



Marianne de Heer Kloots
@mdhk.net
Linguist in AI & CogSci 🧠👩💻🤖 PhD student @ ILLC, University of Amsterdam
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
Finally, downstream performance on Dutch speech-to-text transcription reflects the language-specific advantage for Dutch linguistic feature encoding in model-internal representations: on average, Wav2Vec2-NL has a 27% lower word error rate than the multilingual model.

August 27, 2025 at 2:31 PM
Finally, downstream performance on Dutch speech-to-text transcription reflects the language-specific advantage for Dutch linguistic feature encoding in model-internal representations: on average, Wav2Vec2-NL has a 27% lower word error rate than the multilingual model.
We find that language-specific advantages are well-detected by trained clustering or classification probes, and partially observable using zero-shot metrics. I.e. the encoding of Dutch linguistic features is enhanced in the Dutch model, as compared to models trained on English and multilingual data.

August 27, 2025 at 2:31 PM
We find that language-specific advantages are well-detected by trained clustering or classification probes, and partially observable using zero-shot metrics. I.e. the encoding of Dutch linguistic features is enhanced in the Dutch model, as compared to models trained on English and multilingual data.
But they also used different analysis techniques.
We designed the SSL-NL dataset to test the encoding of Dutch phonetic and lexical features in SSL speech representations, while allowing for comparisons across different analysis methods.
We compare both trained probes(*) and zero-shot metrics:
We designed the SSL-NL dataset to test the encoding of Dutch phonetic and lexical features in SSL speech representations, while allowing for comparisons across different analysis methods.
We compare both trained probes(*) and zero-shot metrics:

August 27, 2025 at 2:31 PM
But they also used different analysis techniques.
We designed the SSL-NL dataset to test the encoding of Dutch phonetic and lexical features in SSL speech representations, while allowing for comparisons across different analysis methods.
We compare both trained probes(*) and zero-shot metrics:
We designed the SSL-NL dataset to test the encoding of Dutch phonetic and lexical features in SSL speech representations, while allowing for comparisons across different analysis methods.
We compare both trained probes(*) and zero-shot metrics:
✨ Do self-supervised speech models learn to encode language-specific linguistic features from their training data, or only more language-general acoustic correlates?
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️

August 27, 2025 at 2:31 PM
✨ Do self-supervised speech models learn to encode language-specific linguistic features from their training data, or only more language-general acoustic correlates?
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
At #Interspeech2025 we presented our new Wav2Vec2-NL model and SSL-NL evaluation dataset to test this!
📄 arxiv.org/abs/2506.00981
⬇️
Last but not least, I personally can’t wait for the social event on Thursday night that we’ve been planning for the past year ✨
It features a *live brain-controlled music act* by the AIAR collective 🧠🎶 2025.ccneuro.org/social-event/ Get one of the last remaining tickets at the registration desk now!
It features a *live brain-controlled music act* by the AIAR collective 🧠🎶 2025.ccneuro.org/social-event/ Get one of the last remaining tickets at the registration desk now!

August 12, 2025 at 2:19 PM
Last but not least, I personally can’t wait for the social event on Thursday night that we’ve been planning for the past year ✨
It features a *live brain-controlled music act* by the AIAR collective 🧠🎶 2025.ccneuro.org/social-event/ Get one of the last remaining tickets at the registration desk now!
It features a *live brain-controlled music act* by the AIAR collective 🧠🎶 2025.ccneuro.org/social-event/ Get one of the last remaining tickets at the registration desk now!
So exciting, #CCN2025 in Amsterdam started today! We have stroopwafels!!
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...


August 12, 2025 at 2:19 PM
So exciting, #CCN2025 in Amsterdam started today! We have stroopwafels!!
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
Catch me at my poster on Friday to chat about the role of context in neural representational alignment to spoken language systems (C34) 🙌
🔗 2025.ccneuro.org/poster/?id=K...
We are having an impromptu overflow room around the corner 😅

July 28, 2025 at 12:26 PM
We are having an impromptu overflow room around the corner 😅
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
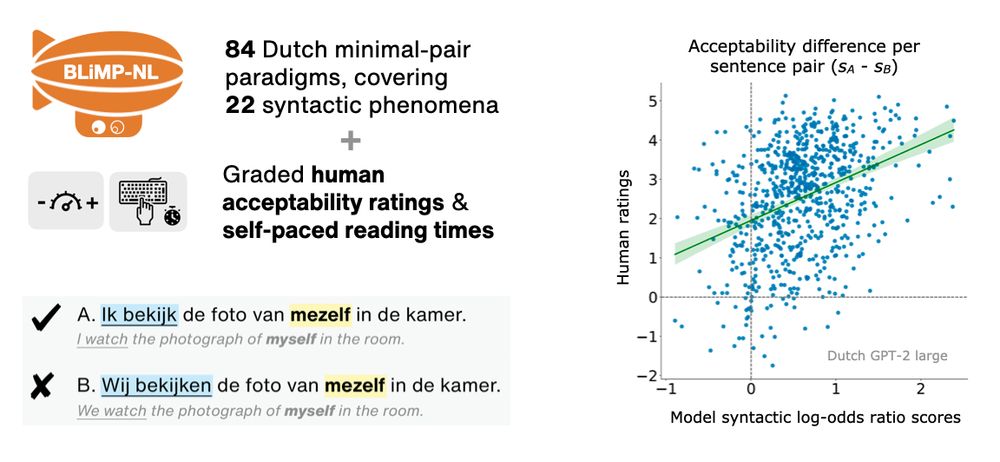
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
July 24, 2025 at 3:30 PM
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
If you see this, post a concert picture you took this year.

December 29, 2024 at 4:15 PM
If you see this, post a concert picture you took this year.

In a bizarre undemocratic turn of events, the massive national protest against our government's plans for higher education was cancelled last week.
We'll be back stronger next Monday in The Hague! 🟥
We'll be back stronger next Monday in The Hague! 🟥

November 19, 2024 at 12:43 PM
In a bizarre undemocratic turn of events, the massive national protest against our government's plans for higher education was cancelled last week.
We'll be back stronger next Monday in The Hague! 🟥
We'll be back stronger next Monday in The Hague! 🟥
Or this from within The Netherlands: campagnes.degoedezaak.org/campaigns/st...
and come to Utrecht on Nov 14th! www.fnv.nl/cao-sector/o...
and come to Utrecht on Nov 14th! www.fnv.nl/cao-sector/o...

October 29, 2024 at 5:13 PM
Or this from within The Netherlands: campagnes.degoedezaak.org/campaigns/st...
and come to Utrecht on Nov 14th! www.fnv.nl/cao-sector/o...
and come to Utrecht on Nov 14th! www.fnv.nl/cao-sector/o...
Bluesky now has over 10 million users, and I was #497,227! 😎

September 18, 2024 at 6:52 AM
Bluesky now has over 10 million users, and I was #497,227! 😎
I will be presenting this work tomorrow (Thursday) at #INTERSPEECH2024, 10.00-10.40 in the Acesso room!
Looking forward to discuss how we can learn from human speech science to interpret end-to-end neural speech models 💡
The paper is here: www.isca-archive.org/interspeech_...
Looking forward to discuss how we can learn from human speech science to interpret end-to-end neural speech models 💡
The paper is here: www.isca-archive.org/interspeech_...

September 4, 2024 at 6:35 AM
I will be presenting this work tomorrow (Thursday) at #INTERSPEECH2024, 10.00-10.40 in the Acesso room!
Looking forward to discuss how we can learn from human speech science to interpret end-to-end neural speech models 💡
The paper is here: www.isca-archive.org/interspeech_...
Looking forward to discuss how we can learn from human speech science to interpret end-to-end neural speech models 💡
The paper is here: www.isca-archive.org/interspeech_...
It turns out the accuracy of dependency structures decoded from LM hidden layers (measured by Labelled Attachment Score) strongly correlates with similarity to brain activity in sentence reading! 🧠
This correlation disappears in a control condition with scrambled inputs.
This correlation disappears in a control condition with scrambled inputs.

July 23, 2024 at 8:53 PM
It turns out the accuracy of dependency structures decoded from LM hidden layers (measured by Labelled Attachment Score) strongly correlates with similarity to brain activity in sentence reading! 🧠
This correlation disappears in a control condition with scrambled inputs.
This correlation disappears in a control condition with scrambled inputs.
Language model internal states show surprising similarity to human brain activity in language comprehension — but how does this relate to their accurate representation of structured linguistic information, like syntactic dependencies? (i.e. links between words in a sentence)

July 23, 2024 at 8:50 PM
Language model internal states show surprising similarity to human brain activity in language comprehension — but how does this relate to their accurate representation of structured linguistic information, like syntactic dependencies? (i.e. links between words in a sentence)
Excited for #CogSci2024 this week!
In session T.24 on Friday morning (10.30-12), Bram will present our work on representational alignment between LMs, brains, and syntactic structure 🤖🧠💬
w/ Rochelle Choenni, @mheilbron.bsky.social & @wzuidema.bsky.social
📑 escholarship.org/uc/item/1fp7...
⬇️
In session T.24 on Friday morning (10.30-12), Bram will present our work on representational alignment between LMs, brains, and syntactic structure 🤖🧠💬
w/ Rochelle Choenni, @mheilbron.bsky.social & @wzuidema.bsky.social
📑 escholarship.org/uc/item/1fp7...
⬇️

July 23, 2024 at 8:49 PM
Excited for #CogSci2024 this week!
In session T.24 on Friday morning (10.30-12), Bram will present our work on representational alignment between LMs, brains, and syntactic structure 🤖🧠💬
w/ Rochelle Choenni, @mheilbron.bsky.social & @wzuidema.bsky.social
📑 escholarship.org/uc/item/1fp7...
⬇️
In session T.24 on Friday morning (10.30-12), Bram will present our work on representational alignment between LMs, brains, and syntactic structure 🤖🧠💬
w/ Rochelle Choenni, @mheilbron.bsky.social & @wzuidema.bsky.social
📑 escholarship.org/uc/item/1fp7...
⬇️
📏 We also compare three analysis methods for decoding phoneme preference from model internals, and find interesting differences between them!
➡️ Read more in the paper: arxiv.org/abs/2407.03005
➡️ Read more in the paper: arxiv.org/abs/2407.03005


July 8, 2024 at 5:40 AM
📏 We also compare three analysis methods for decoding phoneme preference from model internals, and find interesting differences between them!
➡️ Read more in the paper: arxiv.org/abs/2407.03005
➡️ Read more in the paper: arxiv.org/abs/2407.03005
💡 We find similar adaptation to phonotactic context in Wav2Vec2 models, emerging around the 4th layer of their Transformer module. This effect is amplified by finetuning for text transcription, but also present in fully self-supervised models (when trained on English speech).

July 8, 2024 at 5:39 AM
💡 We find similar adaptation to phonotactic context in Wav2Vec2 models, emerging around the 4th layer of their Transformer module. This effect is amplified by finetuning for text transcription, but also present in fully self-supervised models (when trained on English speech).
One case of such contextual biasing effects comes from phonotactic constraints.
For example in English: TL << TR, SL >> SR
This has been demonstrated in human listeners a while ago! (doi.org/10.3758/BF03...)
For example in English: TL << TR, SL >> SR
This has been demonstrated in human listeners a while ago! (doi.org/10.3758/BF03...)

July 8, 2024 at 5:38 AM
One case of such contextual biasing effects comes from phonotactic constraints.
For example in English: TL << TR, SL >> SR
This has been demonstrated in human listeners a while ago! (doi.org/10.3758/BF03...)
For example in English: TL << TR, SL >> SR
This has been demonstrated in human listeners a while ago! (doi.org/10.3758/BF03...)
Feeling very inspired about ✨Using ANNs for Studying Human Language Learning and Processing (ann-humlang.github.io )✨ after the workshop that Tamar Johnson and I organized this week at the ILLC in Amsterdam! Many thanks to all our speakers and participants for such a great event,




June 13, 2024 at 3:19 PM
Feeling very inspired about ✨Using ANNs for Studying Human Language Learning and Processing (ann-humlang.github.io )✨ after the workshop that Tamar Johnson and I organized this week at the ILLC in Amsterdam! Many thanks to all our speakers and participants for such a great event,
A nice session at KNAW tonight looking back on the year since the launch of ChatGPT — Katia is giving a short technical glimpse behind the curtains (🥁) of LLMs right now, that I made some illustrations for! Livestream: www.youtube.com/live/Nn41XWA...

November 30, 2023 at 6:55 PM
A nice session at KNAW tonight looking back on the year since the launch of ChatGPT — Katia is giving a short technical glimpse behind the curtains (🥁) of LLMs right now, that I made some illustrations for! Livestream: www.youtube.com/live/Nn41XWA...
Finally, there's some useful settings you can tune to make things better on your home feed as well!
I currently have this in Home Feed and Thread Preferences settings (forgot which ones are different from the defaults)
I currently have this in Home Feed and Thread Preferences settings (forgot which ones are different from the defaults)


October 22, 2023 at 8:11 PM
Finally, there's some useful settings you can tune to make things better on your home feed as well!
I currently have this in Home Feed and Thread Preferences settings (forgot which ones are different from the defaults)
I currently have this in Home Feed and Thread Preferences settings (forgot which ones are different from the defaults)
