



Jaap Jumelet
@jumelet.bsky.social
Postdoc @rug.nl with Arianna Bisazza.
Interested in NLP, interpretability, syntax, language acquisition and typology.
Interested in NLP, interpretability, syntax, language acquisition and typology.
Pinned
Jaap Jumelet
@jumelet.bsky.social
· Apr 7
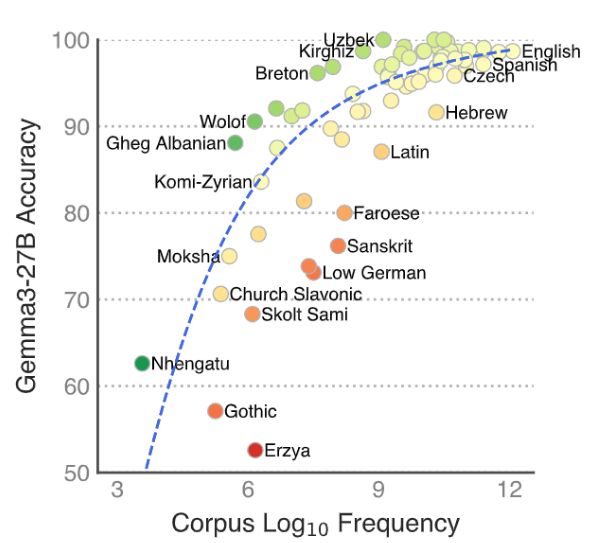
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Reposted by Jaap Jumelet

New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇

November 10, 2025 at 10:11 PM
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768

November 6, 2025 at 7:08 AM
I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Reposted by Jaap Jumelet

With only a week left for #EMNLP2025, we are happy to announce all the works we 🐮 will present 🥳 - come and say "hi" to our posters and presentations during the Main and the co-located events (*SEM and workshops) See you in Suzhou ✈️


October 27, 2025 at 11:54 AM
With only a week left for #EMNLP2025, we are happy to announce all the works we 🐮 will present 🥳 - come and say "hi" to our posters and presentations during the Main and the co-located events (*SEM and workshops) See you in Suzhou ✈️
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!

October 15, 2025 at 10:53 AM
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
Happening now at the SIGTYP poster session! Come talk to Leonie and me about MultiBLiMP!

August 1, 2025 at 10:17 AM
Happening now at the SIGTYP poster session! Come talk to Leonie and me about MultiBLiMP!
Reposted by Jaap Jumelet

I'll be in Vienna only from tomorrow, but today my star PhD student Marianne is already presenting some of our work:
BLIMP-NL, in which we create a large new dataset for syntactic evaluation of Dutch LLMs, and learn a lot about dataset creation, LLM evaluation and grammatical abilities on the way.
BLIMP-NL, in which we create a large new dataset for syntactic evaluation of Dutch LLMs, and learn a lot about dataset creation, LLM evaluation and grammatical abilities on the way.

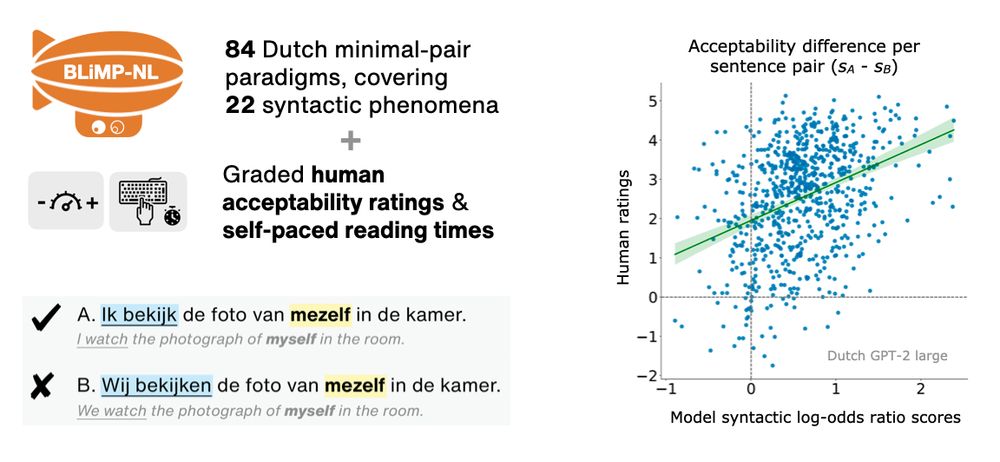
Next week I’ll be in Vienna for my first *ACL conference! 🇦🇹✨
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
I will present our new BLiMP-NL dataset for evaluating language models on Dutch syntactic minimal pairs and human acceptability judgments ⬇️
🗓️ Tuesday, July 29th, 16:00-17:30, Hall X4 / X5 (Austria Center Vienna)
July 29, 2025 at 9:46 AM
I'll be in Vienna only from tomorrow, but today my star PhD student Marianne is already presenting some of our work:
BLIMP-NL, in which we create a large new dataset for syntactic evaluation of Dutch LLMs, and learn a lot about dataset creation, LLM evaluation and grammatical abilities on the way.
BLIMP-NL, in which we create a large new dataset for syntactic evaluation of Dutch LLMs, and learn a lot about dataset creation, LLM evaluation and grammatical abilities on the way.
Reposted by Jaap Jumelet

Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social

TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguis...
arxiv.org
June 19, 2025 at 4:28 PM
Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
Reposted by Jaap Jumelet

Ik snap niet dat hier niet meer ophef over is:
Het binnenhalen van Amerikaanse wetenschappers wordt betaalt door Nederlandse academici geen inflatiecorrectie op hun salaris te geven.
1/2
Het binnenhalen van Amerikaanse wetenschappers wordt betaalt door Nederlandse academici geen inflatiecorrectie op hun salaris te geven.
1/2

June 13, 2025 at 9:00 AM
Ik snap niet dat hier niet meer ophef over is:
Het binnenhalen van Amerikaanse wetenschappers wordt betaalt door Nederlandse academici geen inflatiecorrectie op hun salaris te geven.
1/2
Het binnenhalen van Amerikaanse wetenschappers wordt betaalt door Nederlandse academici geen inflatiecorrectie op hun salaris te geven.
1/2
Reposted by Jaap Jumelet

My paper with @tylerachang.bsky.social and @jamichaelov.bsky.social will appear at #ACL2025NLP! The updated preprint is available on arxiv. I look forward to chatting about bilingual models in Vienna!
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.

June 5, 2025 at 2:18 PM
My paper with @tylerachang.bsky.social and @jamichaelov.bsky.social will appear at #ACL2025NLP! The updated preprint is available on arxiv. I look forward to chatting about bilingual models in Vienna!
Reposted by Jaap Jumelet

“Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models”
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689

Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of ...
arxiv.org
May 30, 2025 at 7:40 AM
“Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models”
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
I’m happy to share that the preprint of my first PhD project is now online!
🎊 Paper: arxiv.org/abs/2505.23689
Reposted by Jaap Jumelet

"A well-delivered lecture isn’t primarily a delivery system for information. It is an ignition point for curiosity, all the better for being experienced in an audience."
Marvellous defence of the increasingly maligned university experience by @patporter76.bsky.social
thecritic.co.uk/university-a...
Marvellous defence of the increasingly maligned university experience by @patporter76.bsky.social
thecritic.co.uk/university-a...

University: a good idea | Patrick Porter | The Critic Magazine
A former student of mine has penned an attack on universities, derived from their own disappointing experience studying Politics and International Relations at the place where I ply my trade. In short...
thecritic.co.uk
May 28, 2025 at 10:37 AM
"A well-delivered lecture isn’t primarily a delivery system for information. It is an ignition point for curiosity, all the better for being experienced in an audience."
Marvellous defence of the increasingly maligned university experience by @patporter76.bsky.social
thecritic.co.uk/university-a...
Marvellous defence of the increasingly maligned university experience by @patporter76.bsky.social
thecritic.co.uk/university-a...
Reposted by Jaap Jumelet

Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
Stellen OBP - Georg-August-Universität Göttingen
Webseiten der Georg-August-Universität Göttingen
www.uni-goettingen.de
May 16, 2025 at 8:23 AM
Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
Reposted by Jaap Jumelet

BlackboxNLP, the leading workshop on interpretability and analysis of language models, will be co-located with EMNLP 2025 in Suzhou this November! 📆
This edition will feature a new shared task on circuits/causal variable localization in LMs, details here: blackboxnlp.github.io/2025/task
This edition will feature a new shared task on circuits/causal variable localization in LMs, details here: blackboxnlp.github.io/2025/task

May 15, 2025 at 8:21 AM
BlackboxNLP, the leading workshop on interpretability and analysis of language models, will be co-located with EMNLP 2025 in Suzhou this November! 📆
This edition will feature a new shared task on circuits/causal variable localization in LMs, details here: blackboxnlp.github.io/2025/task
This edition will feature a new shared task on circuits/causal variable localization in LMs, details here: blackboxnlp.github.io/2025/task
Reposted by Jaap Jumelet

Close your books, test time!
The evaluation pipelines are out, baselines are released & the challenge is on
There is still time to join and
We are excited to learn from you on pretraining and human-model gaps
*Don't forget to fastEval on checkpoints
github.com/babylm/evalu...
📈🤖🧠
#AI #LLMS
The evaluation pipelines are out, baselines are released & the challenge is on
There is still time to join and
We are excited to learn from you on pretraining and human-model gaps
*Don't forget to fastEval on checkpoints
github.com/babylm/evalu...
📈🤖🧠
#AI #LLMS

May 9, 2025 at 2:20 PM
Close your books, test time!
The evaluation pipelines are out, baselines are released & the challenge is on
There is still time to join and
We are excited to learn from you on pretraining and human-model gaps
*Don't forget to fastEval on checkpoints
github.com/babylm/evalu...
📈🤖🧠
#AI #LLMS
The evaluation pipelines are out, baselines are released & the challenge is on
There is still time to join and
We are excited to learn from you on pretraining and human-model gaps
*Don't forget to fastEval on checkpoints
github.com/babylm/evalu...
📈🤖🧠
#AI #LLMS
Reposted by Jaap Jumelet

Pleased to announce our paper was accepted at ICLR 2025 as a Spotlight! I will present our poster on Saturday April 26, 3-5pm, Poster #241. Hope to see you there!
arxiv.org/abs/2409.19151
arxiv.org/abs/2409.19151

Can LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?
Extremely low-resource (XLR) languages lack substantial corpora for training NLP models, motivating the use of all available resources such as dictionaries and grammar books. Machine Translation from ...
arxiv.org
April 25, 2025 at 6:19 AM
Pleased to announce our paper was accepted at ICLR 2025 as a Spotlight! I will present our poster on Saturday April 26, 3-5pm, Poster #241. Hope to see you there!
arxiv.org/abs/2409.19151
arxiv.org/abs/2409.19151
Reposted by Jaap Jumelet

✨ New Paper ✨
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc

April 11, 2025 at 4:04 PM
✨ New Paper ✨
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
Reposted by Jaap Jumelet
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
April 7, 2025 at 2:56 PM
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Reposted by Jaap Jumelet
Modern LLMs "speak" hundreds of languages... but do they really?
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
April 8, 2025 at 12:27 PM
Modern LLMs "speak" hundreds of languages... but do they really?
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
Multilinguality claims are often based on downstream tasks like QA & MT, while *formal* linguistic competence remains hard to gauge in lots of languages
Meet MultiBLiMP!
(joint work w/ @jumelet.bsky.social & @weissweiler.bsky.social)
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
April 7, 2025 at 2:56 PM
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Reposted by Jaap Jumelet

LMs learn argument-based preferences for dative constructions (preferring recipient first when it’s shorter), consistent with humans. Is this from memorizing preferences in training? New paper w/ @kanishka.bsky.social , @weissweiler.bsky.social , @kmahowald.bsky.social
arxiv.org/abs/2503.20850
arxiv.org/abs/2503.20850

March 31, 2025 at 1:30 PM
LMs learn argument-based preferences for dative constructions (preferring recipient first when it’s shorter), consistent with humans. Is this from memorizing preferences in training? New paper w/ @kanishka.bsky.social , @weissweiler.bsky.social , @kmahowald.bsky.social
arxiv.org/abs/2503.20850
arxiv.org/abs/2503.20850
Reposted by Jaap Jumelet

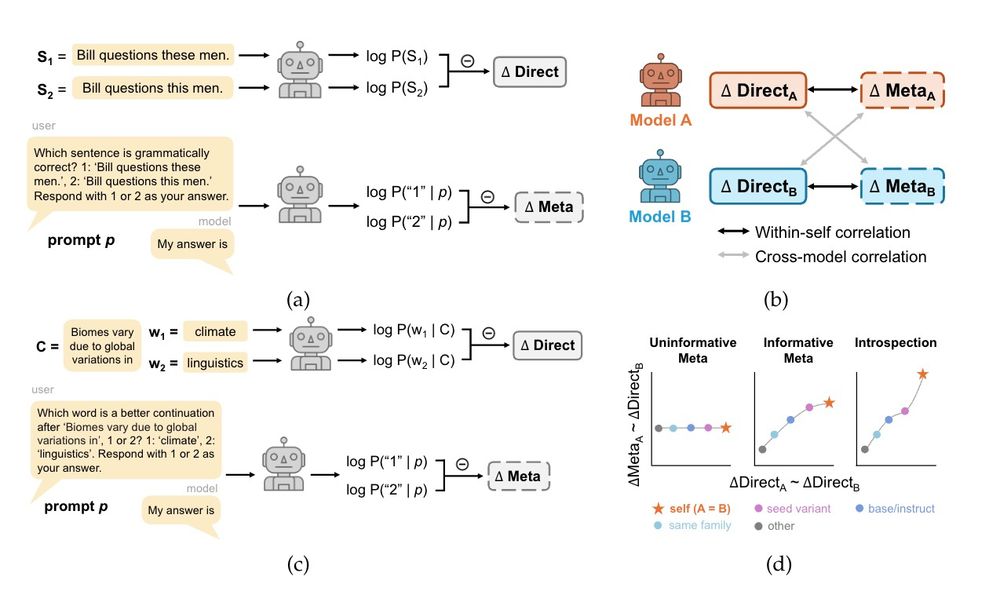
New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
March 12, 2025 at 2:31 PM
New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Reposted by Jaap Jumelet
Excited to be traveling to Estonia for the 1st time to give a keynote @nodalida.bsky.social. I'll talk about using NNs to study language evolution & acquisition.
A teaser: It won't be about LLMs 🙃
Also I've just moved from X, so this was my very first post... Pls help out by connecting with me!
A teaser: It won't be about LLMs 🙃
Also I've just moved from X, so this was my very first post... Pls help out by connecting with me!
March 1, 2025 at 12:05 PM
Excited to be traveling to Estonia for the 1st time to give a keynote @nodalida.bsky.social. I'll talk about using NNs to study language evolution & acquisition.
A teaser: It won't be about LLMs 🙃
Also I've just moved from X, so this was my very first post... Pls help out by connecting with me!
A teaser: It won't be about LLMs 🙃
Also I've just moved from X, so this was my very first post... Pls help out by connecting with me!
Reposted by Jaap Jumelet

✨New paper✨
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195

February 20, 2025 at 3:06 PM
✨New paper✨
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Reposted by Jaap Jumelet

Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10

December 19, 2024 at 1:40 PM
Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
Reposted by Jaap Jumelet

Counterpoint: theconversation.com/are-we-reall...

Are we really about to talk to whales?
It’s certainly an exciting time to study communication in whales and dolphins.
theconversation.com
December 15, 2024 at 9:28 AM
Counterpoint: theconversation.com/are-we-reall...