




Jaap Jumelet
@jumelet.bsky.social
Postdoc @rug.nl with Arianna Bisazza.
Interested in NLP, interpretability, syntax, language acquisition and typology.
Interested in NLP, interpretability, syntax, language acquisition and typology.
I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768

November 6, 2025 at 7:08 AM
I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
Next to our training resources, we also release an evaluation pipeline that assess different aspects of language learning.
We present results for various simple baseline models, but hope this can serve as a starting point for a multilingual BabyLM challenge in future years!
We present results for various simple baseline models, but hope this can serve as a starting point for a multilingual BabyLM challenge in future years!

October 15, 2025 at 10:53 AM
Next to our training resources, we also release an evaluation pipeline that assess different aspects of language learning.
We present results for various simple baseline models, but hope this can serve as a starting point for a multilingual BabyLM challenge in future years!
We present results for various simple baseline models, but hope this can serve as a starting point for a multilingual BabyLM challenge in future years!
To deal with data imbalances, we divide languages into three Tiers. This better enables cross-lingual studies and makes it possible for low-resource languages to be a part of BabyBabelLM as well.

October 15, 2025 at 10:53 AM
To deal with data imbalances, we divide languages into three Tiers. This better enables cross-lingual studies and makes it possible for low-resource languages to be a part of BabyBabelLM as well.
With a fantastic team of international collaborators we have developed a pipeline for creating LM training data from resources that children are exposed to.
We release this pipeline and welcome new contributions!
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159
We release this pipeline and welcome new contributions!
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159

October 15, 2025 at 10:53 AM
With a fantastic team of international collaborators we have developed a pipeline for creating LM training data from resources that children are exposed to.
We release this pipeline and welcome new contributions!
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159
We release this pipeline and welcome new contributions!
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!

October 15, 2025 at 10:53 AM
🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
Happening now at the SIGTYP poster session! Come talk to Leonie and me about MultiBLiMP!

August 1, 2025 at 10:17 AM
Happening now at the SIGTYP poster session! Come talk to Leonie and me about MultiBLiMP!
Person agreement is easier to model than Gender or Number. Sentences with higher overall perplexity lead to less accurate judgements, and models are more likely to pick the wrong inflection if it is split into more tokens. Surprisingly, subject-verb distance has no effect.

April 7, 2025 at 2:56 PM
Person agreement is easier to model than Gender or Number. Sentences with higher overall perplexity lead to less accurate judgements, and models are more likely to pick the wrong inflection if it is split into more tokens. Surprisingly, subject-verb distance has no effect.
We find that boosting specific languages works, but only if you pre-, and not post-train: EuroLLM outperforms same size Llama3 on its target languages, but Aya is not significantly better. Neither of them outperform Llama3 significantly on a language not intentionally included.

April 7, 2025 at 2:56 PM
We find that boosting specific languages works, but only if you pre-, and not post-train: EuroLLM outperforms same size Llama3 on its target languages, but Aya is not significantly better. Neither of them outperform Llama3 significantly on a language not intentionally included.
We evaluate 17 Language Models, among them Llama 3, Aya, and Gemma 3.
Overall, Llama3 70B and Gemma 27B perform best, but the monolingual 500M Goldfish models significantly outperform them in 14 languages!
Base models consistently outperform their instruction-tuned counterparts.
Overall, Llama3 70B and Gemma 27B perform best, but the monolingual 500M Goldfish models significantly outperform them in 14 languages!
Base models consistently outperform their instruction-tuned counterparts.

April 7, 2025 at 2:56 PM
We evaluate 17 Language Models, among them Llama 3, Aya, and Gemma 3.
Overall, Llama3 70B and Gemma 27B perform best, but the monolingual 500M Goldfish models significantly outperform them in 14 languages!
Base models consistently outperform their instruction-tuned counterparts.
Overall, Llama3 70B and Gemma 27B perform best, but the monolingual 500M Goldfish models significantly outperform them in 14 languages!
Base models consistently outperform their instruction-tuned counterparts.
We create 125,000 pairs for 101 languages and six types of agreement, resulting in high diversity across phenomena, typological families, geography, amount of resources available, sentence length, and word frequencies. 43 of our languages are not Indo-European.

April 7, 2025 at 2:56 PM
We create 125,000 pairs for 101 languages and six types of agreement, resulting in high diversity across phenomena, typological families, geography, amount of resources available, sentence length, and word frequencies. 43 of our languages are not Indo-European.
MultiBLiMP is created automatically using Universal Dependencies and Universal Morphology.
We search for subject-verb or -participle pairs with our target features Number, Person, and Gender in UD, then insert the word with the opposite feature value to form a minimal pair.
We search for subject-verb or -participle pairs with our target features Number, Person, and Gender in UD, then insert the word with the opposite feature value to form a minimal pair.

April 7, 2025 at 2:56 PM
MultiBLiMP is created automatically using Universal Dependencies and Universal Morphology.
We search for subject-verb or -participle pairs with our target features Number, Person, and Gender in UD, then insert the word with the opposite feature value to form a minimal pair.
We search for subject-verb or -participle pairs with our target features Number, Person, and Gender in UD, then insert the word with the opposite feature value to form a minimal pair.
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
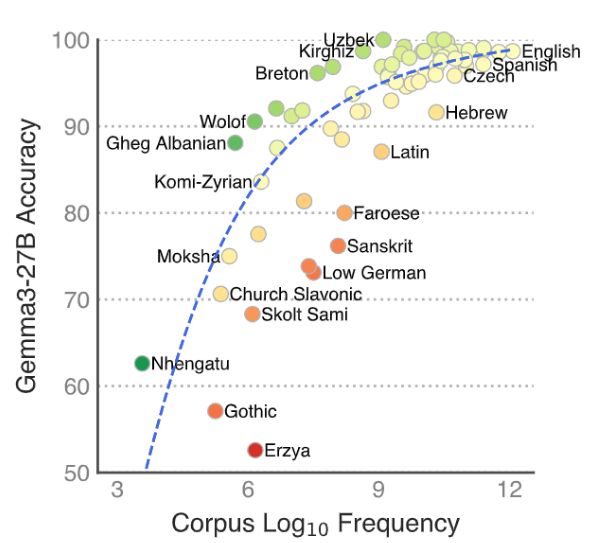
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
April 7, 2025 at 2:56 PM
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
These presuppositions don't often work anymore on the o1 model.

February 20, 2025 at 8:39 AM
These presuppositions don't often work anymore on the o1 model.
I have succesfully defended my thesis yesterday!
Huge thank you to my supervisors @wzuidema.bsky.social and Raquel Fernandez for their guidance, my paranymphs Emile & Jop for their support, my defense committee for their questions, and my brother for photobombing this official portrait!
Huge thank you to my supervisors @wzuidema.bsky.social and Raquel Fernandez for their guidance, my paranymphs Emile & Jop for their support, my defense committee for their questions, and my brother for photobombing this official portrait!

December 11, 2024 at 2:04 PM
I have succesfully defended my thesis yesterday!
Huge thank you to my supervisors @wzuidema.bsky.social and Raquel Fernandez for their guidance, my paranymphs Emile & Jop for their support, my defense committee for their questions, and my brother for photobombing this official portrait!
Huge thank you to my supervisors @wzuidema.bsky.social and Raquel Fernandez for their guidance, my paranymphs Emile & Jop for their support, my defense committee for their questions, and my brother for photobombing this official portrait!
The thesis is more than just a collection of my papers though: if you are interested in these topics I definitely encourage you to have a look at the introduction and conclusion as well, in which I discuss the higher-level aspects of conducting linguistic research in the scope of NLP and vice versa.

November 29, 2024 at 3:49 PM
The thesis is more than just a collection of my papers though: if you are interested in these topics I definitely encourage you to have a look at the introduction and conclusion as well, in which I discuss the higher-level aspects of conducting linguistic research in the scope of NLP and vice versa.
In the third part we present a pipeline for a fully controlled environment to test for linguistic structure.
Using formal grammars we generate languages that yield a fully transparent latent structure.
We use this to test for the presence of hierarchical structure in LM representations.
Using formal grammars we generate languages that yield a fully transparent latent structure.
We use this to test for the presence of hierarchical structure in LM representations.

November 29, 2024 at 3:49 PM
In the third part we present a pipeline for a fully controlled environment to test for linguistic structure.
Using formal grammars we generate languages that yield a fully transparent latent structure.
We use this to test for the presence of hierarchical structure in LM representations.
Using formal grammars we generate languages that yield a fully transparent latent structure.
We use this to test for the presence of hierarchical structure in LM representations.
The second part takes up a stronger view on the connection between data statistics and model behavior: how are linguistic generalizations formed during training?
We present a general methodology for this, and zoom in on 2 phenomena: double adjective constructions and negative polarity items.
We present a general methodology for this, and zoom in on 2 phenomena: double adjective constructions and negative polarity items.

November 29, 2024 at 3:49 PM
The second part takes up a stronger view on the connection between data statistics and model behavior: how are linguistic generalizations formed during training?
We present a general methodology for this, and zoom in on 2 phenomena: double adjective constructions and negative polarity items.
We present a general methodology for this, and zoom in on 2 phenomena: double adjective constructions and negative polarity items.
I grouped my work into 3 parts. First, we take a behavioral perspective to linguistic structure in LMs, through the paradigm of Structural Priming.
We show that LMs exhibit priming effects, driven by similar cues as those in humans.
aclanthology.org/2022.tacl-1....
aclanthology.org/2024.finding...
We show that LMs exhibit priming effects, driven by similar cues as those in humans.
aclanthology.org/2022.tacl-1....
aclanthology.org/2024.finding...

November 29, 2024 at 3:49 PM
I grouped my work into 3 parts. First, we take a behavioral perspective to linguistic structure in LMs, through the paradigm of Structural Priming.
We show that LMs exhibit priming effects, driven by similar cues as those in humans.
aclanthology.org/2022.tacl-1....
aclanthology.org/2024.finding...
We show that LMs exhibit priming effects, driven by similar cues as those in humans.
aclanthology.org/2022.tacl-1....
aclanthology.org/2024.finding...
My PhD thesis is now available online! It is called "Finding Structure in Language Models" and presents the work I have done in the past 4 years on the intersection of NLP, interpretability, and linguistics.
I'll defend it on December 10, streamed here: jumelet.ai/phd
arxiv.org/abs/2411.16433
🧵
I'll defend it on December 10, streamed here: jumelet.ai/phd
arxiv.org/abs/2411.16433
🧵

November 29, 2024 at 3:49 PM
My PhD thesis is now available online! It is called "Finding Structure in Language Models" and presents the work I have done in the past 4 years on the intersection of NLP, interpretability, and linguistics.
I'll defend it on December 10, streamed here: jumelet.ai/phd
arxiv.org/abs/2411.16433
🧵
I'll defend it on December 10, streamed here: jumelet.ai/phd
arxiv.org/abs/2411.16433
🧵