"Hierarchical dynamic coding coordinates speech comprehension in the brain"
with dream team @alecmarantz.bsky.social, @davidpoeppel.bsky.social, @jeanremiking.bsky.social
Summary 👇
1/8
"Hierarchical dynamic coding coordinates speech comprehension in the brain"
with dream team @alecmarantz.bsky.social, @davidpoeppel.bsky.social, @jeanremiking.bsky.social
Summary 👇
1/8
PNAS
Proceedings of the National Academy of Sciences (PNAS), a peer reviewed journal of the National Academy of Sciences (NAS) - an authoritative source of high-impact, original research that broadly spans...
www.pnas.org
October 22, 2025 at 5:21 AM
Delighted to share our new paper, now out in PNAS! www.pnas.org/doi/10.1073/...
"Hierarchical dynamic coding coordinates speech comprehension in the brain"
with dream team @alecmarantz.bsky.social, @davidpoeppel.bsky.social, @jeanremiking.bsky.social
Summary 👇
1/8
"Hierarchical dynamic coding coordinates speech comprehension in the brain"
with dream team @alecmarantz.bsky.social, @davidpoeppel.bsky.social, @jeanremiking.bsky.social
Summary 👇
1/8
Reposted by Marianne de Heer Kloots

🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!

October 15, 2025 at 10:53 AM
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
Reposted by Marianne de Heer Kloots

Interesting paper suggesting a mechanism for why in-context learning happens in LLMs.
They show that LLMs implicitly apply an internal low-rank weight update adjusted by the context. It’s cheap (due to the low-rank) but effective for adapting the model’s behavior.
#MLSky
arxiv.org/abs/2507.16003
They show that LLMs implicitly apply an internal low-rank weight update adjusted by the context. It’s cheap (due to the low-rank) but effective for adapting the model’s behavior.
#MLSky
arxiv.org/abs/2507.16003

Learning without training: The implicit dynamics of in-context learning
One of the most striking features of Large Language Models (LLM) is their ability to learn in context. Namely at inference time an LLM is able to learn new patterns without any additional weight updat...
arxiv.org
October 6, 2025 at 1:30 PM
Interesting paper suggesting a mechanism for why in-context learning happens in LLMs.
They show that LLMs implicitly apply an internal low-rank weight update adjusted by the context. It’s cheap (due to the low-rank) but effective for adapting the model’s behavior.
#MLSky
arxiv.org/abs/2507.16003
They show that LLMs implicitly apply an internal low-rank weight update adjusted by the context. It’s cheap (due to the low-rank) but effective for adapting the model’s behavior.
#MLSky
arxiv.org/abs/2507.16003
Reposted by Marianne de Heer Kloots

PhD Position: Accented Speech Processing - Apply now!
Come work with Mirjam Broersma, @davidpeeters.bsky.social, and me at the Centre for Language Studies, Radboud University in the Netherlands.
Application deadline: 19 October 2025
For more information, see
www.ru.nl/en/working-a...
Come work with Mirjam Broersma, @davidpeeters.bsky.social, and me at the Centre for Language Studies, Radboud University in the Netherlands.
Application deadline: 19 October 2025
For more information, see
www.ru.nl/en/working-a...

PhD Position: Accented Speech Processing | Radboud University
Do you want to work as a PhD: Accented Speech Processing at the Faculty of Arts? Check our vacancy!
www.ru.nl
October 2, 2025 at 2:35 PM
PhD Position: Accented Speech Processing - Apply now!
Come work with Mirjam Broersma, @davidpeeters.bsky.social, and me at the Centre for Language Studies, Radboud University in the Netherlands.
Application deadline: 19 October 2025
For more information, see
www.ru.nl/en/working-a...
Come work with Mirjam Broersma, @davidpeeters.bsky.social, and me at the Centre for Language Studies, Radboud University in the Netherlands.
Application deadline: 19 October 2025
For more information, see
www.ru.nl/en/working-a...
Huge congrats to the envisionBOX team for the Open Science award nomination! 🎉
My tutorial on speech analysis tools in Python from the Unboxing Multimodality summer school (github.com/mdhk/unboxin...) is now also available at envisionbox.org
Thanks for the invitation & this great initiative! 👏
My tutorial on speech analysis tools in Python from the Unboxing Multimodality summer school (github.com/mdhk/unboxin...) is now also available at envisionbox.org
Thanks for the invitation & this great initiative! 👏

www.envisionbox.org has been shortlisted for the Leo Waaijers Open Science price: ukb.nl/en/news/shor...
@babajideowoyele.bsky.social @jamestrujillo.bsky.social @sarkadava.bsky.social @DavideAhmar @acwiek.bsky.social
Amazing Markus Küpper made an animated video:
www.youtube.com/watch?v=HduI...
@babajideowoyele.bsky.social @jamestrujillo.bsky.social @sarkadava.bsky.social @DavideAhmar @acwiek.bsky.social
Amazing Markus Küpper made an animated video:
www.youtube.com/watch?v=HduI...

EnvisionBOX overview2025
YouTube video by Wim Pouw
www.youtube.com
October 2, 2025 at 5:18 PM
Huge congrats to the envisionBOX team for the Open Science award nomination! 🎉
My tutorial on speech analysis tools in Python from the Unboxing Multimodality summer school (github.com/mdhk/unboxin...) is now also available at envisionbox.org
Thanks for the invitation & this great initiative! 👏
My tutorial on speech analysis tools in Python from the Unboxing Multimodality summer school (github.com/mdhk/unboxin...) is now also available at envisionbox.org
Thanks for the invitation & this great initiative! 👏
Reposted by Marianne de Heer Kloots

The 𝗜𝗟𝗖𝗕 𝗦𝘂𝗺𝗺𝗲𝗿 𝗦𝗰𝗵𝗼𝗼𝗹 in Marseille went beyond all my expectations! 💯
A week has already flown by since I had one of the most formative experiences of my PhD so far. 👩🎨
A week has already flown by since I had one of the most formative experiences of my PhD so far. 👩🎨




September 12, 2025 at 9:52 AM
The 𝗜𝗟𝗖𝗕 𝗦𝘂𝗺𝗺𝗲𝗿 𝗦𝗰𝗵𝗼𝗼𝗹 in Marseille went beyond all my expectations! 💯
A week has already flown by since I had one of the most formative experiences of my PhD so far. 👩🎨
A week has already flown by since I had one of the most formative experiences of my PhD so far. 👩🎨
✨ Do self-supervised speech models learn to encode language-specific linguistic features from their training data, or only more language-general acoustic correlates?
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️

August 27, 2025 at 2:31 PM
✨ Do self-supervised speech models learn to encode language-specific linguistic features from their training data, or only more language-general acoustic correlates?
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
August 19, 2025 at 9:23 PM
Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
Reposted by Marianne de Heer Kloots

Humans largely learn language through speech. In contrast, most LLMs learn from pre-tokenized text.
In our #Interspeech2025 paper, we introduce AuriStream: a simple, causal model that learns phoneme, word & semantic information from speech.
Poster P6, tomorrow (Aug 19) at 1:30 pm, Foyer 2.2!
In our #Interspeech2025 paper, we introduce AuriStream: a simple, causal model that learns phoneme, word & semantic information from speech.
Poster P6, tomorrow (Aug 19) at 1:30 pm, Foyer 2.2!
August 19, 2025 at 1:12 AM
Humans largely learn language through speech. In contrast, most LLMs learn from pre-tokenized text.
In our #Interspeech2025 paper, we introduce AuriStream: a simple, causal model that learns phoneme, word & semantic information from speech.
Poster P6, tomorrow (Aug 19) at 1:30 pm, Foyer 2.2!
In our #Interspeech2025 paper, we introduce AuriStream: a simple, causal model that learns phoneme, word & semantic information from speech.
Poster P6, tomorrow (Aug 19) at 1:30 pm, Foyer 2.2!
Reposted by Marianne de Heer Kloots

What a privilege to have #CCN2025 in (an exceptionally warm and sunny) Amsterdam this year!
It was my first time attending the conference, and being surrounded by so many talented researchers whose interests are similar to mine has been a deeply enriching experience ✨
It was my first time attending the conference, and being surrounded by so many talented researchers whose interests are similar to mine has been a deeply enriching experience ✨

August 17, 2025 at 1:46 PM
What a privilege to have #CCN2025 in (an exceptionally warm and sunny) Amsterdam this year!
It was my first time attending the conference, and being surrounded by so many talented researchers whose interests are similar to mine has been a deeply enriching experience ✨
It was my first time attending the conference, and being surrounded by so many talented researchers whose interests are similar to mine has been a deeply enriching experience ✨
Huge congrats to @maithevannoort.bsky.social on her very popular poster! 🎉 She is now also on bluesky (and looking for a PhD position 👀)
MSc student Maithe van Noort will present her project (co-supervised with @mheilbron.bsky.social) on Compositional Meaning in Vision Language Models and the Brain, testing the waters with new fMRI data of the human brain on Winoground! (poster B26)
🔗 2025.ccneuro.org/poster/?id=1...
🔗 2025.ccneuro.org/poster/?id=1...
August 13, 2025 at 4:23 PM
Huge congrats to @maithevannoort.bsky.social on her very popular poster! 🎉 She is now also on bluesky (and looking for a PhD position 👀)
So exciting, #CCN2025 in Amsterdam started today! We have stroopwafels!!
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...


August 12, 2025 at 2:19 PM
So exciting, #CCN2025 in Amsterdam started today! We have stroopwafels!!
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
I’m in hall X5 at board 3! See you there 🙌
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
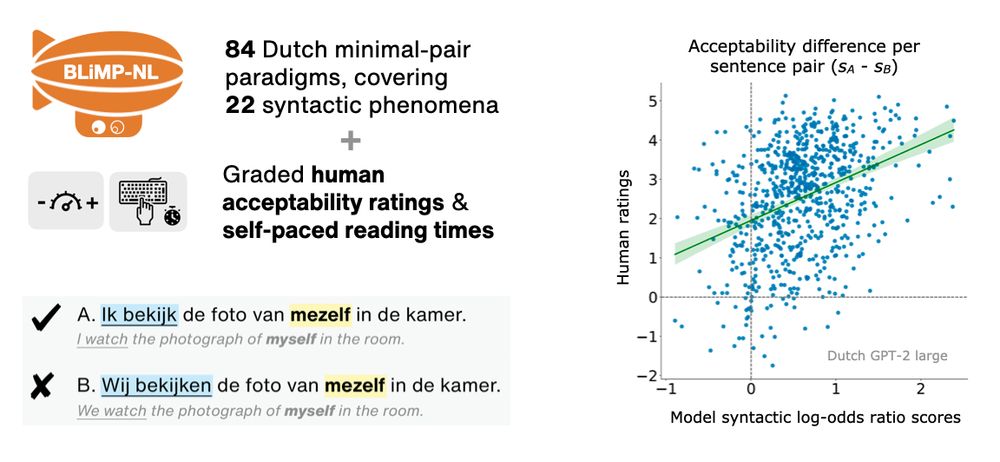
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
July 29, 2025 at 2:02 PM
I’m in hall X5 at board 3! See you there 🙌
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
July 24, 2025 at 3:30 PM
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
Reposted by Marianne de Heer Kloots

Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
coginterp.github.io
July 16, 2025 at 1:08 PM
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Reposted by Marianne de Heer Kloots

ICYMI githistory.xyz is a great way to navigate #git commits and visualise how a file has been changing across commits
Just replace github.com with github.githistory.xyz in the URL and enjoy! #rstats
Just replace github.com with github.githistory.xyz in the URL and enjoy! #rstats
June 19, 2025 at 5:34 PM
ICYMI githistory.xyz is a great way to navigate #git commits and visualise how a file has been changing across commits
Just replace github.com with github.githistory.xyz in the URL and enjoy! #rstats
Just replace github.com with github.githistory.xyz in the URL and enjoy! #rstats
The @interspeech.bsky.social early registration deadline is coming up in a few days!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!

Interpretability Techniques for Speech Models — Tutorial @ Interspeech 2025
interpretingdl.github.io
June 13, 2025 at 5:18 AM
The @interspeech.bsky.social early registration deadline is coming up in a few days!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Reposted by Marianne de Heer Kloots

I am excited to announce that my paper "On the reliability of feature attribution methods for speech classification" has been accepted to #Interspeech2025!
Co-authors: @hmohebbi.bsky.social, Arianna Bisazza, Afra Alishahi, @grzegorz.chrupala.me
Find the preprint here: arxiv.org/abs/2505.16406
Co-authors: @hmohebbi.bsky.social, Arianna Bisazza, Afra Alishahi, @grzegorz.chrupala.me
Find the preprint here: arxiv.org/abs/2505.16406

On the reliability of feature attribution methods for speech classification
As the capabilities of large-scale pre-trained models evolve, understanding the determinants of their outputs becomes more important. Feature attribution aims to reveal which parts of the input elemen...
arxiv.org
May 26, 2025 at 8:21 AM
I am excited to announce that my paper "On the reliability of feature attribution methods for speech classification" has been accepted to #Interspeech2025!
Co-authors: @hmohebbi.bsky.social, Arianna Bisazza, Afra Alishahi, @grzegorz.chrupala.me
Find the preprint here: arxiv.org/abs/2505.16406
Co-authors: @hmohebbi.bsky.social, Arianna Bisazza, Afra Alishahi, @grzegorz.chrupala.me
Find the preprint here: arxiv.org/abs/2505.16406
Reposted by Marianne de Heer Kloots

Next we jump from analyzing text models to predictive speech models! Phoneticists have claimed for decades that humans rely more on contextual cues when processing vowels compared to consonants. Turns out so do speech models!

June 12, 2025 at 6:56 PM
Next we jump from analyzing text models to predictive speech models! Phoneticists have claimed for decades that humans rely more on contextual cues when processing vowels compared to consonants. Turns out so do speech models!
Reposted by Marianne de Heer Kloots

An important read (🎁), shared for all the reasons.
This is fascism.
This is fascism.

Hitler Used a Bogus Crisis of ‘Public Order’ to Make Himself Dictator
Using disorder he had helped manufacture, the chancellor seized control of Bavaria.
www.theatlantic.com
June 10, 2025 at 7:25 PM
An important read (🎁), shared for all the reasons.
This is fascism.
This is fascism.
Reposted by Marianne de Heer Kloots

Na viraal optreden op Koningsdag is The Space Choir nu ook in Amsterdam: ‘Zullen we ’m een keer als hooligans zingen? Echt F-side wil ik horen’

Na viraal optreden op Koningsdag is The Space Choir nu ook in Amsterdam: ‘Zullen we ’m een keer als hooligans zingen? Echt F-side wil ik horen’
The Space Choir wil al zingend queerpersonen, pensionado’s, geschoolde én ongeschoolde vocalisten met elkaar verbinden. Na groot succes in andere steden en een viraal optreden op Koningsdag repeteert het koor nu ook in Amsterdam. ‘Ik vond het kapot eng om hierheen te gaan.’
www.parool.nl
June 9, 2025 at 3:06 PM
Na viraal optreden op Koningsdag is The Space Choir nu ook in Amsterdam: ‘Zullen we ’m een keer als hooligans zingen? Echt F-side wil ik horen’
Reposted by Marianne de Heer Kloots
New postdoc positions at the (DISI-affiliated) Center for Possible Minds at Indiana University.
Looking for scholars interested in interdisciplinary research on the nature of biological, artificial, and collective intelligence.
Please share widely!
indiana.peopleadmin.com/postings/29547
Looking for scholars interested in interdisciplinary research on the nature of biological, artificial, and collective intelligence.
Please share widely!
indiana.peopleadmin.com/postings/29547
Center for Possible Minds Postdoctoral Fellow
The Center for Possible Minds at Indiana University, Bloomington, invites applications for Postdoctoral Fellows to join its Program for Advanced Research in Diverse Intelligences. The fellowship provi...
indiana.peopleadmin.com
May 27, 2025 at 6:39 PM
New postdoc positions at the (DISI-affiliated) Center for Possible Minds at Indiana University.
Looking for scholars interested in interdisciplinary research on the nature of biological, artificial, and collective intelligence.
Please share widely!
indiana.peopleadmin.com/postings/29547
Looking for scholars interested in interdisciplinary research on the nature of biological, artificial, and collective intelligence.
Please share widely!
indiana.peopleadmin.com/postings/29547
Reposted by Marianne de Heer Kloots
What are the organizing dimensions of language processing?
We show that voxel responses during comprehension are organized along 2 main axes: processing difficulty & meaning abstractness—revealing an interpretable, topographic representational basis for language processing shared across individuals
We show that voxel responses during comprehension are organized along 2 main axes: processing difficulty & meaning abstractness—revealing an interpretable, topographic representational basis for language processing shared across individuals
May 23, 2025 at 5:00 PM
What are the organizing dimensions of language processing?
We show that voxel responses during comprehension are organized along 2 main axes: processing difficulty & meaning abstractness—revealing an interpretable, topographic representational basis for language processing shared across individuals
We show that voxel responses during comprehension are organized along 2 main axes: processing difficulty & meaning abstractness—revealing an interpretable, topographic representational basis for language processing shared across individuals