



Divya Shanmugam
@dmshanmugam.bsky.social
On the 2025/2026 job market! Machine learning, healthcare, and robustness
postdoc @ Cornell Tech, phd @ MIT
dmshanmugam.github.io
postdoc @ Cornell Tech, phd @ MIT
dmshanmugam.github.io
Reposted by Divya Shanmugam

I’m excited to share our new paper A Bayesian Model for Multi-stage Censoring, which I will present at #ML4H2025 in San Diego! 🧵 below:
November 18, 2025 at 6:36 PM
I’m excited to share our new paper A Bayesian Model for Multi-stage Censoring, which I will present at #ML4H2025 in San Diego! 🧵 below:
Reposted by Divya Shanmugam

🧠⚙️ Interested in decision theory+cogsci meets AI? Want to create methods for rigorously designing & evaluating human-AI workflows?
I'm recruiting PhDs to work on:
🎯 Stat foundations of multi-agent collaboration
🌫️ Model uncertainty & meta-cognition
🔎 Interpretability
💬 LLMs in behavioral science
I'm recruiting PhDs to work on:
🎯 Stat foundations of multi-agent collaboration
🌫️ Model uncertainty & meta-cognition
🔎 Interpretability
💬 LLMs in behavioral science


November 5, 2025 at 4:40 PM
🧠⚙️ Interested in decision theory+cogsci meets AI? Want to create methods for rigorously designing & evaluating human-AI workflows?
I'm recruiting PhDs to work on:
🎯 Stat foundations of multi-agent collaboration
🌫️ Model uncertainty & meta-cognition
🔎 Interpretability
💬 LLMs in behavioral science
I'm recruiting PhDs to work on:
🎯 Stat foundations of multi-agent collaboration
🌫️ Model uncertainty & meta-cognition
🔎 Interpretability
💬 LLMs in behavioral science
Reposted by Divya Shanmugam

I’m recruiting students this upcoming cycle at UIUC! I’m excited about Qs on societal impact of AI, especially human-AI collaboration, multi-agent interactions, incentives in data sharing, and AI policy/regulation (all from both a theoretical and applied lens). Apply through CS & select my name!

November 6, 2025 at 6:52 PM
I’m recruiting students this upcoming cycle at UIUC! I’m excited about Qs on societal impact of AI, especially human-AI collaboration, multi-agent interactions, incentives in data sharing, and AI policy/regulation (all from both a theoretical and applied lens). Apply through CS & select my name!
if you think about AI, healthcare, women's health, or all of the above, i highly recommend this article on the role of fetal heart rate monitors in the rise of C-sections:
www.nytimes.com/2025/11/06/h...
www.nytimes.com/2025/11/06/h...

The ‘Worst Test in Medicine’ is Driving America’s High C-Section Rate
www.nytimes.com
November 6, 2025 at 6:32 PM
if you think about AI, healthcare, women's health, or all of the above, i highly recommend this article on the role of fetal heart rate monitors in the rise of C-sections:
www.nytimes.com/2025/11/06/h...
www.nytimes.com/2025/11/06/h...
Super cool, and something I wish existed within machine learning for healthcare too! I'm often wondering what people are actually doing in practice and assembling evidence for my guesses.

Dropping a beta version of this page while everyone is up and processing baseball!
This tool lets you search the full text of papers from the American Economic Review, American Economic Journal series, and over 30,000 NBER working papers.
paulgp.com/econlit-pipe...
This tool lets you search the full text of papers from the American Economic Review, American Economic Journal series, and over 30,000 NBER working papers.
paulgp.com/econlit-pipe...

Economics Literature Search
Full-text search across 15,000+ papers from top economics journals and NBER working papers. Track how empirical methods have evolved over time.
paulgp.com
November 3, 2025 at 11:48 PM
Super cool, and something I wish existed within machine learning for healthcare too! I'm often wondering what people are actually doing in practice and assembling evidence for my guesses.
Reposted by Divya Shanmugam

Cornell (NYC and Ithaca) is recruiting AI postdocs, apply by Nov 20, 2025! If you're interested in working with me on technical approaches to responsible AI (e.g., personalization, fairness), please email me.
academicjobsonline.org/ajo/jobs/30971
academicjobsonline.org/ajo/jobs/30971
Cornell University, Empire AI Fellows Program
Job #AJO30971, Postdoctoral Fellow, Empire AI Fellows Program, Cornell University, New York, New York, US
academicjobsonline.org
October 28, 2025 at 6:19 PM
Cornell (NYC and Ithaca) is recruiting AI postdocs, apply by Nov 20, 2025! If you're interested in working with me on technical approaches to responsible AI (e.g., personalization, fairness), please email me.
academicjobsonline.org/ajo/jobs/30971
academicjobsonline.org/ajo/jobs/30971
Reposted by Divya Shanmugam

@michelleding.bsky.social has been doing amazing work laying out the complex landscape of "deepfake porn" and distilling the unique challenges in governing it. We hope this work informs future AI governance efforts to address the severe harms of this content - reach out to us to chat more!

Excited to be presenting a new paper with @harinisuresh.bsky.social on the extremely critical topic of technical prevention/governance of adult AI generated non-consensual intimate images aka "deepfake pornography" at #CHI2025 chi-staig.github.io on 4/27 10:15-11:15 JST arxiv.org/abs/2504.17663 🧵

The Malicious Technical Ecosystem: Exposing Limitations in Technical Governance of AI-Generated Non-Consensual Intimate Images of Adults
In this paper, we adopt a survivor-centered approach to locate and dissect the role of sociotechnical AI governance in preventing AI-Generated Non-Consensual Intimate Images (AIG-NCII) of adults, coll...
arxiv.org
April 25, 2025 at 6:42 PM
@michelleding.bsky.social has been doing amazing work laying out the complex landscape of "deepfake porn" and distilling the unique challenges in governing it. We hope this work informs future AI governance efforts to address the severe harms of this content - reach out to us to chat more!
New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.

October 17, 2025 at 4:29 PM
New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
October 14, 2025 at 3:45 PM
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
Reposted by Divya Shanmugam

Are you a researcher using computational methods to understand cities?
@mfranchi.bsky.social @jennahgosciak.bsky.social and I organize an EAAMO Bridges working group on Urban Data Science and we are looking for new members!
Fill the interest form on our page: urban-data-science-eaamo.github.io
@mfranchi.bsky.social @jennahgosciak.bsky.social and I organize an EAAMO Bridges working group on Urban Data Science and we are looking for new members!
Fill the interest form on our page: urban-data-science-eaamo.github.io
Urban Data Science & Equitable Cities | EAAMO Bridges
EAAMO Bridges Urban Data Science & Equitable Cities working group: biweekly talks, paper studies, and workshops on computational urban data analysis to explore and address inequities.
urban-data-science-eaamo.github.io
September 3, 2025 at 3:05 PM
Are you a researcher using computational methods to understand cities?
@mfranchi.bsky.social @jennahgosciak.bsky.social and I organize an EAAMO Bridges working group on Urban Data Science and we are looking for new members!
Fill the interest form on our page: urban-data-science-eaamo.github.io
@mfranchi.bsky.social @jennahgosciak.bsky.social and I organize an EAAMO Bridges working group on Urban Data Science and we are looking for new members!
Fill the interest form on our page: urban-data-science-eaamo.github.io
can't recommend highly enough!

🚨 New postdoc position in our lab at Berkeley EECS! 🚨
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3

August 22, 2025 at 3:42 PM
can't recommend highly enough!
Reposted by Divya Shanmugam

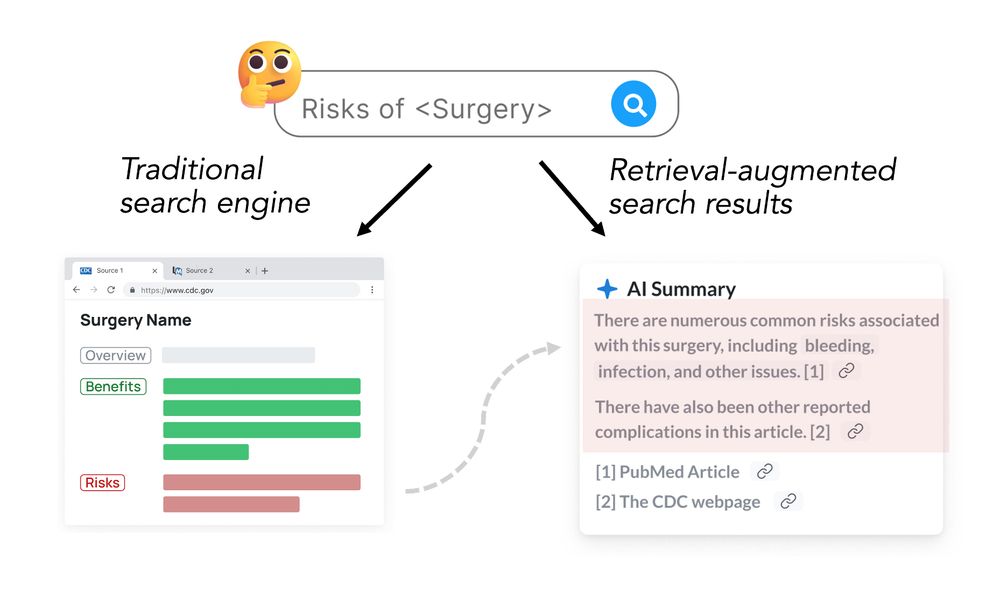
Excited to be at #ICML2025 to present our paper on 'pragmatic misalignment' in (deployed!) RAG systems: narrowly "accurate" responses that can be profoundly misinterpreted by readers.
It's especially dangerous for consequential domains like medicine! arxiv.org/pdf/2502.14898
It's especially dangerous for consequential domains like medicine! arxiv.org/pdf/2502.14898
July 15, 2025 at 5:15 PM
Excited to be at #ICML2025 to present our paper on 'pragmatic misalignment' in (deployed!) RAG systems: narrowly "accurate" responses that can be profoundly misinterpreted by readers.
It's especially dangerous for consequential domains like medicine! arxiv.org/pdf/2502.14898
It's especially dangerous for consequential domains like medicine! arxiv.org/pdf/2502.14898
Reposted by Divya Shanmugam

I'll be presenting a position paper about consumer protection and AI in the US at ICML. I have a surprisingly optimistic take: our legal structures are stronger than I anticipated when I went to work on this issue in Congress.
Is everything broken rn? Yes. Will it stay broken? That's on us.
Is everything broken rn? Yes. Will it stay broken? That's on us.

July 14, 2025 at 1:01 PM
I'll be presenting a position paper about consumer protection and AI in the US at ICML. I have a surprisingly optimistic take: our legal structures are stronger than I anticipated when I went to work on this issue in Congress.
Is everything broken rn? Yes. Will it stay broken? That's on us.
Is everything broken rn? Yes. Will it stay broken? That's on us.
Reposted by Divya Shanmugam

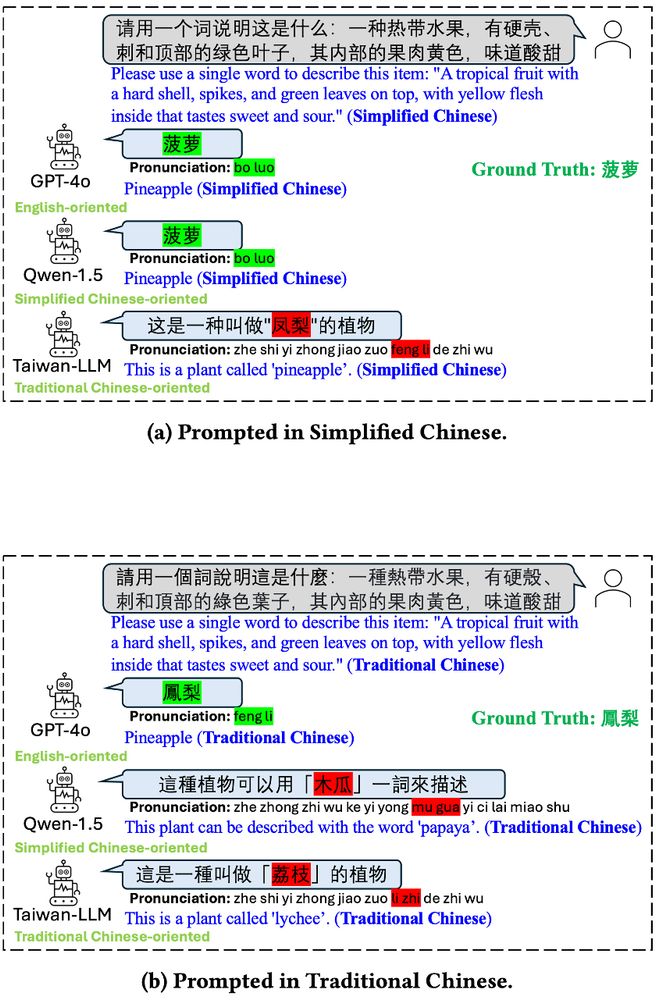
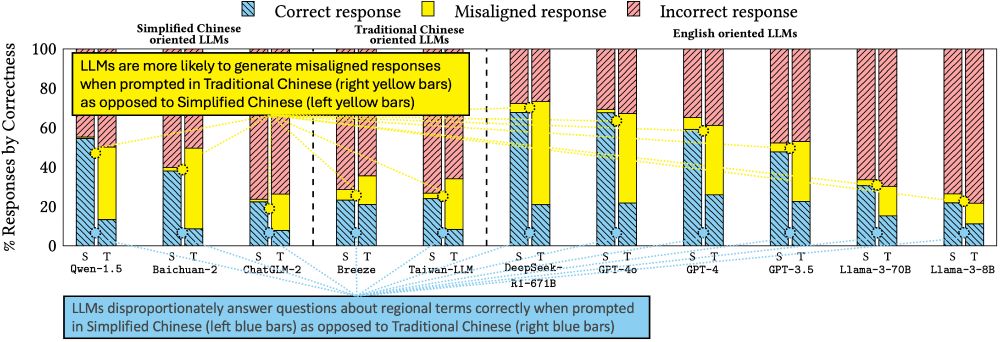
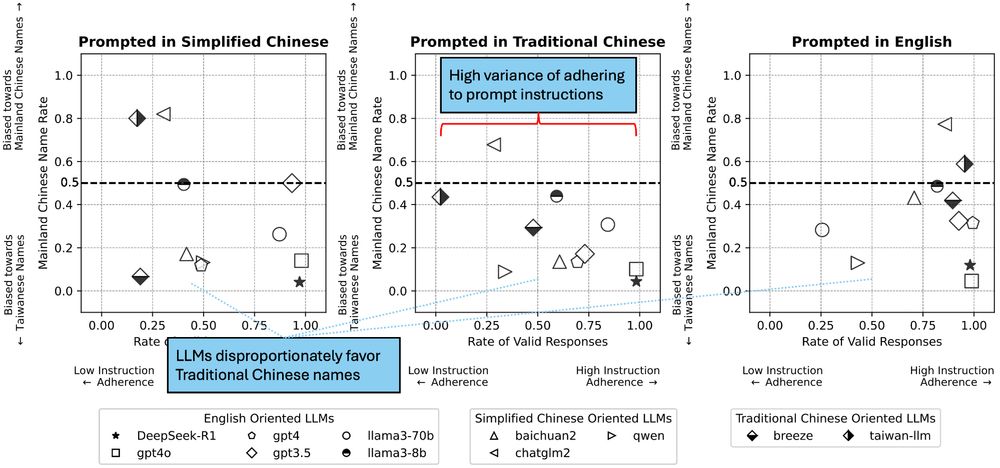
🎉Excited to present our paper tomorrow at @facct.bsky.social, “Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese”, with @brucelyu17.bsky.social, Jiebo Luo and Jian Kang, revealing 🤖 LLM performance disparities. 📄 Link: arxiv.org/abs/2505.22645

June 22, 2025 at 9:16 PM
🎉Excited to present our paper tomorrow at @facct.bsky.social, “Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese”, with @brucelyu17.bsky.social, Jiebo Luo and Jian Kang, revealing 🤖 LLM performance disparities. 📄 Link: arxiv.org/abs/2505.22645
Reposted by Divya Shanmugam

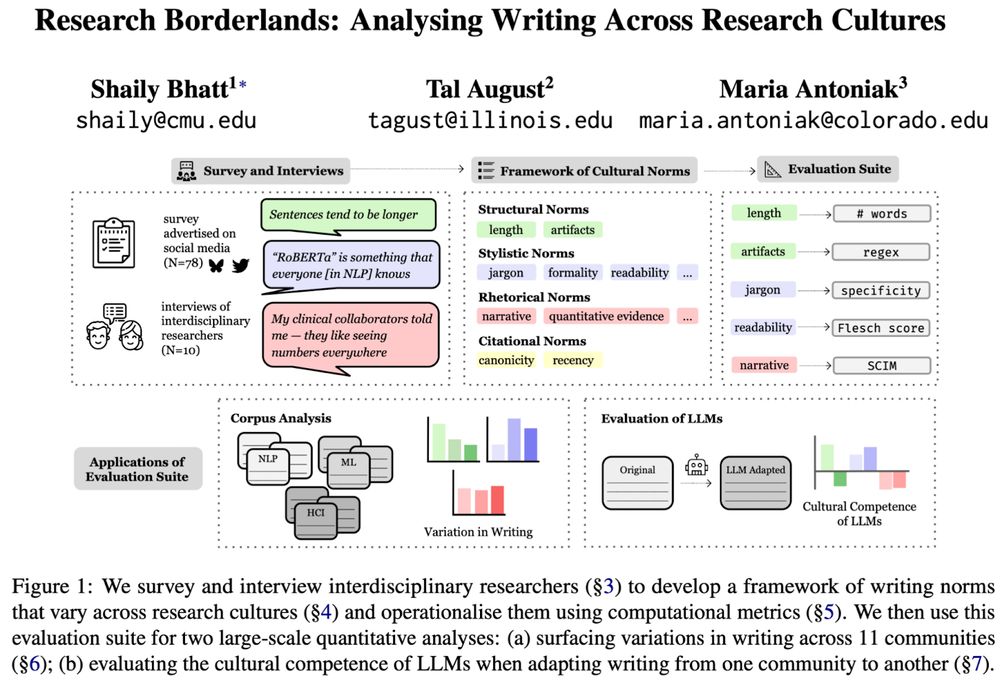
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
June 9, 2025 at 11:30 PM
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
and... here is the actual GIF 🙈
June 14, 2025 at 5:04 PM
and... here is the actual GIF 🙈
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.

June 14, 2025 at 3:00 PM
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
I’m in Nashville this week for #CVPR2025! DM me to chat about conformal prediction, test-time adaptation, or model reliability. Excited to see new work and to catch up with friends old and new!!
June 12, 2025 at 7:58 PM
I’m in Nashville this week for #CVPR2025! DM me to chat about conformal prediction, test-time adaptation, or model reliability. Excited to see new work and to catch up with friends old and new!!
Reposted by Divya Shanmugam

Please help us spread the word! 📣
FATE is hiring a pre-doc research assistant! We're looking for candidates who will have completed their bachelor's degree (or equivalent) by summer 2025 and want to advance their research skills before applying to PhD programs.
FATE is hiring a pre-doc research assistant! We're looking for candidates who will have completed their bachelor's degree (or equivalent) by summer 2025 and want to advance their research skills before applying to PhD programs.

Exciting news: The Fairness, Accountability, Transparency and Ethics (FATE) group at Microsoft Research NYC is hiring a predoctoral fellow!!! 🎉
www.microsoft.com/en-us/resear...
www.microsoft.com/en-us/resear...
FATE Research Assistant (“Pre-doc”) - Microsoft Research
The Fairness, Accountability, Transparency, and Ethics (FATE) Research group at Microsoft Research New York City (MSR NYC) is looking for a pre-doctoral research assistant (pre-doc) to start August 20...
www.microsoft.com
May 20, 2025 at 2:34 PM
Please help us spread the word! 📣
FATE is hiring a pre-doc research assistant! We're looking for candidates who will have completed their bachelor's degree (or equivalent) by summer 2025 and want to advance their research skills before applying to PhD programs.
FATE is hiring a pre-doc research assistant! We're looking for candidates who will have completed their bachelor's degree (or equivalent) by summer 2025 and want to advance their research skills before applying to PhD programs.
Reposted by Divya Shanmugam

I really enjoyed (and learned a LOT from) working on this project with these wonderful co-authors:
@dmshanmugam.bsky.social
Ashley Beecy
Gabriel Sayer
@destrin.bsky.social
@nkgarg.bsky.social
@emmapierson.bsky.social
7/7
@dmshanmugam.bsky.social
Ashley Beecy
Gabriel Sayer
@destrin.bsky.social
@nkgarg.bsky.social
@emmapierson.bsky.social
7/7
May 1, 2025 at 12:57 PM
I really enjoyed (and learned a LOT from) working on this project with these wonderful co-authors:
@dmshanmugam.bsky.social
Ashley Beecy
Gabriel Sayer
@destrin.bsky.social
@nkgarg.bsky.social
@emmapierson.bsky.social
7/7
@dmshanmugam.bsky.social
Ashley Beecy
Gabriel Sayer
@destrin.bsky.social
@nkgarg.bsky.social
@emmapierson.bsky.social
7/7
Erica’s new paper on a method to both measure *and* correct for three types of disparities associated with disease progression is now out! Check out the thread for more detail + findings from a case study on heart failure. Congratulations!!!
I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
May 1, 2025 at 1:28 PM
Erica’s new paper on a method to both measure *and* correct for three types of disparities associated with disease progression is now out! Check out the thread for more detail + findings from a case study on heart failure. Congratulations!!!
my friend jonah made a fun game that i now play everyday: guessten.com! please enjoy and send me your scores
GuessTen
guessten.com
April 25, 2025 at 8:59 PM
my friend jonah made a fun game that i now play everyday: guessten.com! please enjoy and send me your scores
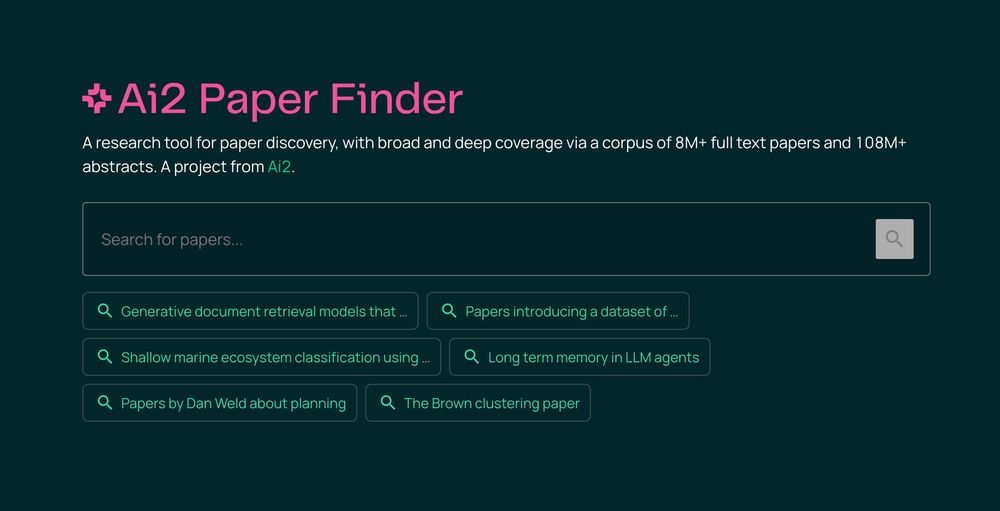
just used this to source citations with great success - a very nice tool!!

Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
April 9, 2025 at 12:43 AM
just used this to source citations with great success - a very nice tool!!
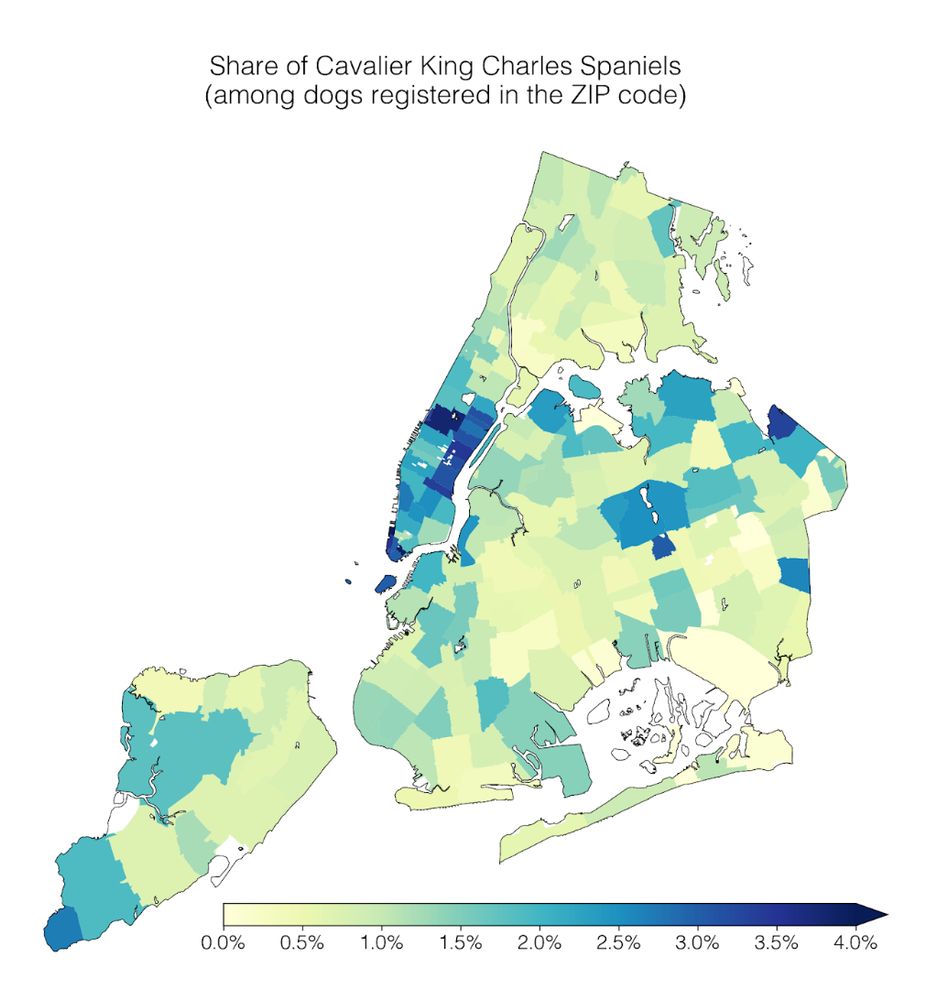
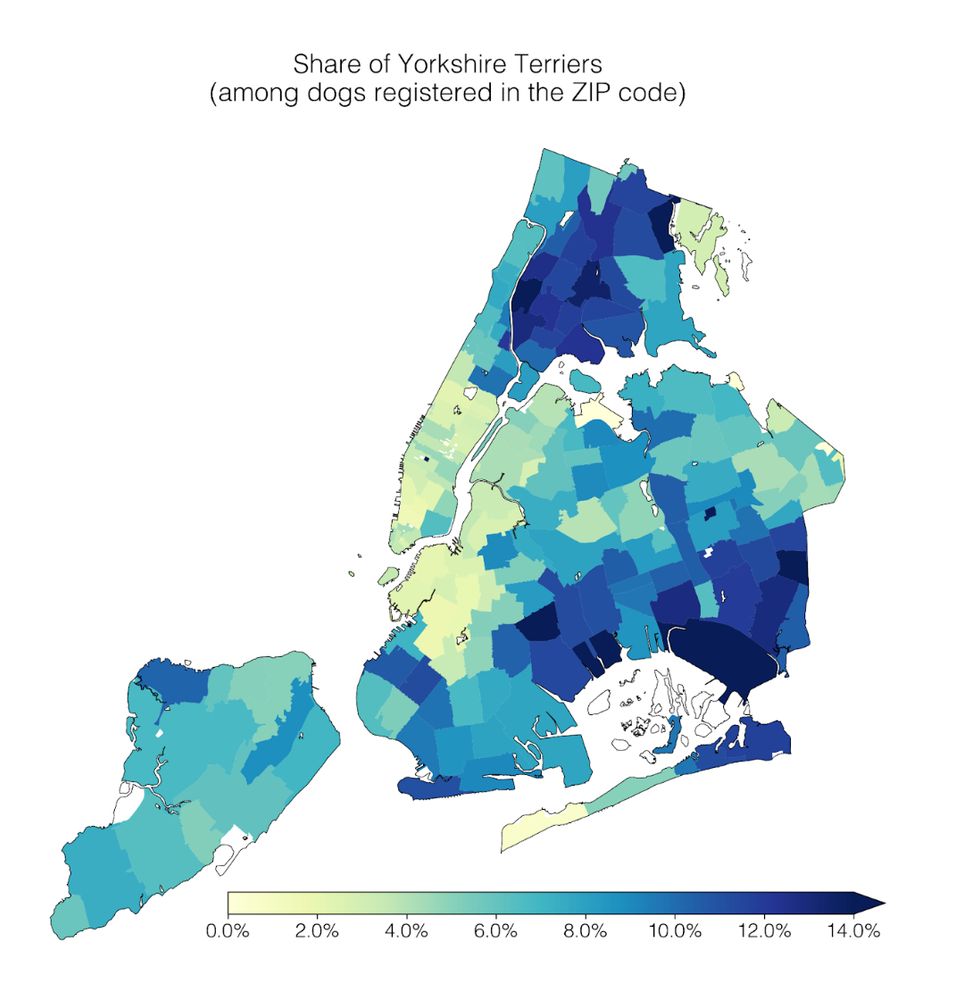
kenny had the great idea to spend a whole day analyzing dogs — so so fun! i like health data but turns out i love dog data

Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
April 2, 2025 at 2:21 PM
kenny had the great idea to spend a whole day analyzing dogs — so so fun! i like health data but turns out i love dog data
Reposted by Divya Shanmugam
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
March 28, 2025 at 3:25 PM
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5