



Manuel
@manuelnlp.bsky.social
NLP - mostly representation learning #NLP #NLProc
Reposted by Manuel

📝 Discontinuation of the MS Word Template
ARR will now fully adopt the LaTeX template to streamline formatting and reduce review workload.
Starting March 2026, submissions using the MS Word template will be desk-rejected.
Check details here: aclrollingreview.org/discontinuat...
#ARR #NLProc
ARR will now fully adopt the LaTeX template to streamline formatting and reduce review workload.
Starting March 2026, submissions using the MS Word template will be desk-rejected.
Check details here: aclrollingreview.org/discontinuat...
#ARR #NLProc

Discontinuation of the MS Word Template
ARR abandons the MS Word Template for conference submissions. The submissions based on the Word template will be desk-rejected starting from March 2026.
aclrollingreview.org
October 30, 2025 at 9:40 PM
📝 Discontinuation of the MS Word Template
ARR will now fully adopt the LaTeX template to streamline formatting and reduce review workload.
Starting March 2026, submissions using the MS Word template will be desk-rejected.
Check details here: aclrollingreview.org/discontinuat...
#ARR #NLProc
ARR will now fully adopt the LaTeX template to streamline formatting and reduce review workload.
Starting March 2026, submissions using the MS Word template will be desk-rejected.
Check details here: aclrollingreview.org/discontinuat...
#ARR #NLProc
Reposted by Manuel

The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵

October 20, 2025 at 2:36 PM
The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Reposted by Manuel

🧪 A new computer science conference, Agents4Science, will feature papers written and peer-reviewed entirely by AI agents. The event serves as a sandbox to evaluate the quality of machine-generated research and its review process.
#MLSky
#MLSky

AI bots wrote and reviewed all papers at this conference
Event will assess how reviews by models compare with those written by humans.
www.nature.com
October 15, 2025 at 3:33 PM
🧪 A new computer science conference, Agents4Science, will feature papers written and peer-reviewed entirely by AI agents. The event serves as a sandbox to evaluate the quality of machine-generated research and its review process.
#MLSky
#MLSky
Reposted by Manuel
✈️ Visa Letter Requests for ACL 2026
If you intend to commit your paper to ACL 2026 and require an invitation letter for visa purposes, please fill out the visa request form as soon as possible.
(docs.google.com/forms/d/e/1F...)
#ARR #ACL #NLProc
If you intend to commit your paper to ACL 2026 and require an invitation letter for visa purposes, please fill out the visa request form as soon as possible.
(docs.google.com/forms/d/e/1F...)
#ARR #ACL #NLProc

ACL 2026 Visa Invitation Letter Request
Please use this form to request a visa invitation letter. The letter will be sent to the email address provided below.
docs.google.com
October 14, 2025 at 3:27 PM
✈️ Visa Letter Requests for ACL 2026
If you intend to commit your paper to ACL 2026 and require an invitation letter for visa purposes, please fill out the visa request form as soon as possible.
(docs.google.com/forms/d/e/1F...)
#ARR #ACL #NLProc
If you intend to commit your paper to ACL 2026 and require an invitation letter for visa purposes, please fill out the visa request form as soon as possible.
(docs.google.com/forms/d/e/1F...)
#ARR #ACL #NLProc
Reposted by Manuel

🚀 𝗟𝗮𝘁𝗲𝘀𝘁 𝗣𝗲𝗲𝗿 𝗥𝗲𝘃𝗶𝗲𝘄 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗥𝗲𝗹𝗲𝗮𝘀𝗲 𝗳𝗿𝗼𝗺 𝗔𝗥𝗥 𝟮𝟬𝟮𝟱!
tudatalib.ulb.tu-darmstadt.de/handle/tudat...
📊 𝗡𝗲𝘄𝗹𝘆 𝗮𝗱𝗱𝗲𝗱 𝗔𝗖𝗟 𝟮𝟬𝟮𝟱 𝗱𝗮𝘁𝗮:
✅ 𝟮𝗸 papers
✅ 𝟮𝗸 reviews
✅ 𝟴𝟰𝟵 meta-reviews
✅ 𝟭.𝟱𝗸 papers with rebuttals
(1/🧵)
tudatalib.ulb.tu-darmstadt.de/handle/tudat...
📊 𝗡𝗲𝘄𝗹𝘆 𝗮𝗱𝗱𝗲𝗱 𝗔𝗖𝗟 𝟮𝟬𝟮𝟱 𝗱𝗮𝘁𝗮:
✅ 𝟮𝗸 papers
✅ 𝟮𝗸 reviews
✅ 𝟴𝟰𝟵 meta-reviews
✅ 𝟭.𝟱𝗸 papers with rebuttals
(1/🧵)

October 8, 2025 at 6:58 AM
🚀 𝗟𝗮𝘁𝗲𝘀𝘁 𝗣𝗲𝗲𝗿 𝗥𝗲𝘃𝗶𝗲𝘄 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗥𝗲𝗹𝗲𝗮𝘀𝗲 𝗳𝗿𝗼𝗺 𝗔𝗥𝗥 𝟮𝟬𝟮𝟱!
tudatalib.ulb.tu-darmstadt.de/handle/tudat...
📊 𝗡𝗲𝘄𝗹𝘆 𝗮𝗱𝗱𝗲𝗱 𝗔𝗖𝗟 𝟮𝟬𝟮𝟱 𝗱𝗮𝘁𝗮:
✅ 𝟮𝗸 papers
✅ 𝟮𝗸 reviews
✅ 𝟴𝟰𝟵 meta-reviews
✅ 𝟭.𝟱𝗸 papers with rebuttals
(1/🧵)
tudatalib.ulb.tu-darmstadt.de/handle/tudat...
📊 𝗡𝗲𝘄𝗹𝘆 𝗮𝗱𝗱𝗲𝗱 𝗔𝗖𝗟 𝟮𝟬𝟮𝟱 𝗱𝗮𝘁𝗮:
✅ 𝟮𝗸 papers
✅ 𝟮𝗸 reviews
✅ 𝟴𝟰𝟵 meta-reviews
✅ 𝟭.𝟱𝗸 papers with rebuttals
(1/🧵)
Reposted by Manuel

Google just released a 270M parameter Gemma model. As a tiny model lover I'm excited. Models in this size class are usually barely coherent, I'll give it a try today to see how this does. developers.googleblog.com/en/introduci...

August 14, 2025 at 4:39 PM
Google just released a 270M parameter Gemma model. As a tiny model lover I'm excited. Models in this size class are usually barely coherent, I'll give it a try today to see how this does. developers.googleblog.com/en/introduci...
Reposted by Manuel
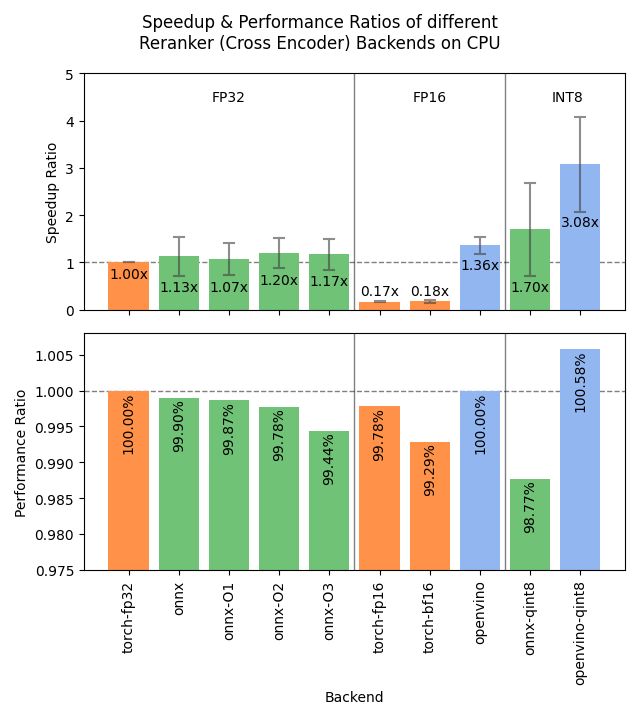
I just released Sentence Transformers v4.1; featuring ONNX and OpenVINO backends for rerankers offering 2-3x speedups and improved hard negatives mining which helps prepare stronger training datasets.
Details in 🧵
Details in 🧵
April 15, 2025 at 1:54 PM
I just released Sentence Transformers v4.1; featuring ONNX and OpenVINO backends for rerankers offering 2-3x speedups and improved hard negatives mining which helps prepare stronger training datasets.
Details in 🧵
Details in 🧵
Reposted by Manuel

🗣️Call for emergency reviewers
I am serving as an AC for #ICML2025, seeking emergency reviewers for two submissions
Are you an expert of Knowledge Distillation or AI4Science?
If so, send me DM with your Google Scholar profile and OpenReview profile
Thank you!
I am serving as an AC for #ICML2025, seeking emergency reviewers for two submissions
Are you an expert of Knowledge Distillation or AI4Science?
If so, send me DM with your Google Scholar profile and OpenReview profile
Thank you!

a cat holding a sign that says help
ALT: a cat holding a sign that says help
media.tenor.com
March 20, 2025 at 5:25 AM
🗣️Call for emergency reviewers
I am serving as an AC for #ICML2025, seeking emergency reviewers for two submissions
Are you an expert of Knowledge Distillation or AI4Science?
If so, send me DM with your Google Scholar profile and OpenReview profile
Thank you!
I am serving as an AC for #ICML2025, seeking emergency reviewers for two submissions
Are you an expert of Knowledge Distillation or AI4Science?
If so, send me DM with your Google Scholar profile and OpenReview profile
Thank you!
Reposted by Manuel
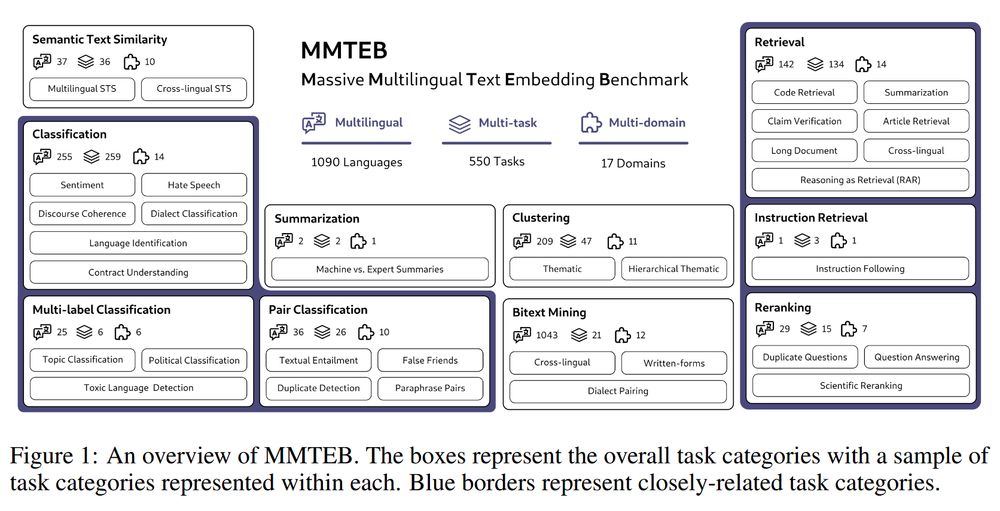
We've just released MMTEB, our multilingual upgrade to the MTEB Embedding Benchmark!
It's a huge collaboration between 56 universities, labs, and organizations, resulting in a massive benchmark of 1000+ languages, 500+ tasks, and a dozen+ domains.
Details in 🧵
It's a huge collaboration between 56 universities, labs, and organizations, resulting in a massive benchmark of 1000+ languages, 500+ tasks, and a dozen+ domains.
Details in 🧵
February 21, 2025 at 3:06 PM
We've just released MMTEB, our multilingual upgrade to the MTEB Embedding Benchmark!
It's a huge collaboration between 56 universities, labs, and organizations, resulting in a massive benchmark of 1000+ languages, 500+ tasks, and a dozen+ domains.
Details in 🧵
It's a huge collaboration between 56 universities, labs, and organizations, resulting in a massive benchmark of 1000+ languages, 500+ tasks, and a dozen+ domains.
Details in 🧵
Reposted by Manuel

Can Cross Encoders Produce Useful Sentence Embeddings?
IBM discovered that early cross encoders layers can produce effective sentence embeddings, enabling 5.15x faster inference while maintaining comparable accuracy to full dual encoders.
📝 arxiv.org/abs/2502.03552
IBM discovered that early cross encoders layers can produce effective sentence embeddings, enabling 5.15x faster inference while maintaining comparable accuracy to full dual encoders.
📝 arxiv.org/abs/2502.03552

Can Cross Encoders Produce Useful Sentence Embeddings?
Cross encoders (CEs) are trained with sentence pairs to detect relatedness. As CEs require sentence pairs at inference, the prevailing view is that they can only be used as re-rankers in information r...
arxiv.org
February 7, 2025 at 3:34 AM
Can Cross Encoders Produce Useful Sentence Embeddings?
IBM discovered that early cross encoders layers can produce effective sentence embeddings, enabling 5.15x faster inference while maintaining comparable accuracy to full dual encoders.
📝 arxiv.org/abs/2502.03552
IBM discovered that early cross encoders layers can produce effective sentence embeddings, enabling 5.15x faster inference while maintaining comparable accuracy to full dual encoders.
📝 arxiv.org/abs/2502.03552
Reposted by Manuel

Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...

Distiling DeepSeek reasoning to ModernBERT classifiers
How can we use the reasoning ability of DeepSeek to generate synthetic labels for fine tuning a ModernBERT model?
danielvanstrien.xyz
January 29, 2025 at 10:07 AM
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Reposted by Manuel

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

January 28, 2025 at 2:55 PM
People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Reposted by Manuel

I wrote about a new AI evaluation called "Humanity's Last Exam," a collection of 3,000 questions submitted by leading academics to try to stump leading AI models, which mostly find today's college-level tests too easy.
www.nytimes.com/2025/01/23/t...
www.nytimes.com/2025/01/23/t...

A Test So Hard No AI System Can Pass It — Yet (Gift Article)
The creators of a new test called “Humanity’s Last Exam” argue we may soon lose the ability to create tests hard enough for A.I. models.
www.nytimes.com
January 23, 2025 at 4:41 PM
I wrote about a new AI evaluation called "Humanity's Last Exam," a collection of 3,000 questions submitted by leading academics to try to stump leading AI models, which mostly find today's college-level tests too easy.
www.nytimes.com/2025/01/23/t...
www.nytimes.com/2025/01/23/t...
Reposted by Manuel
I just released Sentence Transformers v3.4.0, featuring a memory leak fix (memory not being cleared upon model & trainer deletion), compatibility between the powerful Cached... losses and the Matryoshka loss modifier, and a bunch of fixes & small features.
Details in 🧵
Details in 🧵
January 23, 2025 at 4:44 PM
I just released Sentence Transformers v3.4.0, featuring a memory leak fix (memory not being cleared upon model & trainer deletion), compatibility between the powerful Cached... losses and the Matryoshka loss modifier, and a bunch of fixes & small features.
Details in 🧵
Details in 🧵
Reposted by Manuel

Disappointed with #ICLR or #NAACL reviews? Consider submitting your work at #Repl4NLP, whether it's full papers, extended abstracts, or cross-submissions. 🔥
Details on submissions 👉 sites.google.com/view/repl4nl...
⏰ Deadline January 30
Details on submissions 👉 sites.google.com/view/repl4nl...
⏰ Deadline January 30
10th Workshop on Representation Learning for NLP - Call for Papers
The 10th Workshop on Representation Learning for NLP (RepL4NLP 2025), co-located with NAACL 2025 in Albuquerque, New Mexico, invites papers of a theoretical or experimental nature describing recent ad...
sites.google.com
January 23, 2025 at 4:30 PM
Disappointed with #ICLR or #NAACL reviews? Consider submitting your work at #Repl4NLP, whether it's full papers, extended abstracts, or cross-submissions. 🔥
Details on submissions 👉 sites.google.com/view/repl4nl...
⏰ Deadline January 30
Details on submissions 👉 sites.google.com/view/repl4nl...
⏰ Deadline January 30
Reposted by Manuel

Microsoft’s latest small language model - phi-4 - is open source and now available on Hugging Face techcommunity.microsoft.com/blog/aiplatf...
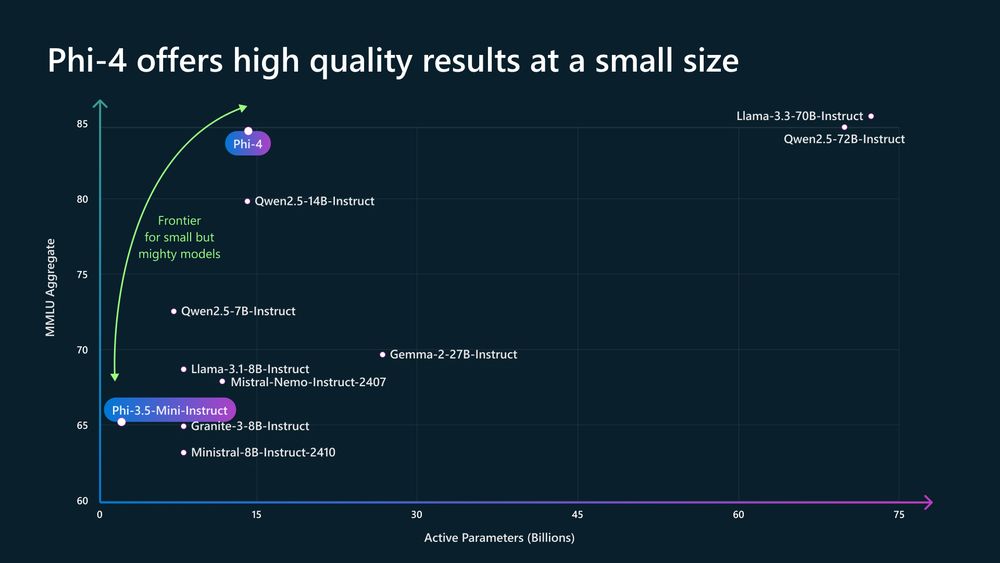
Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub
Today we are introducing Phi-4, our 14B parameter state-of-the-art small language model (SLM) that excels at complex reasoning in areas such as math, in...
https://techcommunity.microsoft.com/blog/aiplatformblog/introducing-phi-4-microsoft’s-newest-small-language-model-specializing-in-comple/4357090
January 9, 2025 at 3:40 PM
Microsoft’s latest small language model - phi-4 - is open source and now available on Hugging Face techcommunity.microsoft.com/blog/aiplatf...
Reposted by Manuel
LLMs are Also Effective Embedding Models: An In-depth Overview
Provides a comprehensive analysis on adopting LLMs as embedding models, examining both zero-shot prompting and tuning strategies to derive competitive text embeddings vs traditional models.
📝 arxiv.org/abs/2412.12591
Provides a comprehensive analysis on adopting LLMs as embedding models, examining both zero-shot prompting and tuning strategies to derive competitive text embeddings vs traditional models.
📝 arxiv.org/abs/2412.12591
LLMs are Also Effective Embedding Models: An In-depth Overview
Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gaine...
arxiv.org
December 18, 2024 at 6:40 AM
LLMs are Also Effective Embedding Models: An In-depth Overview
Provides a comprehensive analysis on adopting LLMs as embedding models, examining both zero-shot prompting and tuning strategies to derive competitive text embeddings vs traditional models.
📝 arxiv.org/abs/2412.12591
Provides a comprehensive analysis on adopting LLMs as embedding models, examining both zero-shot prompting and tuning strategies to derive competitive text embeddings vs traditional models.
📝 arxiv.org/abs/2412.12591
Reposted by Manuel

The upside of A.I. hallucination
gift link www.nytimes.com/2024/12/23/s...
gift link www.nytimes.com/2024/12/23/s...
How Hallucinatory A.I. Helps Science Dream Up Big Breakthroughs (Gift Article)
Hallucinations, a bane of popular A.I. programs, turn out to be a boon for venturesome scientists eager to push back the frontiers of human knowledge.
www.nytimes.com
December 24, 2024 at 3:05 PM
The upside of A.I. hallucination
gift link www.nytimes.com/2024/12/23/s...
gift link www.nytimes.com/2024/12/23/s...
Good blog post on good old encoder-style models.
Glad to see ModernBERT recently brought something new to the field. So don't count BERT as GOFAI yet.
www.yitay.net/blog/model-a...
Glad to see ModernBERT recently brought something new to the field. So don't count BERT as GOFAI yet.
www.yitay.net/blog/model-a...

What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives — Yi Tay
A Blogpost series about Model Architectures Part 1: What happened to BERT and T5? Thoughts on Transformer Encoders, PrefixLM and Denoising objectives
www.yitay.net
December 24, 2024 at 12:16 PM
Good blog post on good old encoder-style models.
Glad to see ModernBERT recently brought something new to the field. So don't count BERT as GOFAI yet.
www.yitay.net/blog/model-a...
Glad to see ModernBERT recently brought something new to the field. So don't count BERT as GOFAI yet.
www.yitay.net/blog/model-a...
Reposted by Manuel

Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social


December 17, 2024 at 3:48 PM
Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
Reposted by Manuel
Unsure where to submit your next research paper to now that aideadlin.es is not updated anymore? And let’s be honest, is the location not as important as the conference itself?
🗺️ Check out my latest side-project: deadlines.pieter.ai
🗺️ Check out my latest side-project: deadlines.pieter.ai
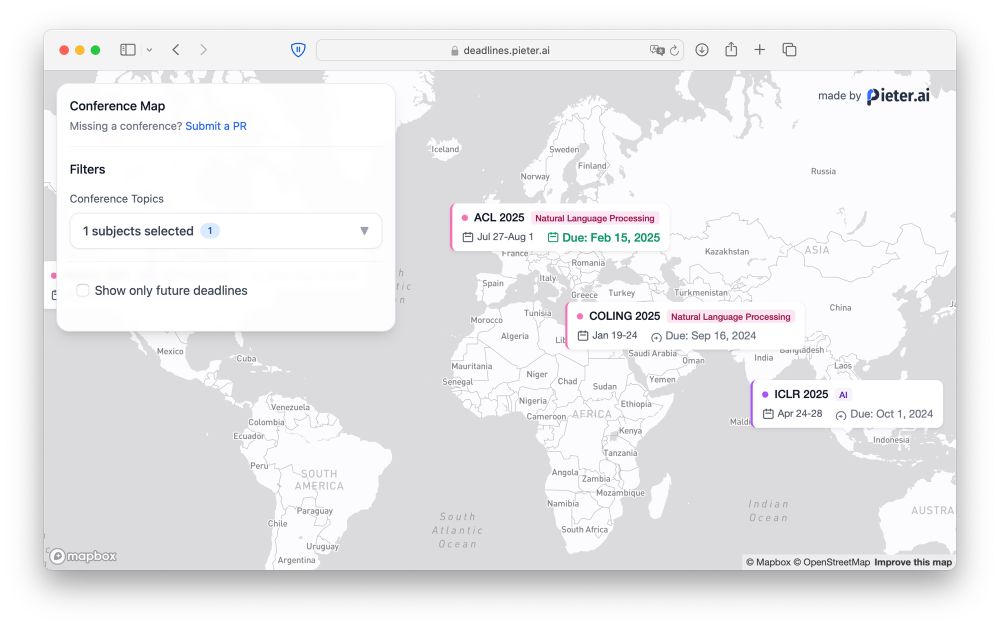
Computer Science Conference Deadlines Map
Interactive world map of Computer Science, AI, and ML conference deadlines
deadlines.pieter.ai
December 23, 2024 at 2:39 PM
Unsure where to submit your next research paper to now that aideadlin.es is not updated anymore? And let’s be honest, is the location not as important as the conference itself?
🗺️ Check out my latest side-project: deadlines.pieter.ai
🗺️ Check out my latest side-project: deadlines.pieter.ai
Reposted by Manuel
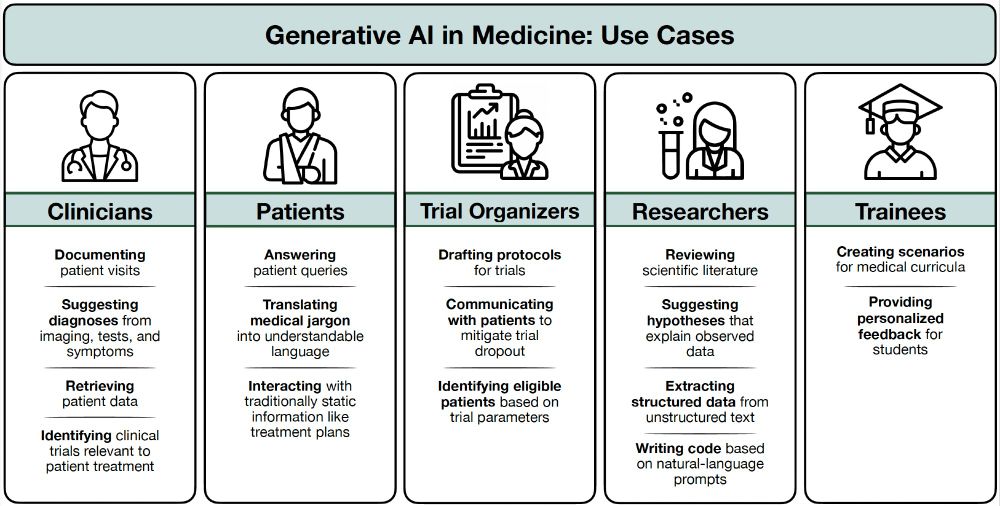
🧪 New pre-print explores generative AI’s in medicine, highlighting applications for clinicians, patients, researchers, and educators. It also addresses challenges like privacy, transparency, and equity.
Additional details from the author linked below.
🩺🖥️
Direct link: arxiv.org/abs/2412.10337
Additional details from the author linked below.
🩺🖥️
Direct link: arxiv.org/abs/2412.10337

We have a new review on generative AI in medicine, to appear in the Annual Review of Biomedical Data Science! We cover over 250 papers in the recent literature to provide an updated overview of use cases and challenges for generative AI in medicine.
December 22, 2024 at 3:03 PM
🧪 New pre-print explores generative AI’s in medicine, highlighting applications for clinicians, patients, researchers, and educators. It also addresses challenges like privacy, transparency, and equity.
Additional details from the author linked below.
🩺🖥️
Direct link: arxiv.org/abs/2412.10337
Additional details from the author linked below.
🩺🖥️
Direct link: arxiv.org/abs/2412.10337
Reposted by Manuel

Instead of listing my publications, as the year draws to an end, I want to shine the spotlight on the commonplace assumption that productivity must always increase. Good research is disruptive and thinking time is central to high quality scholarship and necessary for disruptive research.

December 20, 2024 at 11:18 AM
Instead of listing my publications, as the year draws to an end, I want to shine the spotlight on the commonplace assumption that productivity must always increase. Good research is disruptive and thinking time is central to high quality scholarship and necessary for disruptive research.
Reposted by Manuel

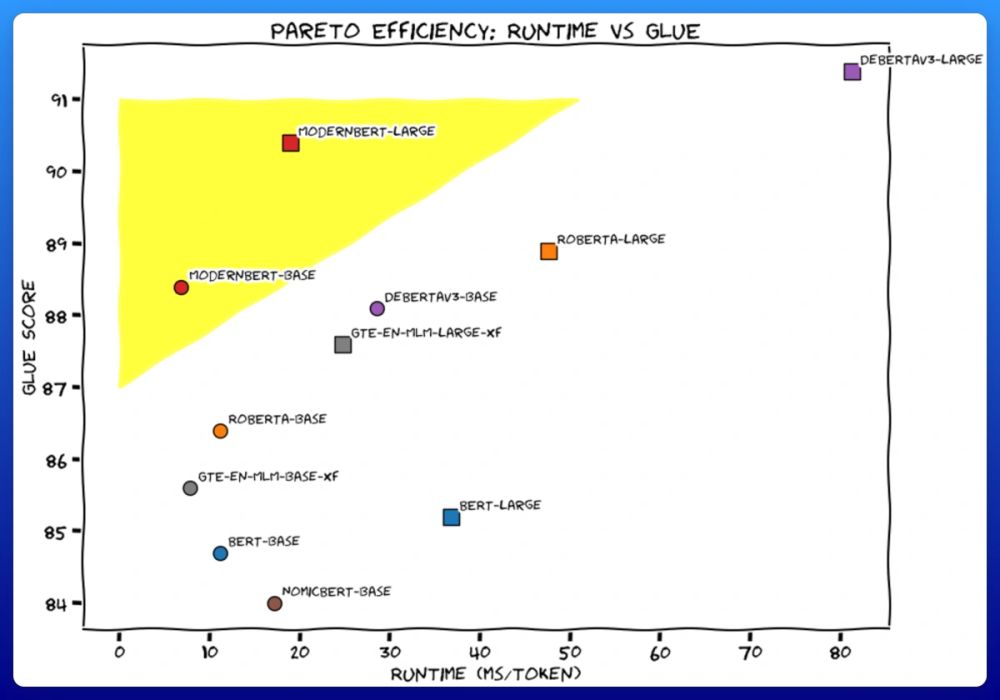
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted by Manuel

Now also out on Arxiv:
www.arxiv.org/abs/2412.12119
www.arxiv.org/abs/2412.12119
December 18, 2024 at 8:23 AM
Now also out on Arxiv:
www.arxiv.org/abs/2412.12119
www.arxiv.org/abs/2412.12119