




Jiaang Li
@jiaangli.bsky.social
PhD student at University of Copenhagen @belongielab.org | #nlp #computervision | ELLIS student @ellis.eu
🌐 https://jiaangli.github.io/
🌐 https://jiaangli.github.io/
Feel free to reach out and chat with Xinyi on July 18th in Vancouver at the #ICML

Excited to present at the #ICML2025 World Models Workshop!
📅 July 18, 15:45–17:00
🧠 What if Othello-Playing Language Models Could See?
We show that visual grounding improves prediction & internal structure.♟️
📅 July 18, 15:45–17:00
🧠 What if Othello-Playing Language Models Could See?
We show that visual grounding improves prediction & internal structure.♟️

July 14, 2025 at 8:36 AM
Feel free to reach out and chat with Xinyi on July 18th in Vancouver at the #ICML
Reposted by Jiaang Li

Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
Reposted by Jiaang Li

Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
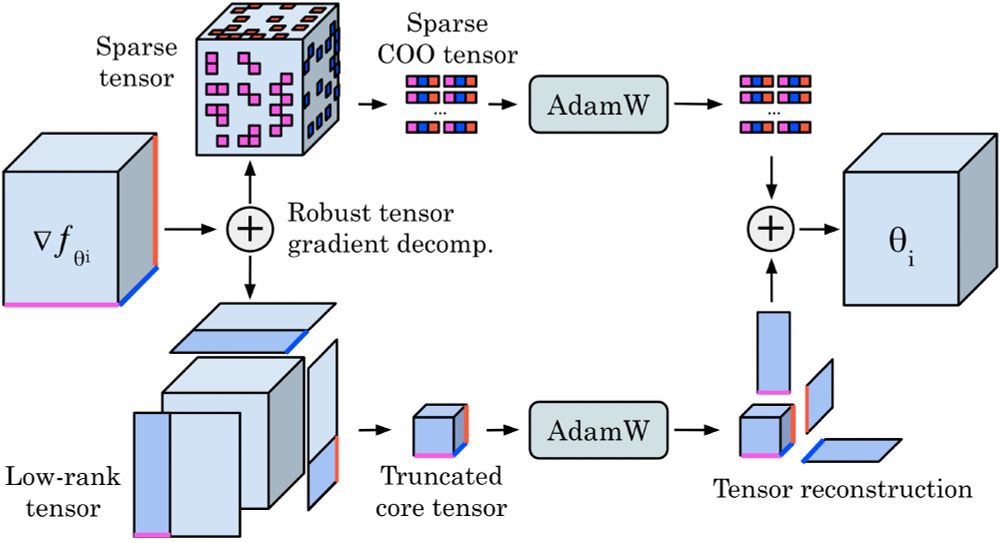
June 3, 2025 at 3:17 AM
Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
Reposted by Jiaang Li

PhD student, Jiaang Li and his collaborators, with insights into cultural understanding of vision-language models 👇
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇

June 2, 2025 at 6:12 PM
PhD student, Jiaang Li and his collaborators, with insights into cultural understanding of vision-language models 👇
Reposted by Jiaang Li

I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793

June 2, 2025 at 10:36 AM
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
May 23, 2025 at 5:04 PM
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Reposted by Jiaang Li

I won’t be attending #ICLR in person this year😢. But feel free to check our paper ‘Revisiting the Othello World Model Hypothesis’ with Anders Søgaard, accepted at ICLR world models workshop!
Paper link arxiv.org/abs/2503.04421
Paper link arxiv.org/abs/2503.04421

Revisiting the Othello World Model Hypothesis
Li et al. (2023) used the Othello board game as a test case for the ability of GPT-2 to induce world models, and were followed up by Nanda et al. (2023b). We briefly discuss the original experiments, ...
arxiv.org
April 21, 2025 at 9:09 PM
I won’t be attending #ICLR in person this year😢. But feel free to check our paper ‘Revisiting the Othello World Model Hypothesis’ with Anders Søgaard, accepted at ICLR world models workshop!
Paper link arxiv.org/abs/2503.04421
Paper link arxiv.org/abs/2503.04421
Reposted by Jiaang Li

Thrilled to announce "Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation" is accepted as a Spotlight (5%) at #ICLR2025!
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇

February 11, 2025 at 5:49 PM
Thrilled to announce "Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation" is accepted as a Spotlight (5%) at #ICLR2025!
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
Reposted by Jiaang Li

Forget just thinking in words.
🔔Our New Preprint:
🚀 New Era of Multimodal Reasoning🚨
🔍 Imagine While Reasoning in Space with MVoT
Multimodal Visualization-of-Thought (MVoT) revolutionizes reasoning by generating visual "thoughts" that transform how AI thinks, reasons, and explains itself.
🔔Our New Preprint:
🚀 New Era of Multimodal Reasoning🚨
🔍 Imagine While Reasoning in Space with MVoT
Multimodal Visualization-of-Thought (MVoT) revolutionizes reasoning by generating visual "thoughts" that transform how AI thinks, reasons, and explains itself.

January 14, 2025 at 2:50 PM
Forget just thinking in words.
🔔Our New Preprint:
🚀 New Era of Multimodal Reasoning🚨
🔍 Imagine While Reasoning in Space with MVoT
Multimodal Visualization-of-Thought (MVoT) revolutionizes reasoning by generating visual "thoughts" that transform how AI thinks, reasons, and explains itself.
🔔Our New Preprint:
🚀 New Era of Multimodal Reasoning🚨
🔍 Imagine While Reasoning in Space with MVoT
Multimodal Visualization-of-Thought (MVoT) revolutionizes reasoning by generating visual "thoughts" that transform how AI thinks, reasons, and explains itself.
Reposted by Jiaang Li

FGVC12 Workshop is coming to #CVPR 2025 in Nashville!
Are you working on fine-grained visual problems?
This year we have two peer-reviewed paper tracks:
i) 8-page CVPR Workshop proceedings
ii) 4-page non-archival extended abstracts
CALL FOR PAPERS: sites.google.com/view/fgvc12/...
Are you working on fine-grained visual problems?
This year we have two peer-reviewed paper tracks:
i) 8-page CVPR Workshop proceedings
ii) 4-page non-archival extended abstracts
CALL FOR PAPERS: sites.google.com/view/fgvc12/...
January 9, 2025 at 5:36 PM
FGVC12 Workshop is coming to #CVPR 2025 in Nashville!
Are you working on fine-grained visual problems?
This year we have two peer-reviewed paper tracks:
i) 8-page CVPR Workshop proceedings
ii) 4-page non-archival extended abstracts
CALL FOR PAPERS: sites.google.com/view/fgvc12/...
Are you working on fine-grained visual problems?
This year we have two peer-reviewed paper tracks:
i) 8-page CVPR Workshop proceedings
ii) 4-page non-archival extended abstracts
CALL FOR PAPERS: sites.google.com/view/fgvc12/...
Reposted by Jiaang Li
Here’s a short film produced by the Danish Royal Academy of Sciences, showcasing the WineSensed 🍷 project of Þóranna Bender et al. thoranna.github.io/learning_to_...

VidenSkaber | Min AI forstår mig ikke - professor Serge Belongie
YouTube video by Videnskabernes Selskab
youtu.be
December 30, 2024 at 11:05 AM
Here’s a short film produced by the Danish Royal Academy of Sciences, showcasing the WineSensed 🍷 project of Þóranna Bender et al. thoranna.github.io/learning_to_...
Reposted by Jiaang Li
From San Diego to New York to Copenhagen, wishing you Happy Holidays!🎄

December 21, 2024 at 11:20 AM
From San Diego to New York to Copenhagen, wishing you Happy Holidays!🎄
Reposted by Jiaang Li
With @neuripsconf.bsky.social right around the corner, we’re excited to be presenting our work soon! Here’s an overview
(1/5)
(1/5)
December 3, 2024 at 11:43 AM
With @neuripsconf.bsky.social right around the corner, we’re excited to be presenting our work soon! Here’s an overview
(1/5)
(1/5)
Reposted by Jiaang Li
Here’s a starter pack with members of our lab that have joined Bluesky

Belongie Lab
Join the conversation
go.bsky.app
November 25, 2024 at 10:42 AM
Here’s a starter pack with members of our lab that have joined Bluesky
Reposted by Jiaang Li

No one can explain stochastic gradient descent better than this panda.

a panda bear is rolling around in the grass in a zoo enclosure .
Alt: a panda bear is rolling around in the grass in a zoo enclosure .
media.tenor.com
November 24, 2024 at 3:04 PM
No one can explain stochastic gradient descent better than this panda.
🤔Do Vision and Language Models Share Concepts? 🚀
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...

November 19, 2024 at 12:48 PM
🤔Do Vision and Language Models Share Concepts? 🚀
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
Reposted by Jiaang Li

I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!

November 19, 2024 at 10:38 AM
I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Reposted by Jiaang Li
Logging on! 🧑💻🦋 We're the Belongie Lab led by @sergebelongie.bsky.social. We study Computer Vision and Machine Learning, located at the University of Copenhagen and Pioneer Centre for AI. Follow along to hear about our research past and present! www.belongielab.org
Belongie Lab - Home
Belongie Lab -- Home.
www.belongielab.org
November 17, 2024 at 12:36 PM
Logging on! 🧑💻🦋 We're the Belongie Lab led by @sergebelongie.bsky.social. We study Computer Vision and Machine Learning, located at the University of Copenhagen and Pioneer Centre for AI. Follow along to hear about our research past and present! www.belongielab.org
Reposted by Jiaang Li
A new approach to training models in memory-constrained settings, LoQT allows for the pre-training of a 13B LLM on a 24GB GPU without model parallelism, checkpointing, or offloading strategies during training
Code: github.com/sebulo/LoQT
Code: github.com/sebulo/LoQT

GitHub - sebulo/LoQT
Contribute to sebulo/LoQT development by creating an account on GitHub.
github.com
November 17, 2024 at 9:16 PM
A new approach to training models in memory-constrained settings, LoQT allows for the pre-training of a 13B LLM on a 24GB GPU without model parallelism, checkpointing, or offloading strategies during training
Code: github.com/sebulo/LoQT
Code: github.com/sebulo/LoQT