




Erica Chiang
@ericachiang.bsky.social
Pinned
Erica Chiang
@ericachiang.bsky.social
· May 1
I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
Reposted by Erica Chiang

New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.

October 17, 2025 at 4:29 PM
New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.
selfishly i wish we could keep divya in our lab forever but i guess it would be a disservice to the rest of the world 😅 she’s been such a wonderful mentor to me—i’ve learned a lot from how thoughtful, creative, and knowledgeable she is about everything. she’s also super funny and amazing at baking 🤭
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
October 14, 2025 at 5:14 PM
selfishly i wish we could keep divya in our lab forever but i guess it would be a disservice to the rest of the world 😅 she’s been such a wonderful mentor to me—i’ve learned a lot from how thoughtful, creative, and knowledgeable she is about everything. she’s also super funny and amazing at baking 🤭
I can’t believe I’m saying this: our work received a Best Paper Award at #CHIL2025!! So so excited and grateful 🥰 Looking forward to day 2 of the conference with these awesome people :)



June 27, 2025 at 5:04 PM
I can’t believe I’m saying this: our work received a Best Paper Award at #CHIL2025!! So so excited and grateful 🥰 Looking forward to day 2 of the conference with these awesome people :)
Reposted by Erica Chiang

I wrote about science cuts and my family's immigration story as part of The McClintock Letters organized by @cornellasap.bsky.social. Haven't yet placed it in a Houston-based newspaper but hopefully it's useful here
gargnikhil.com/posts/202506...
gargnikhil.com/posts/202506...
Science and immigration cuts · Nikhil Garg
gargnikhil.com
June 16, 2025 at 11:09 AM
I wrote about science cuts and my family's immigration story as part of The McClintock Letters organized by @cornellasap.bsky.social. Haven't yet placed it in a Houston-based newspaper but hopefully it's useful here
gargnikhil.com/posts/202506...
gargnikhil.com/posts/202506...
Reposted by Erica Chiang
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.

June 14, 2025 at 3:00 PM
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
May 1, 2025 at 12:57 PM
I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
Reposted by Erica Chiang

The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...

My ‘woke DEI’ grant has been flagged for scrutiny. Where do I go from here?
My work in making artificial intelligence fair has been noticed by US officials intent on ending ‘class warfare propaganda’.
www.nature.com
April 25, 2025 at 5:19 PM
The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
check out the findings from our #dogathon 😍🐶 !!
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
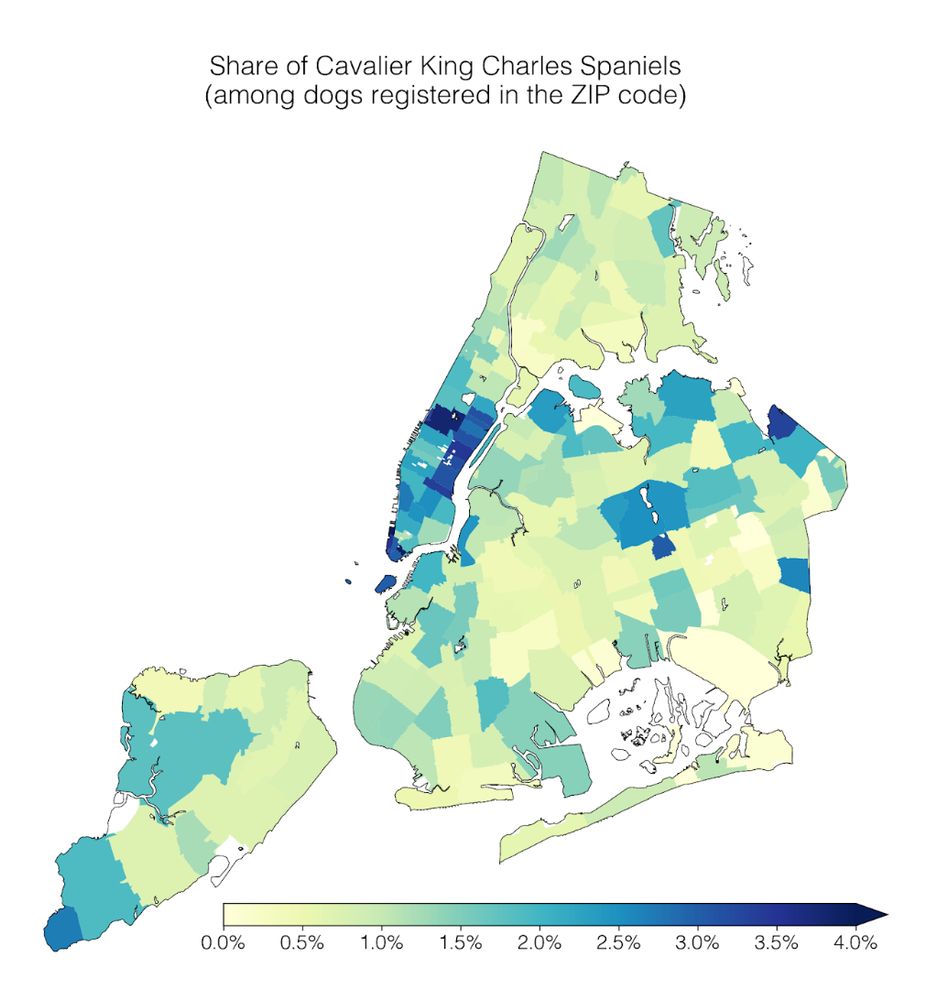
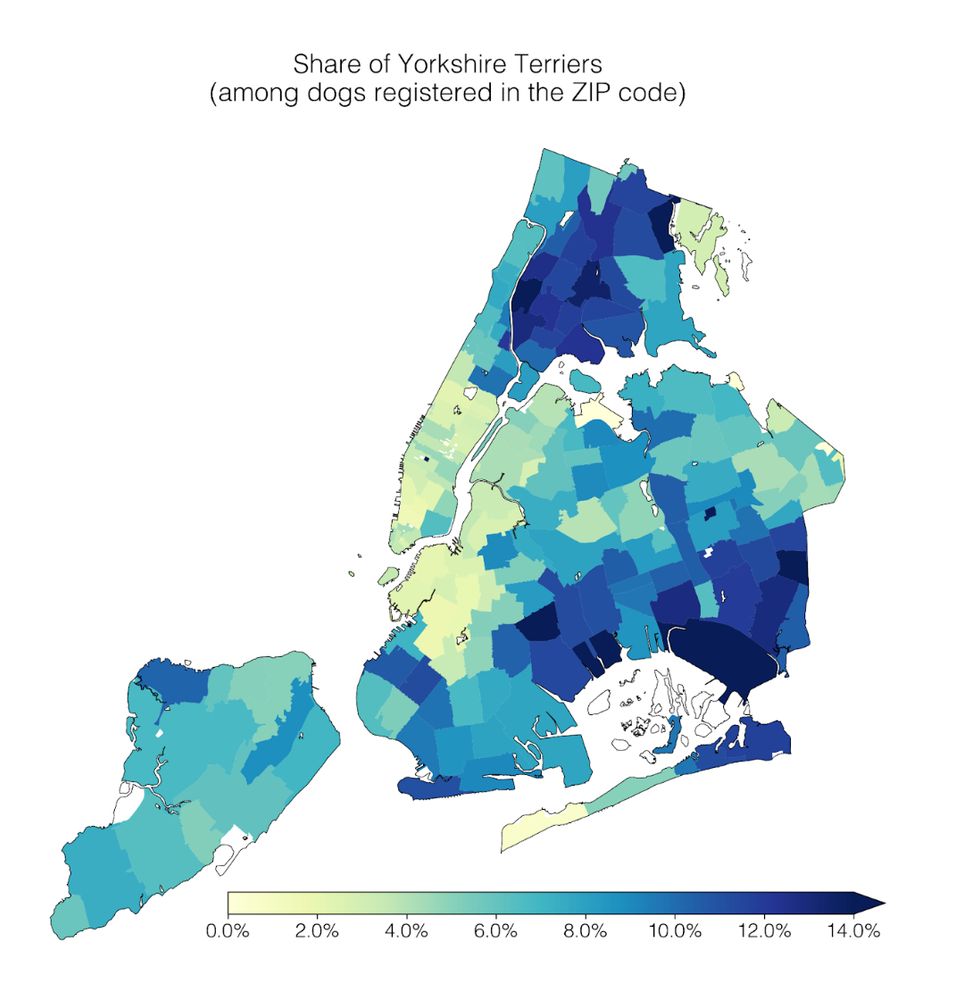
April 2, 2025 at 2:23 PM
check out the findings from our #dogathon 😍🐶 !!
Reposted by Erica Chiang

Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
March 28, 2025 at 3:25 PM
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
Reposted by Erica Chiang

Excited to announce a new preprint from my lab (with @rishi-jha.bsky.social and Vitaly Shmatikov; my first as a first author!) about severe security vulnerabilities in LLM-based multi-agent systems:
“Multi-Agent Systems Execute Arbitrary Malicious Code”
arxiv.org/abs/2503.12188
1/12
“Multi-Agent Systems Execute Arbitrary Malicious Code”
arxiv.org/abs/2503.12188
1/12

March 18, 2025 at 3:23 PM
Excited to announce a new preprint from my lab (with @rishi-jha.bsky.social and Vitaly Shmatikov; my first as a first author!) about severe security vulnerabilities in LLM-based multi-agent systems:
“Multi-Agent Systems Execute Arbitrary Malicious Code”
arxiv.org/abs/2503.12188
1/12
“Multi-Agent Systems Execute Arbitrary Malicious Code”
arxiv.org/abs/2503.12188
1/12
Reposted by Erica Chiang

(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
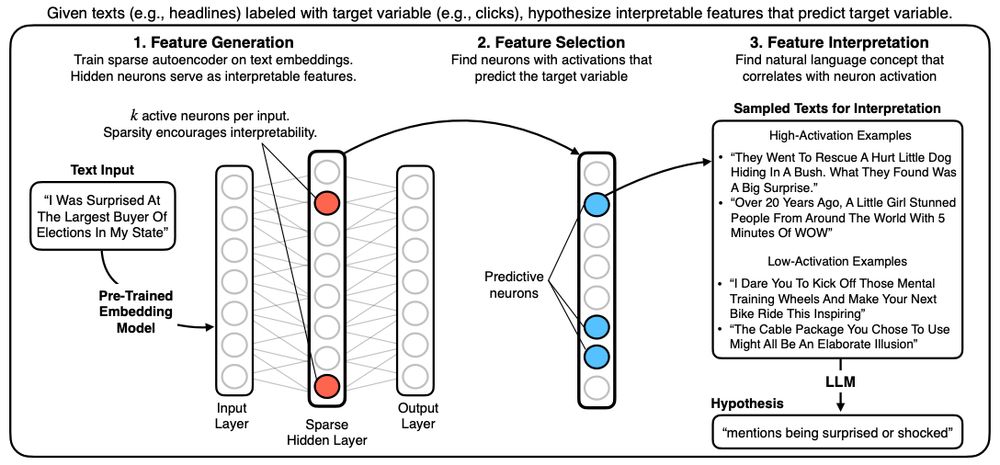

March 18, 2025 at 3:29 PM
(1/n) New paper/code! Sparse Autoencoders for Hypothesis Generation
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
HypotheSAEs generates interpretable features of text data that predict a target variable: What features predict clicks from headlines / party from congressional speech / rating from Yelp review?
arxiv.org/abs/2502.04382
Reposted by Erica Chiang

💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
March 18, 2025 at 3:17 PM
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Reposted by Erica Chiang

Please repost to get the word out! @nkgarg.bsky.social and I are excited to present a personalized feed for academics! It shows posts about papers from accounts you’re following bsky.app/profile/pape...
March 10, 2025 at 3:12 PM
Please repost to get the word out! @nkgarg.bsky.social and I are excited to present a personalized feed for academics! It shows posts about papers from accounts you’re following bsky.app/profile/pape...
Reposted by Erica Chiang
I'm excited to use my first post here to introduce the first paper of my PhD, "User-item fairness tradeoffs in recommendations" (NeurIPS 2024)!
This is joint work with Sudalakshmee Chiniah and my advisor @nkgarg.bsky.social
Description/links below: 1/
This is joint work with Sudalakshmee Chiniah and my advisor @nkgarg.bsky.social
Description/links below: 1/

December 11, 2024 at 5:22 AM
I'm excited to use my first post here to introduce the first paper of my PhD, "User-item fairness tradeoffs in recommendations" (NeurIPS 2024)!
This is joint work with Sudalakshmee Chiniah and my advisor @nkgarg.bsky.social
Description/links below: 1/
This is joint work with Sudalakshmee Chiniah and my advisor @nkgarg.bsky.social
Description/links below: 1/