



Kenny Peng
@kennypeng.bsky.social
CS PhD student at Cornell Tech. Interested in interactions between algorithms and society. Princeton math '22.
kennypeng.me
kennypeng.me
How do we reconcile excitement about sparse autoencoders with negative results showing that they underperform simple baselines? Our new position paper makes a distinction: SAEs are very useful for tools for discovering *unknown* concepts, less good for acting on *known* concepts.

August 5, 2025 at 5:26 PM
How do we reconcile excitement about sparse autoencoders with negative results showing that they underperform simple baselines? Our new position paper makes a distinction: SAEs are very useful for tools for discovering *unknown* concepts, less good for acting on *known* concepts.
One paragraph pitch for why sparse autoencoders are cool (they learn *interpretable* text embeddings)

July 30, 2025 at 5:22 PM
One paragraph pitch for why sparse autoencoders are cool (they learn *interpretable* text embeddings)
In Correlated Errors in Large Language Models, we show that LLMs are correlated in how they make mistakes. On one dataset, LLMs make the same mistake 2x more than random chance.

July 16, 2025 at 5:09 AM
In Correlated Errors in Large Language Models, we show that LLMs are correlated in how they make mistakes. On one dataset, LLMs make the same mistake 2x more than random chance.
In Sparse Autoencoders for Hypothesis Generation, we show that SAEs can be used to find predictive natural language concepts in text data (e.g., that "addresses collective human responsibility" predicts lower headline engagement), achieving SOTA performance and efficiency.

July 16, 2025 at 5:09 AM
In Sparse Autoencoders for Hypothesis Generation, we show that SAEs can be used to find predictive natural language concepts in text data (e.g., that "addresses collective human responsibility" predicts lower headline engagement), achieving SOTA performance and efficiency.
We're presenting two papers Wednesday at #ICML2025, both at 11am.
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️


July 16, 2025 at 5:09 AM
We're presenting two papers Wednesday at #ICML2025, both at 11am.
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)!
Short thread ⬇️
The empirics here also add nuance to theory. While less correlated models can be more accurate together through a “wisdom of crowds,” this effect doesn't hold when newer, more correlated models are adopted in our simulations: gains from individual accuracy outweigh losses from homogeneity. (6/7)

July 3, 2025 at 12:54 PM
The empirics here also add nuance to theory. While less correlated models can be more accurate together through a “wisdom of crowds,” this effect doesn't hold when newer, more correlated models are adopted in our simulations: gains from individual accuracy outweigh losses from homogeneity. (6/7)
However, in equilibrium, increased correlation—as predicted by past theoretical work—actually improves average applicant outcomes (intuitively, of the applicants who receive a job offer, more correlation means they will get more offers).
For the theory, see arxiv.org/abs/2312.09841 (5/7)
For the theory, see arxiv.org/abs/2312.09841 (5/7)

July 3, 2025 at 12:54 PM
However, in equilibrium, increased correlation—as predicted by past theoretical work—actually improves average applicant outcomes (intuitively, of the applicants who receive a job offer, more correlation means they will get more offers).
For the theory, see arxiv.org/abs/2312.09841 (5/7)
For the theory, see arxiv.org/abs/2312.09841 (5/7)
Since LLMs are correlated, this also leads to greater systemic exclusion in a labor market setting: more applicants are screened out of all jobs. Systemic exclusion persists even when different LLMs are used across firms. (4/7)

July 3, 2025 at 12:54 PM
Since LLMs are correlated, this also leads to greater systemic exclusion in a labor market setting: more applicants are screened out of all jobs. Systemic exclusion persists even when different LLMs are used across firms. (4/7)
A consequence of error correlation is that LLM judges inflate accuracy of models less accurate than it. Here, we plot accuracy inflation against true model accuracy. Models from the same company (in red) are especially inflated. (3/7)

July 3, 2025 at 12:54 PM
A consequence of error correlation is that LLM judges inflate accuracy of models less accurate than it. Here, we plot accuracy inflation against true model accuracy. Models from the same company (in red) are especially inflated. (3/7)
What explains error correlation? We found that models from the same company are more correlated. Strikingly, more accurate models also have more correlated errors, suggesting some level of convergence among newer models. (2/7)

July 3, 2025 at 12:54 PM
What explains error correlation? We found that models from the same company are more correlated. Strikingly, more accurate models also have more correlated errors, suggesting some level of convergence among newer models. (2/7)
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962
July 3, 2025 at 12:54 PM
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962
We also made a web app (github.com/shuvom-s/nyc...) you can run locally to make maps by name/breed.
We also briefly explored a “dog park simulator.”
We also briefly explored a “dog park simulator.”


April 2, 2025 at 2:16 PM
We also made a web app (github.com/shuvom-s/nyc...) you can run locally to make maps by name/breed.
We also briefly explored a “dog park simulator.”
We also briefly explored a “dog park simulator.”
7) Dogs are licensed the most in July and the least in November.

April 2, 2025 at 2:16 PM
7) Dogs are licensed the most in July and the least in November.
5) Goldendoodles, Poodle Crossbreeds, and French Bulldogs are becoming more popular. Chihuahua's are becoming less popular.
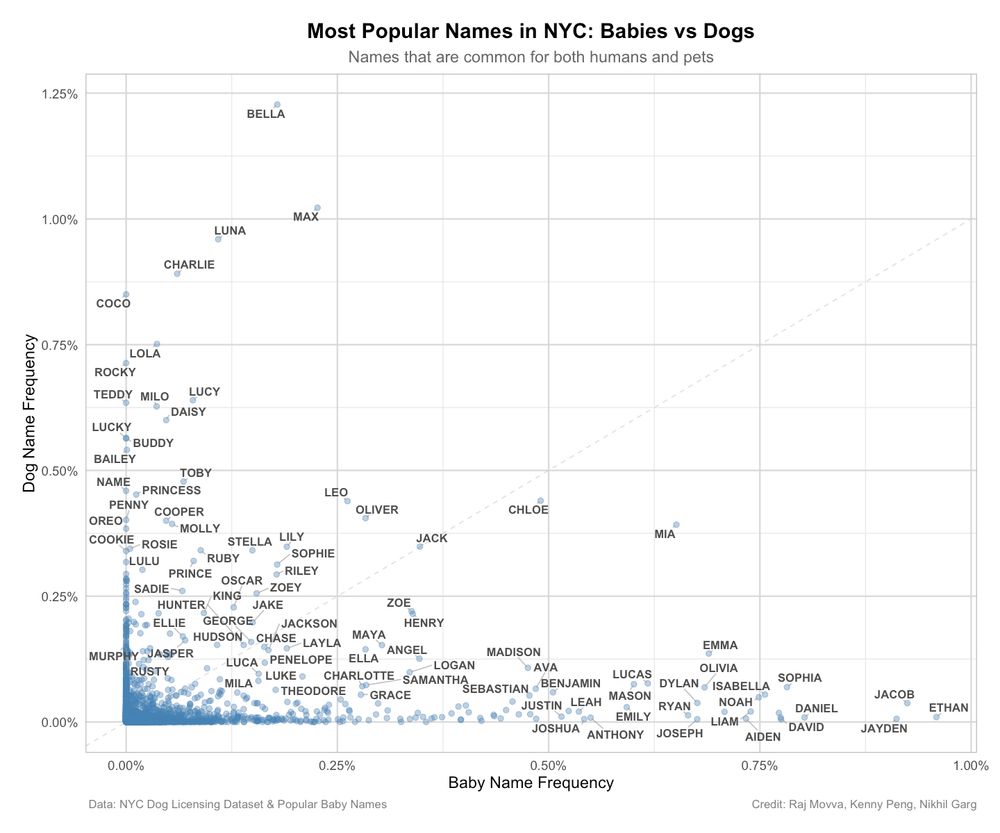
Luna is the only popular name that is becoming more common among dogs AND babies.
Luna is the only popular name that is becoming more common among dogs AND babies.




April 2, 2025 at 2:16 PM
5) Goldendoodles, Poodle Crossbreeds, and French Bulldogs are becoming more popular. Chihuahua's are becoming less popular.
Luna is the only popular name that is becoming more common among dogs AND babies.
Luna is the only popular name that is becoming more common among dogs AND babies.
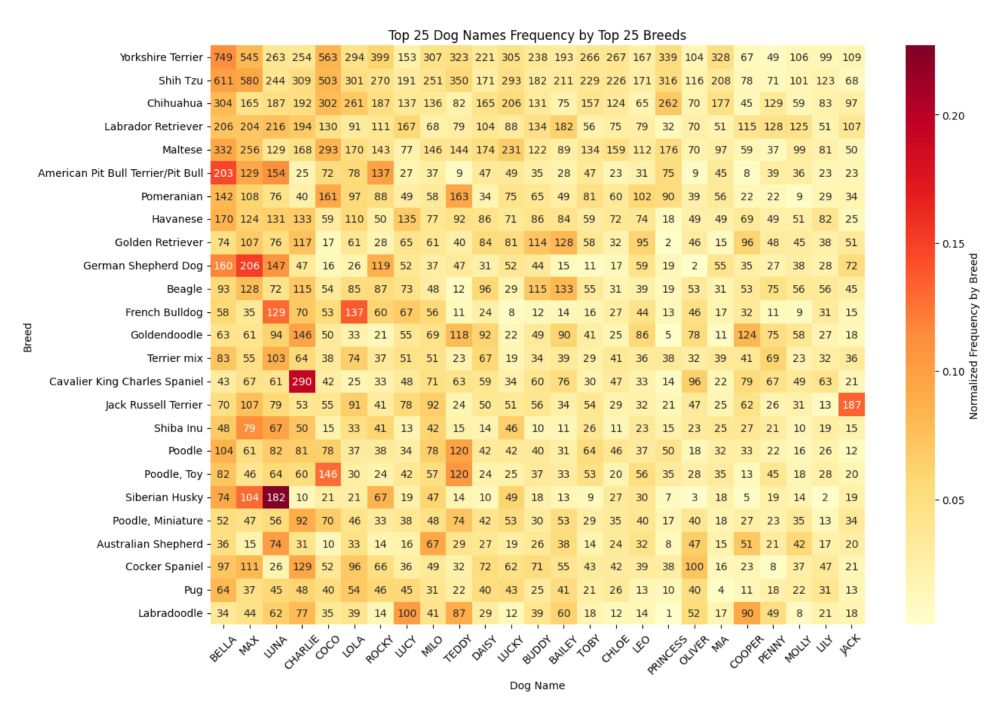
4) The “most common dog” in NYC is a Yorkshire Terrier named Bella. Jack Russel Terriers are often “Jack” and Charles Spaniels “Charlie.” Huskies are always named Luna—the reason for which is unclear (?).
April 2, 2025 at 2:16 PM
4) The “most common dog” in NYC is a Yorkshire Terrier named Bella. Jack Russel Terriers are often “Jack” and Charles Spaniels “Charlie.” Huskies are always named Luna—the reason for which is unclear (?).
2) The dog name/baby name scatter plot: Max and Charlie are more dog name than human name. Dogs aren't called Ethan though.
April 2, 2025 at 2:16 PM
2) The dog name/baby name scatter plot: Max and Charlie are more dog name than human name. Dogs aren't called Ethan though.
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
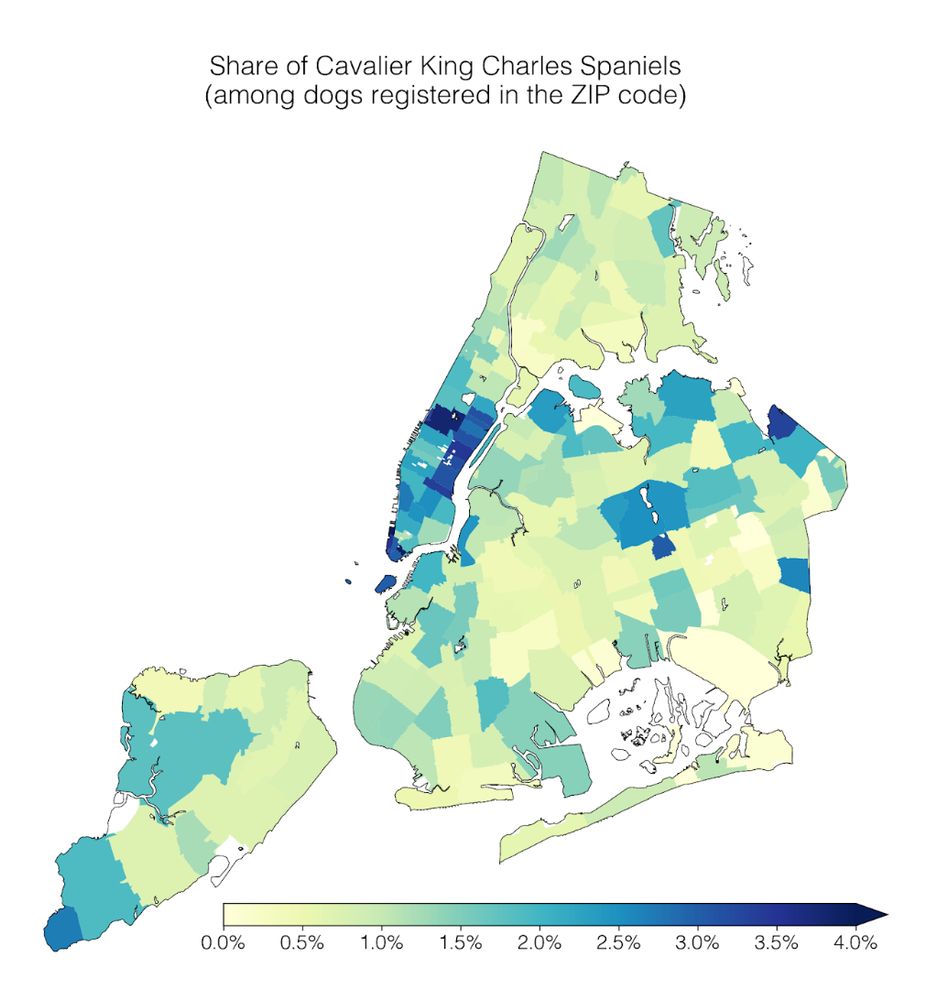
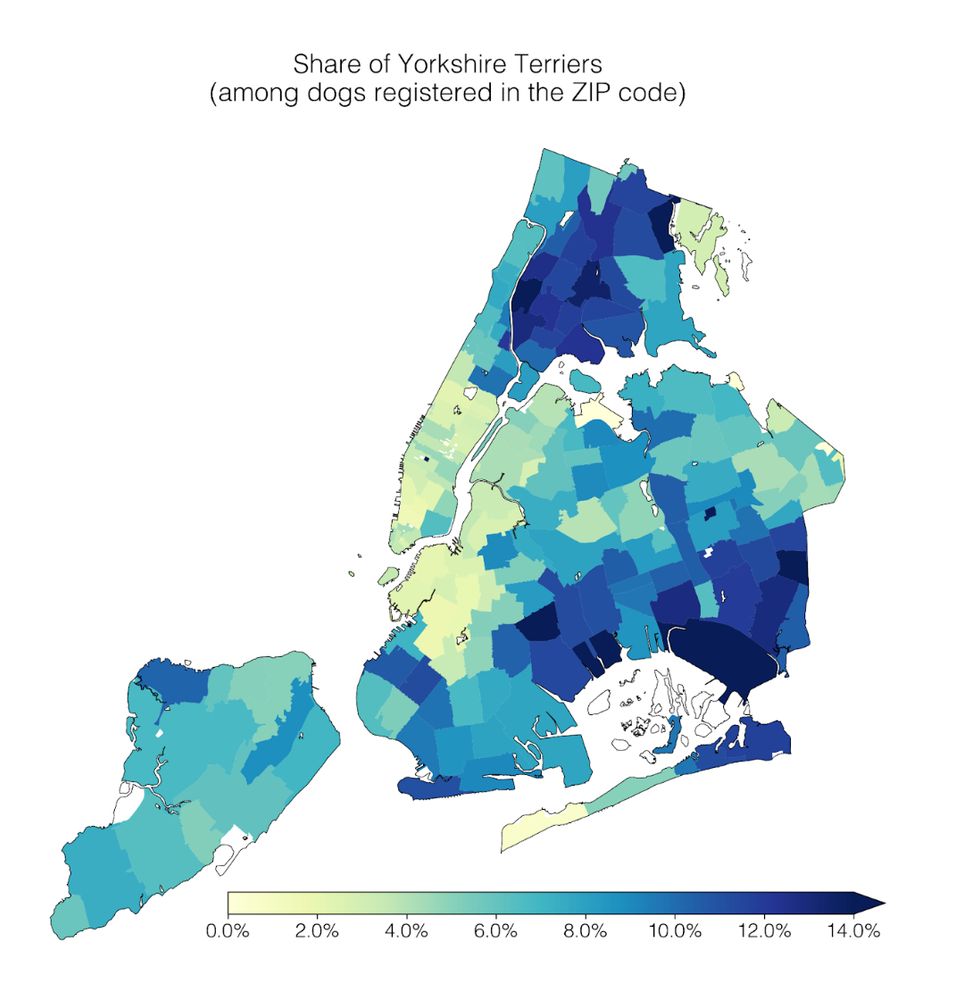
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
April 2, 2025 at 2:16 PM
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
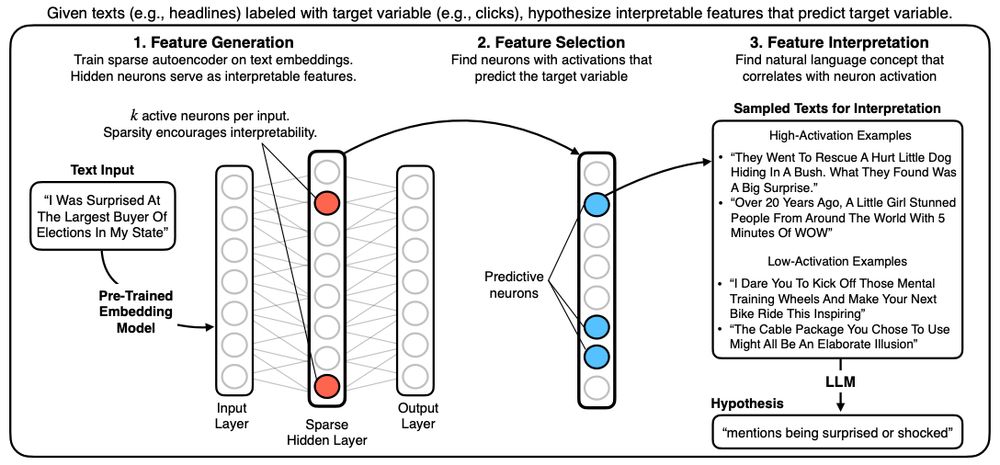
(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382

March 18, 2025 at 3:29 PM
(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
In new work, we show a "No Free Lunch Theorem" for human-AI Collaboration (w/ @nkgarg.bsky.social and Jon Kleinberg).
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230

February 27, 2025 at 2:30 PM
In new work, we show a "No Free Lunch Theorem" for human-AI Collaboration (w/ @nkgarg.bsky.social and Jon Kleinberg).
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230
(And if you're at #AAAI, I'm presenting at 11:15am today in the Humans and AI session. Poster 12:30-2:30.)
arxiv.org/abs/2411.15230
I'm at #NeurIPS, presenting work w/ @nkgarg.bsky.social where we study algorithmic monoculture using a matching markets model: If many firms or colleges all use the same algorithm to evaluate applicants, what happens?
Poster is in a few hours, come chat!
Wed 11am-2pm | West Ballroom A-D #5505
Poster is in a few hours, come chat!
Wed 11am-2pm | West Ballroom A-D #5505

December 11, 2024 at 4:16 PM
I'm at #NeurIPS, presenting work w/ @nkgarg.bsky.social where we study algorithmic monoculture using a matching markets model: If many firms or colleges all use the same algorithm to evaluate applicants, what happens?
Poster is in a few hours, come chat!
Wed 11am-2pm | West Ballroom A-D #5505
Poster is in a few hours, come chat!
Wed 11am-2pm | West Ballroom A-D #5505