



Kenny Peng
@kennypeng.bsky.social
CS PhD student at Cornell Tech. Interested in interactions between algorithms and society. Princeton math '22.
kennypeng.me
kennypeng.me
Reposted by Kenny Peng

Our paper “Inferring fine-grained migration patterns across the United States” is now out in @natcomms.nature.com! We released a new, highly granular migration dataset. 1/9
February 5, 2026 at 5:30 PM
Our paper “Inferring fine-grained migration patterns across the United States” is now out in @natcomms.nature.com! We released a new, highly granular migration dataset. 1/9
Reposted by Kenny Peng

🎙️ I had a great time joining the Data Skeptic podcast to talk about my work on recommender systems
If you're interested in embeddings, aligning group preferences, or music recommendations, check out the episode below 👇
open.spotify.com/episode/6IsP...
If you're interested in embeddings, aligning group preferences, or music recommendations, check out the episode below 👇
open.spotify.com/episode/6IsP...

Fairness in PCA-Based Recommenders
open.spotify.com
January 28, 2026 at 4:23 PM
🎙️ I had a great time joining the Data Skeptic podcast to talk about my work on recommender systems
If you're interested in embeddings, aligning group preferences, or music recommendations, check out the episode below 👇
open.spotify.com/episode/6IsP...
If you're interested in embeddings, aligning group preferences, or music recommendations, check out the episode below 👇
open.spotify.com/episode/6IsP...
Reposted by Kenny Peng

Check out our new paper at #AAAI 2026! I’ll be presenting in Singapore at Saturday’s poster session (12–2pm). This is joint work with @shuvoms.bsky.social, @bergerlab.bsky.social, @emmapierson.bsky.social, and @nkgarg.bsky.social. 1/9

January 20, 2026 at 4:08 PM
Check out our new paper at #AAAI 2026! I’ll be presenting in Singapore at Saturday’s poster session (12–2pm). This is joint work with @shuvoms.bsky.social, @bergerlab.bsky.social, @emmapierson.bsky.social, and @nkgarg.bsky.social. 1/9
Reposted by Kenny Peng

Excited to present a new preprint with @nkgarg.bsky.social: presenting usage statistics and observational findings from Paper Skygest in the first six months of deployment! 🎉📜
arxiv.org/abs/2601.04253
arxiv.org/abs/2601.04253

January 14, 2026 at 7:48 PM
Excited to present a new preprint with @nkgarg.bsky.social: presenting usage statistics and observational findings from Paper Skygest in the first six months of deployment! 🎉📜
arxiv.org/abs/2601.04253
arxiv.org/abs/2601.04253
Reposted by Kenny Peng
so so so excited to present our research + connect with the #ATScience community 🧪🎉

Excited to announce that @sjgreenwood.bsky.social will be at #ATScience presenting their work on the beloved @paper-feed.bsky.social , experiments on self-hosted feeds (in collaboration with @graze.social @aendra.com) and observational analyses of social media on #atproto!
Looking forward to it! 🎉
Looking forward to it! 🎉
Exciting to see our first speaker proposals coming in for #ATScience 2026! ✨
We’d love to hear yours too, so please submit your idea at
forms.atproto.science/atscience26-... 🗳️
The call for proposals closes at the end of January - we’ll review and notify speakers on a rolling basis.
We’d love to hear yours too, so please submit your idea at
forms.atproto.science/atscience26-... 🗳️
The call for proposals closes at the end of January - we’ll review and notify speakers on a rolling basis.
January 9, 2026 at 9:37 PM
so so so excited to present our research + connect with the #ATScience community 🧪🎉
Year 3 of spending many days making gingerbread — this year, featuring the gantries of Long Island City



December 24, 2025 at 8:38 PM
Year 3 of spending many days making gingerbread — this year, featuring the gantries of Long Island City
Reposted by Kenny Peng

Excited to share a new working paper!
What happened when Change.org integrated an AI writing tool into their platform? We provide causal evidence that petition text changed significantly while outcomes did not improve. 1/
arxiv.org/abs/2511.13949
What happened when Change.org integrated an AI writing tool into their platform? We provide causal evidence that petition text changed significantly while outcomes did not improve. 1/
arxiv.org/abs/2511.13949

Introducing AI to an Online Petition Platform Changed Outputs but not Outcomes
The rapid integration of AI writing tools into online platforms raises critical questions about their impact on content production and outcomes. We leverage a unique natural experiment on Change$.$org...
arxiv.org
December 1, 2025 at 8:32 PM
Excited to share a new working paper!
What happened when Change.org integrated an AI writing tool into their platform? We provide causal evidence that petition text changed significantly while outcomes did not improve. 1/
arxiv.org/abs/2511.13949
What happened when Change.org integrated an AI writing tool into their platform? We provide causal evidence that petition text changed significantly while outcomes did not improve. 1/
arxiv.org/abs/2511.13949
I had a lot of fun making this map of Manhattan’s grid (only the numbered streets and avenues). Learned that 4th avenue doesn’t exist, but then learned that it actually does exist but only for a few blocks.

For #30DayMapChallenge day 11, a minimal map from @kennypeng.bsky.social.
Kenny extracts minimal elements from a not-as-minimal-as-it-seems object: the Manhattan street grid. "I show how Manhattan’s numbered grid of streets and avenues is more complicated than you might realize," he says.
Kenny extracts minimal elements from a not-as-minimal-as-it-seems object: the Manhattan street grid. "I show how Manhattan’s numbered grid of streets and avenues is more complicated than you might realize," he says.
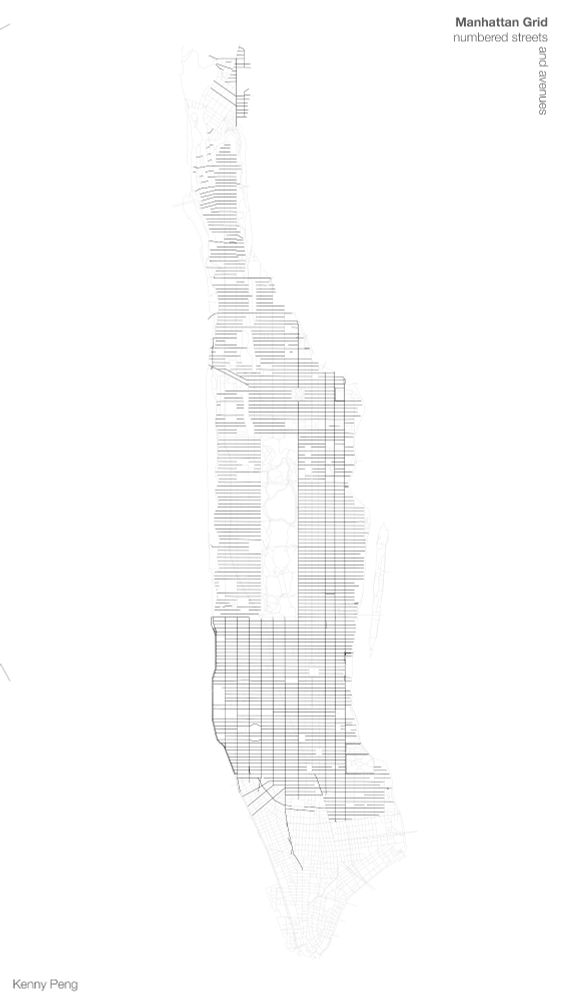
November 17, 2025 at 2:54 PM
I had a lot of fun making this map of Manhattan’s grid (only the numbered streets and avenues). Learned that 4th avenue doesn’t exist, but then learned that it actually does exist but only for a few blocks.
Reposted by Kenny Peng

New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.

October 17, 2025 at 4:29 PM
New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.
Being Divya's labmate (and fellow ferry commuter) has been a real pleasure, and I've learned a ton from both her research itself and her approach to research (and also from the other random things she knows about).
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
October 14, 2025 at 4:02 PM
Being Divya's labmate (and fellow ferry commuter) has been a real pleasure, and I've learned a ton from both her research itself and her approach to research (and also from the other random things she knows about).
"those already relatively advantaged are, empirically, more able to pay time costs and navigate administrative burdens imposed by the mechanisms."
This point by @nkgarg.bsky.social has greatly shaped my thinking about the role of computer science in public service settings.
This point by @nkgarg.bsky.social has greatly shaped my thinking about the role of computer science in public service settings.

New piece, out in the Sigecom Exchanges! It's my first solo-author piece, and the closest thing I've written to being my "manifesto." #econsky #ecsky
arxiv.org/abs/2507.03600
arxiv.org/abs/2507.03600

August 12, 2025 at 1:04 PM
"those already relatively advantaged are, empirically, more able to pay time costs and navigate administrative burdens imposed by the mechanisms."
This point by @nkgarg.bsky.social has greatly shaped my thinking about the role of computer science in public service settings.
This point by @nkgarg.bsky.social has greatly shaped my thinking about the role of computer science in public service settings.
How do we reconcile excitement about sparse autoencoders with negative results showing that they underperform simple baselines? Our new position paper makes a distinction: SAEs are very useful for tools for discovering *unknown* concepts, less good for acting on *known* concepts.

August 5, 2025 at 5:26 PM
How do we reconcile excitement about sparse autoencoders with negative results showing that they underperform simple baselines? Our new position paper makes a distinction: SAEs are very useful for tools for discovering *unknown* concepts, less good for acting on *known* concepts.
One paragraph pitch for why sparse autoencoders are cool (they learn *interpretable* text embeddings)

July 30, 2025 at 5:22 PM
One paragraph pitch for why sparse autoencoders are cool (they learn *interpretable* text embeddings)
We're presenting two papers Wednesday at #ICML2025, both at 11am.
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️


July 16, 2025 at 5:09 AM
We're presenting two papers Wednesday at #ICML2025, both at 11am.
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962

July 3, 2025 at 12:54 PM
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962
Reposted by Kenny Peng
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.

June 14, 2025 at 3:00 PM
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
Reposted by Kenny Peng

We'll present HypotheSAEs at ICML this summer! 🎉
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
May 5, 2025 at 9:27 PM
We'll present HypotheSAEs at ICML this summer! 🎉
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Reposted by Kenny Peng

I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
May 1, 2025 at 12:57 PM
I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
Reposted by Kenny Peng

The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...

My ‘woke DEI’ grant has been flagged for scrutiny. Where do I go from here?
My work in making artificial intelligence fair has been noticed by US officials intent on ending ‘class warfare propaganda’.
www.nature.com
April 25, 2025 at 5:19 PM
The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
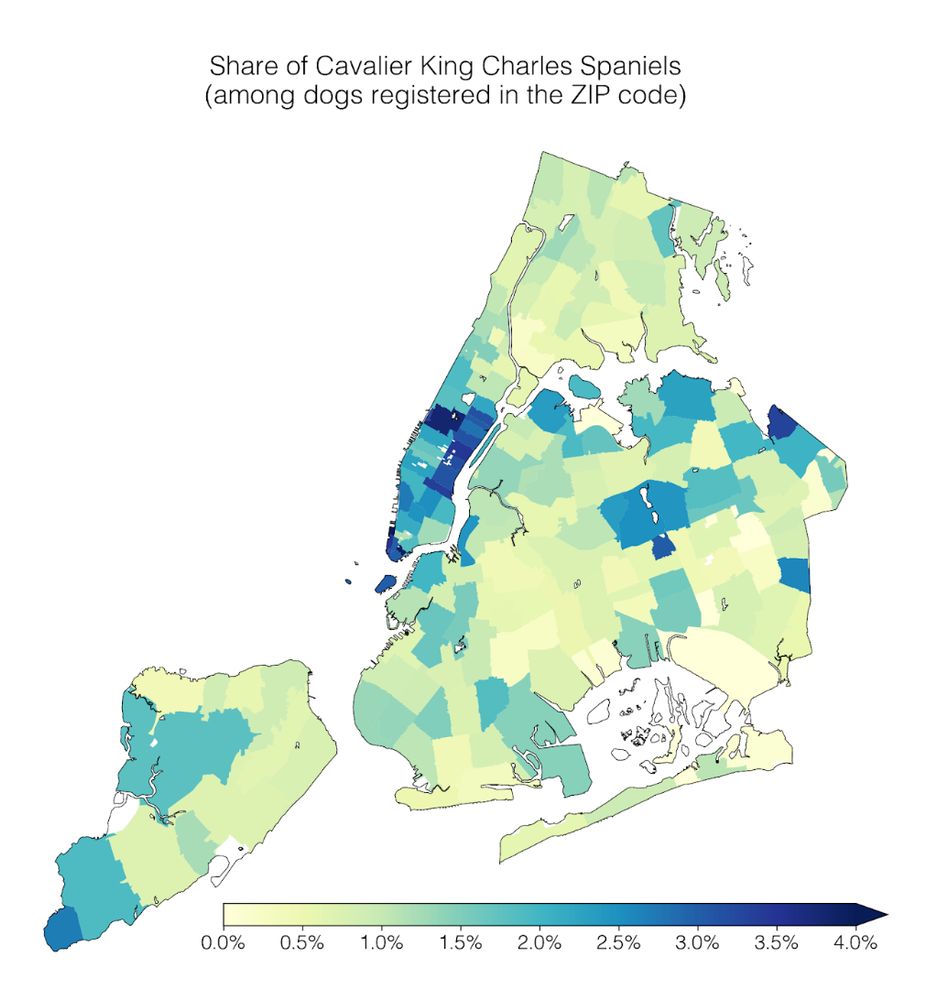
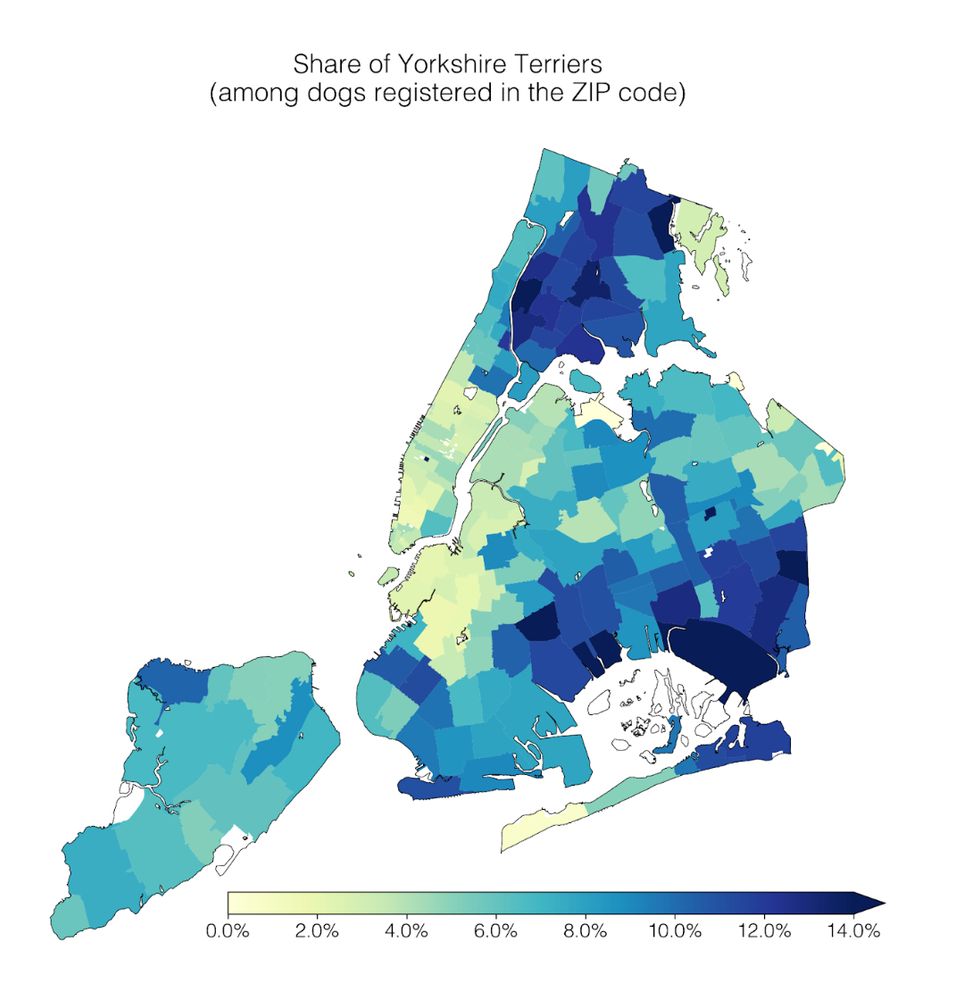
April 2, 2025 at 2:16 PM
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
Reposted by Kenny Peng
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
March 28, 2025 at 3:25 PM
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
Reposted by Kenny Peng
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
March 18, 2025 at 3:17 PM
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
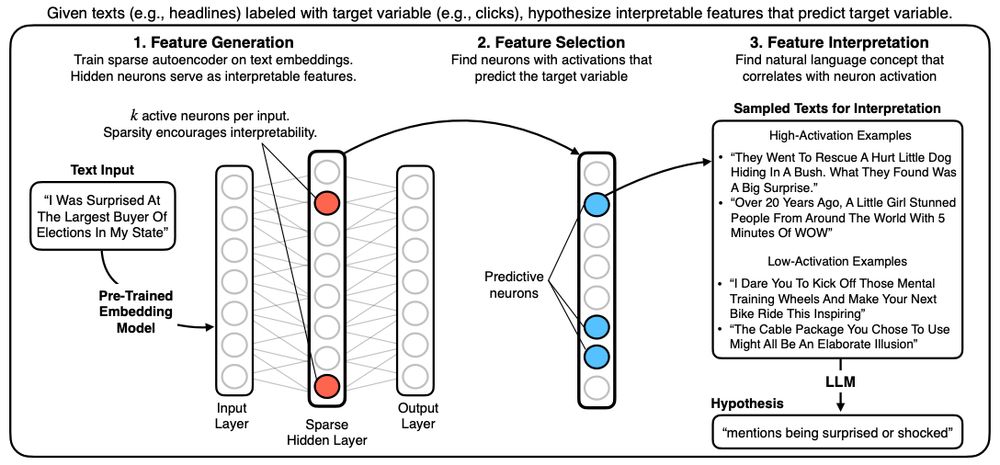

March 18, 2025 at 3:29 PM
(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
Reposted by Kenny Peng
Please repost to get the word out! @nkgarg.bsky.social and I are excited to present a personalized feed for academics! It shows posts about papers from accounts you’re following bsky.app/profile/pape...
March 10, 2025 at 3:12 PM
Please repost to get the word out! @nkgarg.bsky.social and I are excited to present a personalized feed for academics! It shows posts about papers from accounts you’re following bsky.app/profile/pape...
In new work, we show a "No Free Lunch Theorem" for human-AI Collaboration (w/ @nkgarg.bsky.social and Jon Kleinberg).
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230

February 27, 2025 at 2:30 PM
In new work, we show a "No Free Lunch Theorem" for human-AI Collaboration (w/ @nkgarg.bsky.social and Jon Kleinberg).
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230