


Matteo Di Cristofaro
@matteodic.bsky.social
Researcher in Corpus Linguistics and Digital Humanities @ UniMoRe. Corpus and Cognitive Linguist, Python & R user. Overall nerd (posts not representative of employers).
Website: https://infogrep.it
Online materials: https://catlism.github.io
Website: https://infogrep.it
Online materials: https://catlism.github.io
Pinned

Data interference: emojis, homoglyphs, and issues of data fidelity in corpora and their results
Tokenisation - "the process of splitting text into atomic parts" (Brezina & Timperley, 2017: 1) - is a crucial step for corpus linguistics, as it provides the basis for any applicable quantitative met...
arxiv.org
Is 😵💫 one token or two?
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
"crashing is not failure; crashing means we were exploring territories that were unexpected by the program."
I love this perspective.
Thanks @switchangel.bsky.social
www.youtube.com/live/mLozqDn...
I love this perspective.
Thanks @switchangel.bsky.social
www.youtube.com/live/mLozqDn...

Coding Rave Music Part ????
YouTube video by Switch Angel
www.youtube.com
November 5, 2025 at 2:28 PM
"crashing is not failure; crashing means we were exploring territories that were unexpected by the program."
I love this perspective.
Thanks @switchangel.bsky.social
www.youtube.com/live/mLozqDn...
I love this perspective.
Thanks @switchangel.bsky.social
www.youtube.com/live/mLozqDn...
Reposted by Matteo Di Cristofaro

I see so much of this in academic funding calls ‘we are looking for projects that explore how AI can help to solve … hunger, violence against women and children, poverty, etc.’ But there’s no space in there to say: ‘um, what if AI is not the right tool for this’

AI is the wrong tool to tackle complex societal & systemic problems. AI4SG is more about PR victories, boosting AI adoption (regardless of merit/usefulness) & laundering accountability for harmful tech, extractive practices, abetting atrocities. yours truly
www.project-syndicate.org/magazine/ai-...
www.project-syndicate.org/magazine/ai-...

The False Promise of “AI for Social Good”
Abeba Birhane refutes industry claims about the technology's potential to solve complex social problems.
www.project-syndicate.org
September 16, 2025 at 5:55 AM
I see so much of this in academic funding calls ‘we are looking for projects that explore how AI can help to solve … hunger, violence against women and children, poverty, etc.’ But there’s no space in there to say: ‘um, what if AI is not the right tool for this’
Reposted by Matteo Di Cristofaro

📖 ToolFindr - Lightweight Explorer for Discovering Research Tools in Digital Humanities
ToolFindr - Lightweight Explorer for Discovering Research Tools in Digital Humanities
[AI Summary]: ToolFindr is an open, community-curated platform for discovering Digital Humanities research tools, built on the Tool Registry Framework and integrating data from Wikidata and the...
ai-humanities.com
September 12, 2025 at 4:13 PM
📖 ToolFindr - Lightweight Explorer for Discovering Research Tools in Digital Humanities
I have recently found "What are embeddings" by @vickiboykis.com, and I think it should become a #corpuslinguistics and #digitalhumanities must-read starting book. Plus it's free under CC by-nc-sa!
vickiboykis.com/what_are_emb...
vickiboykis.com/what_are_emb...

What are embeddings?
A deep-dive into machine learning embeddings.
vickiboykis.com
September 2, 2025 at 11:45 AM
I have recently found "What are embeddings" by @vickiboykis.com, and I think it should become a #corpuslinguistics and #digitalhumanities must-read starting book. Plus it's free under CC by-nc-sa!
vickiboykis.com/what_are_emb...
vickiboykis.com/what_are_emb...
Reposted by Matteo Di Cristofaro

Extreme speech thrives in encrypted spaces, but killing encryption won’t stop it, says a group of researchers who have studied the problem from multiple angles. We need context-driven governance, not backdoors, they say.
Policy Directions on Encrypted Messaging and Extreme Speech | TechPolicy.Press
Encryption, disinformation, and democracy: rethinking policy for messaging apps with rights-based safeguards.
buff.ly
August 22, 2025 at 7:00 PM
Extreme speech thrives in encrypted spaces, but killing encryption won’t stop it, says a group of researchers who have studied the problem from multiple angles. We need context-driven governance, not backdoors, they say.
Reposted by Matteo Di Cristofaro

“Wikipedia editors have had to deal with an onslaught of AI-generated content filled with false information and phony citations. Already, the community of Wikipedia volunteers has mobilized to fight back against AI slop”
www.theverge.com/report/75681...
www.theverge.com/report/75681...

How Wikipedia is fighting AI slop content
Wikipedians are wading through the muck.
www.theverge.com
August 10, 2025 at 4:33 PM
“Wikipedia editors have had to deal with an onslaught of AI-generated content filled with false information and phony citations. Already, the community of Wikipedia volunteers has mobilized to fight back against AI slop”
www.theverge.com/report/75681...
www.theverge.com/report/75681...
Reposted by Matteo Di Cristofaro

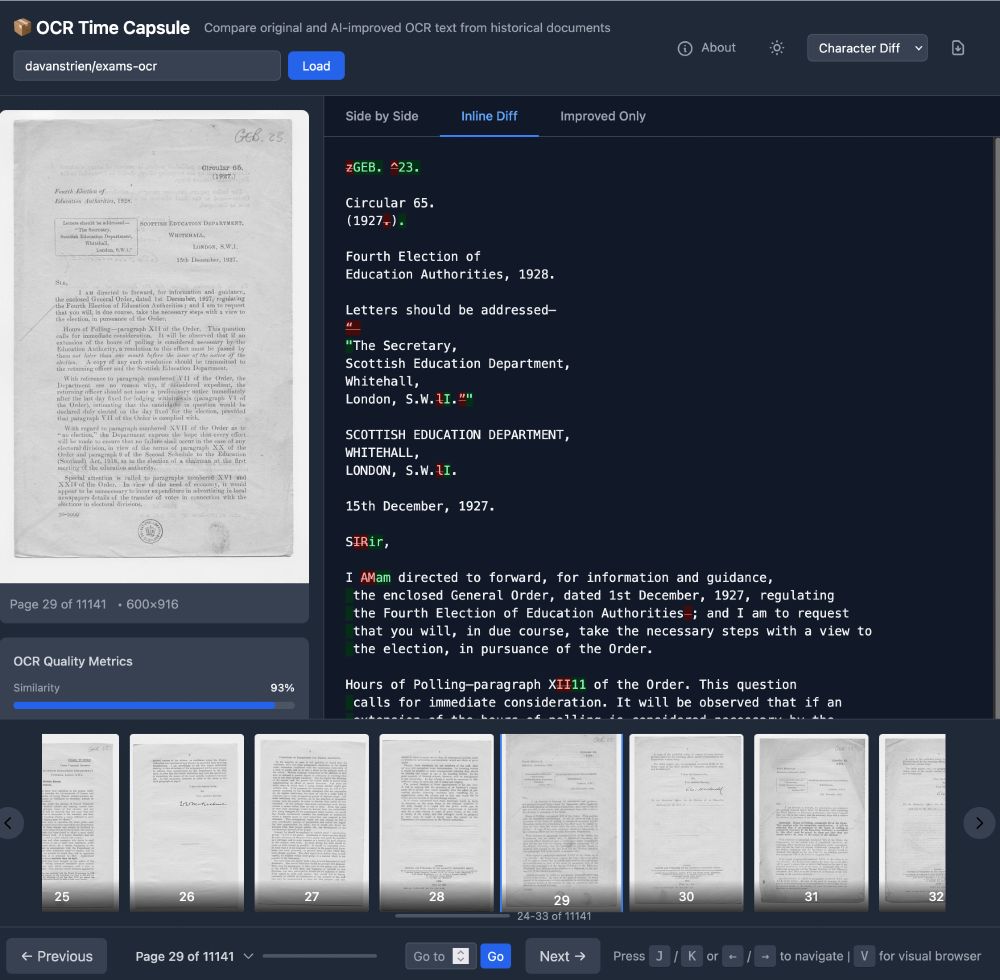
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
August 1, 2025 at 3:09 PM
Many VLM-based OCR models have been released recently. Are they useful for libraries and archives?
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
I made a quick Space to compare VLM OCR with "traditional" OCR using 11k Scottish exam papers from @natlibscot.bsky.social
huggingface.co/spaces/davanstrien/ocr-time-capsule
Reposted by Matteo Di Cristofaro

![4-panel comic. (1) [Person 1 with ponytail flanked by person with short hair and another person speaking into microphone at podium] PERSON 1: In the early 2010s, researchers found that many major scientific results couldn’t be reproduced. (2) PERSON 1: Over a decade into the replication crisis, we wanted to see if today’s studies have become more robust. (3) PERSON 1: Unfortunately, our replication analysis has found exactly the same problems that those 2010s researchers did. (4) [newspaper with image of speakers from previous panels] Headline: Replication Crisis Solved](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:cz73r7iyiqn26upot4jtjdhk/bafkreibwuu57ullc7vacjyno6c5z3gtyakkg2qub6cn3dbbjdpn2kaowmi@jpeg)
July 21, 2025 at 11:54 PM
Reposted by Matteo Di Cristofaro

I believe it is worth interrogating the fundamental forces re-shaping our information spheres away from liberal democracy towards myth, manipulation and magical thinking empowering autocracy and nihilism.
Here’s how it all falls apart—a 🧵 in 6 figures ⬇️
www.protagonist-science.com/p/how-social...
Here’s how it all falls apart—a 🧵 in 6 figures ⬇️
www.protagonist-science.com/p/how-social...
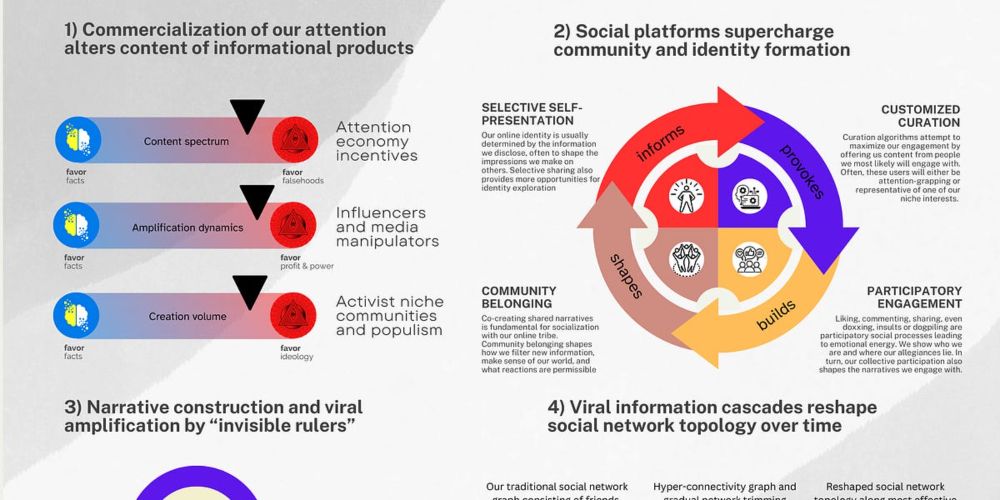
How social media destroys democratic discourse, explained in 6 easy figures
Where we all went wrong
www.protagonist-science.com
July 11, 2025 at 2:20 PM
I believe it is worth interrogating the fundamental forces re-shaping our information spheres away from liberal democracy towards myth, manipulation and magical thinking empowering autocracy and nihilism.
Here’s how it all falls apart—a 🧵 in 6 figures ⬇️
www.protagonist-science.com/p/how-social...
Here’s how it all falls apart—a 🧵 in 6 figures ⬇️
www.protagonist-science.com/p/how-social...
Reposted by Matteo Di Cristofaro

Stuffing ai into everything “isn’t just a forecast, it’s a libidinal fantasy — a capitalist dream of replacing relationships with code and scalable software, while public institutions are gutted in the name of ‘innovation.’”

Regulating AI Isn’t Enough. Let’s Dismantle the Logic That Put It in Schools.
AI in schools isn’t progress — it’s a sign of how far we’ve strayed from the purpose of education.
truthout.org
July 6, 2025 at 2:31 PM
Stuffing ai into everything “isn’t just a forecast, it’s a libidinal fantasy — a capitalist dream of replacing relationships with code and scalable software, while public institutions are gutted in the name of ‘innovation.’”
Reposted by Matteo Di Cristofaro

Reposted by Matteo Di Cristofaro

"The problem with AI isn't that it can do your job. It can't. The problem with AI is that your MBA-brained boss's boss doesn't know how your job works and thinks AI can do your job at fractions of a penny on the dollar, and hears the siren song of 'maximize shareholder value'."
MBA-brain is real.
MBA-brain is real.


July 3, 2025 at 6:57 AM
"The problem with AI isn't that it can do your job. It can't. The problem with AI is that your MBA-brained boss's boss doesn't know how your job works and thinks AI can do your job at fractions of a penny on the dollar, and hears the siren song of 'maximize shareholder value'."
MBA-brain is real.
MBA-brain is real.
Is 😵💫 one token or two?
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
Data interference: emojis, homoglyphs, and issues of data fidelity in corpora and their results
Tokenisation - "the process of splitting text into atomic parts" (Brezina & Timperley, 2017: 1) - is a crucial step for corpus linguistics, as it provides the basis for any applicable quantitative met...
arxiv.org
July 3, 2025 at 7:32 AM
Is 😵💫 one token or two?
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
To a human, it's one. To a corpus tool, it’s often split (😵 + 💫).
And 𝙊𝙉𝙇𝙄𝙉𝙀 ≠ online.
This preprint shows how emojis & homoglyphs challenge tokenisation and distort linguistic evidence.
🔍 arxiv.org/abs/2507.01764
#Emoji #Homoglyphs #CorpusLinguistics #AcademicSky #LangSky
Fellow academics, can anyone help with obtaining an #endorsement on arXiv?
I have a preprint I'd like to upload to Computer Science > Computation and Language (cs.CL), but need someone to endorse my account.
Here's the endorsement link: arxiv.org/auth/endorse...
#corpuslinguistics #linguistics
I have a preprint I'd like to upload to Computer Science > Computation and Language (cs.CL), but need someone to endorse my account.
Here's the endorsement link: arxiv.org/auth/endorse...
#corpuslinguistics #linguistics
arXiv user login
arxiv.org
July 2, 2025 at 2:06 PM
Fellow academics, can anyone help with obtaining an #endorsement on arXiv?
I have a preprint I'd like to upload to Computer Science > Computation and Language (cs.CL), but need someone to endorse my account.
Here's the endorsement link: arxiv.org/auth/endorse...
#corpuslinguistics #linguistics
I have a preprint I'd like to upload to Computer Science > Computation and Language (cs.CL), but need someone to endorse my account.
Here's the endorsement link: arxiv.org/auth/endorse...
#corpuslinguistics #linguistics
Reposted by Matteo Di Cristofaro
Memes can serve as strong indicators of coming mass violence

Memes can serve as strong indicators of coming mass violence
A new study finds that surges in visual propaganda—like memes and doctored images—often precede political violence. By combining AI with expert analysis, researchers tracked manipulated content leading up to Russia’s invasion of Ukraine, revealing early warning signs of instability.
www.psypost.org
June 15, 2025 at 6:22 PM
Memes can serve as strong indicators of coming mass violence
Reposted by Matteo Di Cristofaro


Reposted by Matteo Di Cristofaro
📒The scientific program is out!
Click on the link below to have a look at the speakers and the workshops of our Summer School!
⬇️⬇️⬇️
www.summerschooldigitalhumanities.unimore.it/2025-edition...
Click on the link below to have a look at the speakers and the workshops of our Summer School!
⬇️⬇️⬇️
www.summerschooldigitalhumanities.unimore.it/2025-edition...
Scientific Programme – Summer school digital humanities
www.summerschooldigitalhumanities.unimore.it
May 23, 2025 at 2:11 PM
📒The scientific program is out!
Click on the link below to have a look at the speakers and the workshops of our Summer School!
⬇️⬇️⬇️
www.summerschooldigitalhumanities.unimore.it/2025-edition...
Click on the link below to have a look at the speakers and the workshops of our Summer School!
⬇️⬇️⬇️
www.summerschooldigitalhumanities.unimore.it/2025-edition...
Reposted by Matteo Di Cristofaro
Our Summer School is beginning now with the institutional greetings.

June 3, 2025 at 7:32 AM
Our Summer School is beginning now with the institutional greetings.
Reposted by Matteo Di Cristofaro

Postdoc position open in Zurich -- Prof. Martin Tomasik and I have a joint SNF project on interpretable neural network approaches for large scale, complex item / temporal structure, online learning / cognitive development data.
Please retweet.
tinyurl.com/PostdocGNNSNF
Please retweet.
tinyurl.com/PostdocGNNSNF

May 28, 2025 at 11:16 AM
Postdoc position open in Zurich -- Prof. Martin Tomasik and I have a joint SNF project on interpretable neural network approaches for large scale, complex item / temporal structure, online learning / cognitive development data.
Please retweet.
tinyurl.com/PostdocGNNSNF
Please retweet.
tinyurl.com/PostdocGNNSNF
Reposted by Matteo Di Cristofaro

⏹️ Ending the experiment too early
🎯 Running experiments until you get a hit
🍒 Cherry-picking your results
🔧 Tweaking your data
➗ Not adjusting for multiple comparisons
www.nature.com/articles/d41...
🎯 Running experiments until you get a hit
🍒 Cherry-picking your results
🔧 Tweaking your data
➗ Not adjusting for multiple comparisons
www.nature.com/articles/d41...
P hacking — Five ways it could happen to you
Some data practices can lead to statistically dubious findings. Here’s how to avoid them.
www.nature.com
May 9, 2025 at 3:44 PM
⏹️ Ending the experiment too early
🎯 Running experiments until you get a hit
🍒 Cherry-picking your results
🔧 Tweaking your data
➗ Not adjusting for multiple comparisons
www.nature.com/articles/d41...
🎯 Running experiments until you get a hit
🍒 Cherry-picking your results
🔧 Tweaking your data
➗ Not adjusting for multiple comparisons
www.nature.com/articles/d41...
Reposted by Matteo Di Cristofaro

Academics and Universities have got to formulate a coherent approach to AI and guide their students. Cries of despair and digitally illiterate pronouncements will not reverse the effects of technical innovations.

I seriously thought that students not using their brains and letting them rot inside their heads was going to be the existential problem with ai in academia, but now I see that the death knell is actually the total disruption of good faith and trust between teachers and students
A friend of mine is having trouble with a professor who insists (because of Turnitin) that their paper is 40% AI generated. Out of curiousity I ran a paper I wrote in 2012 through Justdone (Turnitin seems to require me to have an account) and what the fuck
May 9, 2025 at 6:23 AM
Academics and Universities have got to formulate a coherent approach to AI and guide their students. Cries of despair and digitally illiterate pronouncements will not reverse the effects of technical innovations.
Reposted by Matteo Di Cristofaro

Designing a Good Research Practice Roadmap
- a presentation by Fiona Ramage @fionar.bsky.social
youtu.be/dnzRQPOxz1o?...
The event was organised by Edinburgh ReproducibiliTea
- a presentation by Fiona Ramage @fionar.bsky.social
youtu.be/dnzRQPOxz1o?...
The event was organised by Edinburgh ReproducibiliTea

Reproducibilitea – Designing a Good Research Practice Roadmap
YouTube video by Edinburgh ReproducibiliTea
youtu.be
April 29, 2025 at 1:15 PM
Designing a Good Research Practice Roadmap
- a presentation by Fiona Ramage @fionar.bsky.social
youtu.be/dnzRQPOxz1o?...
The event was organised by Edinburgh ReproducibiliTea
- a presentation by Fiona Ramage @fionar.bsky.social
youtu.be/dnzRQPOxz1o?...
The event was organised by Edinburgh ReproducibiliTea
Reposted by Matteo Di Cristofaro

With Canada’s election just days away, the continued appearance of deepfake ads reveals a serious flaw in Meta’s ad-review system. If fraudsters can repeatedly bypass detection, it suggests the platform’s current safeguards are not equipped to catch even basic forms of manipulation...
The Hidden Game: How Scammers Use “Chameleon Ads” to Bypass Meta’s Moderation socialmedialab.ca/2025/04/21/t...

The Hidden Game: How Scammers Use "Chameleon Ads" to Bypass Meta's Moderation - Social Media Lab
Over the last few weeks, a series of stories by The Guardian, CBC, and The Logic has highlighted an explosion of fraudulent Facebook and Instagram ads that mimic the likeness of high-profile Canadian ...
socialmedialab.ca
April 26, 2025 at 12:27 PM
With Canada’s election just days away, the continued appearance of deepfake ads reveals a serious flaw in Meta’s ad-review system. If fraudsters can repeatedly bypass detection, it suggests the platform’s current safeguards are not equipped to catch even basic forms of manipulation...
Reposted by Matteo Di Cristofaro

"Twitter became 4chan, then the 4chanified Twitter became the United States government. Its usefulness as an ammo dump in the culture war was diminished when they were saying things you would now hear every day on Twitter," @bencollins.bsky.social told WIRED.

4chan Is Dead. Its Toxic Legacy Is Everywhere
It’s likely that there will never be a site like 4chan again. But everything now—from X and YouTube to global politics—seems to carry its toxic legacy.
www.wired.com
April 22, 2025 at 3:31 PM
"Twitter became 4chan, then the 4chanified Twitter became the United States government. Its usefulness as an ammo dump in the culture war was diminished when they were saying things you would now hear every day on Twitter," @bencollins.bsky.social told WIRED.