




Jiaang Li
@jiaangli.bsky.social
PhD student at University of Copenhagen @belongielab.org | #nlp #computervision | ELLIS student @ellis.eu
🌐 https://jiaangli.github.io/
🌐 https://jiaangli.github.io/
📊Our experiments demonstrate that even lightweight VLMs, when augmented with culturally relevant retrievals, outperform their non-augmented counterparts and even surpass the next larger model tier, achieving at least a 3.2% improvement in cVQA and 6.2% in cIC.

May 23, 2025 at 5:04 PM
📊Our experiments demonstrate that even lightweight VLMs, when augmented with culturally relevant retrievals, outperform their non-augmented counterparts and even surpass the next larger model tier, achieving at least a 3.2% improvement in cVQA and 6.2% in cIC.
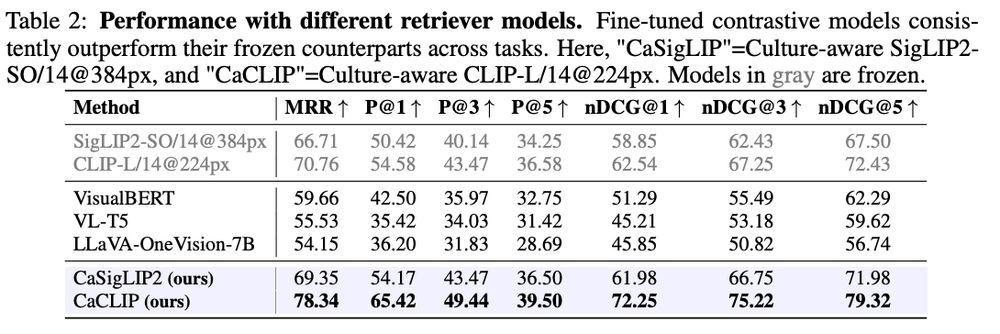
🛠Culture-Aware Contrastive Learning
We propose Culture-aware Contrastive (CAC) Learning, a supervised learning framework compatible with both CLIP and SigLIP architectures. Fine-tuning with CAC can help models better capture culturally significant content.
We propose Culture-aware Contrastive (CAC) Learning, a supervised learning framework compatible with both CLIP and SigLIP architectures. Fine-tuning with CAC can help models better capture culturally significant content.
May 23, 2025 at 5:04 PM
🛠Culture-Aware Contrastive Learning
We propose Culture-aware Contrastive (CAC) Learning, a supervised learning framework compatible with both CLIP and SigLIP architectures. Fine-tuning with CAC can help models better capture culturally significant content.
We propose Culture-aware Contrastive (CAC) Learning, a supervised learning framework compatible with both CLIP and SigLIP architectures. Fine-tuning with CAC can help models better capture culturally significant content.
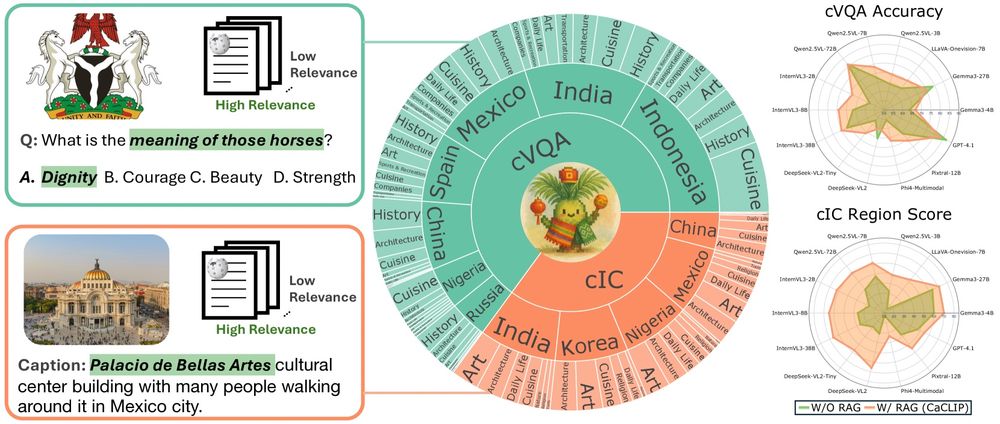
📚 Dataset Construction
RAVENEA integrates 1,800+ images, 2,000+ culture-related questions, 500+ human captions, and 10,000+ human-ranked Wikipedia documents to support two key tasks:
🎯Culture-focused Visual Question Answering (cVQA)
📝Culture-informed Image Captioning (cIC)
RAVENEA integrates 1,800+ images, 2,000+ culture-related questions, 500+ human captions, and 10,000+ human-ranked Wikipedia documents to support two key tasks:
🎯Culture-focused Visual Question Answering (cVQA)
📝Culture-informed Image Captioning (cIC)
May 23, 2025 at 5:04 PM
📚 Dataset Construction
RAVENEA integrates 1,800+ images, 2,000+ culture-related questions, 500+ human captions, and 10,000+ human-ranked Wikipedia documents to support two key tasks:
🎯Culture-focused Visual Question Answering (cVQA)
📝Culture-informed Image Captioning (cIC)
RAVENEA integrates 1,800+ images, 2,000+ culture-related questions, 500+ human captions, and 10,000+ human-ranked Wikipedia documents to support two key tasks:
🎯Culture-focused Visual Question Answering (cVQA)
📝Culture-informed Image Captioning (cIC)
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇

May 23, 2025 at 5:04 PM
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇

🌱We then discuss the implications of our finding:
- the LM understanding debate
- the study of emergent properties
- philosophy
🧵(6/8)
- the LM understanding debate
- the study of emergent properties
- philosophy
🧵(6/8)
November 19, 2024 at 1:12 PM
🌱We then discuss the implications of our finding:
- the LM understanding debate
- the study of emergent properties
- philosophy
🧵(6/8)
- the LM understanding debate
- the study of emergent properties
- philosophy
🧵(6/8)
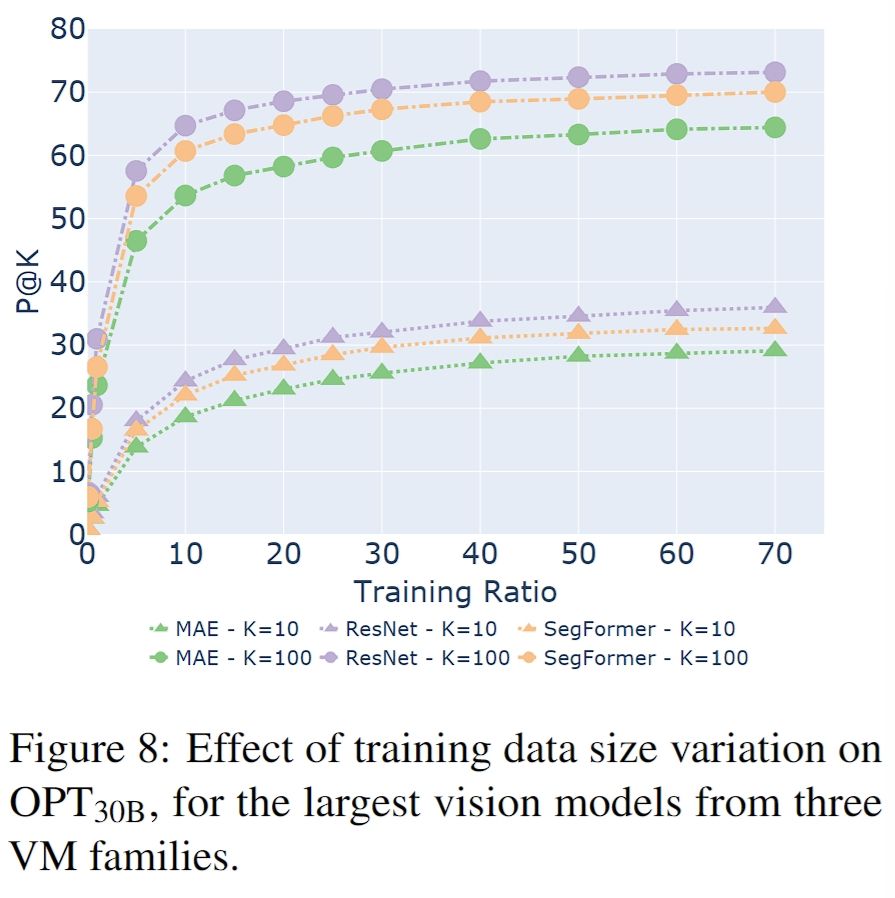
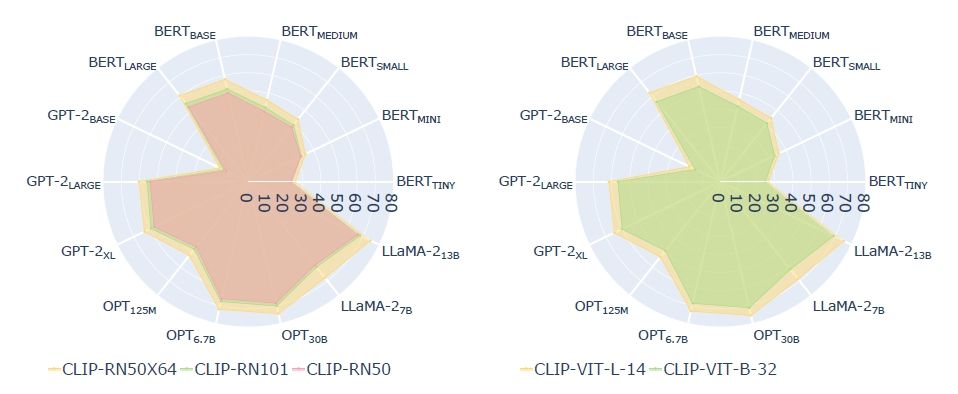
🔍We also measure the generalization of the mapping to other POS, and explore the impact of different size of the training data. 👀To investigate the effects of incorporating text signals during vision pretraining, we compare pure vision models against selected CLIP vision encoders.
🧵(5/8)
🧵(5/8)

November 19, 2024 at 1:01 PM
🔍We also measure the generalization of the mapping to other POS, and explore the impact of different size of the training data. 👀To investigate the effects of incorporating text signals during vision pretraining, we compare pure vision models against selected CLIP vision encoders.
🧵(5/8)
🧵(5/8)
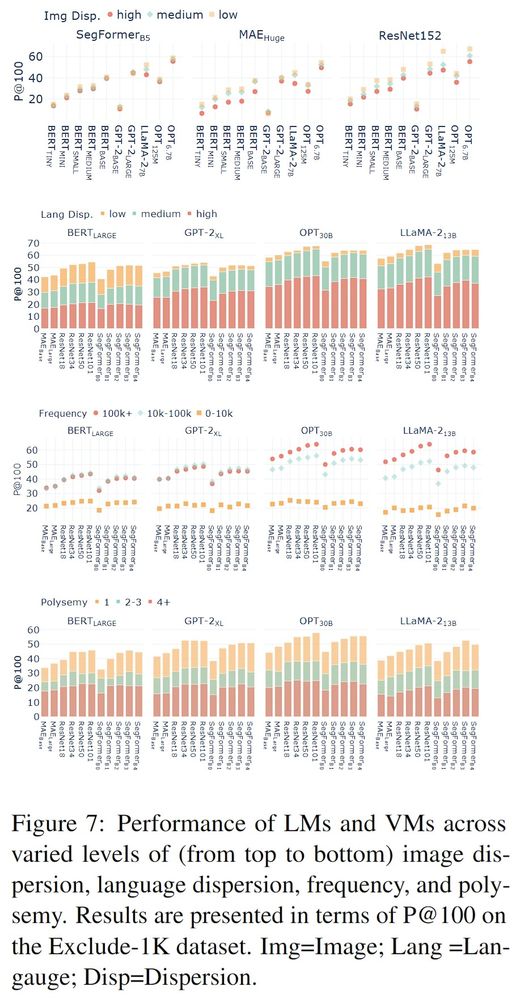
What factors influence the convergence?
🔍Our experiments show the alignability of LMs
and vision models is sensitive to image and language dispersion, polysemy, and frequency.
🧵(4/8)
🔍Our experiments show the alignability of LMs
and vision models is sensitive to image and language dispersion, polysemy, and frequency.
🧵(4/8)
November 19, 2024 at 12:48 PM
What factors influence the convergence?
🔍Our experiments show the alignability of LMs
and vision models is sensitive to image and language dispersion, polysemy, and frequency.
🧵(4/8)
🔍Our experiments show the alignability of LMs
and vision models is sensitive to image and language dispersion, polysemy, and frequency.
🧵(4/8)
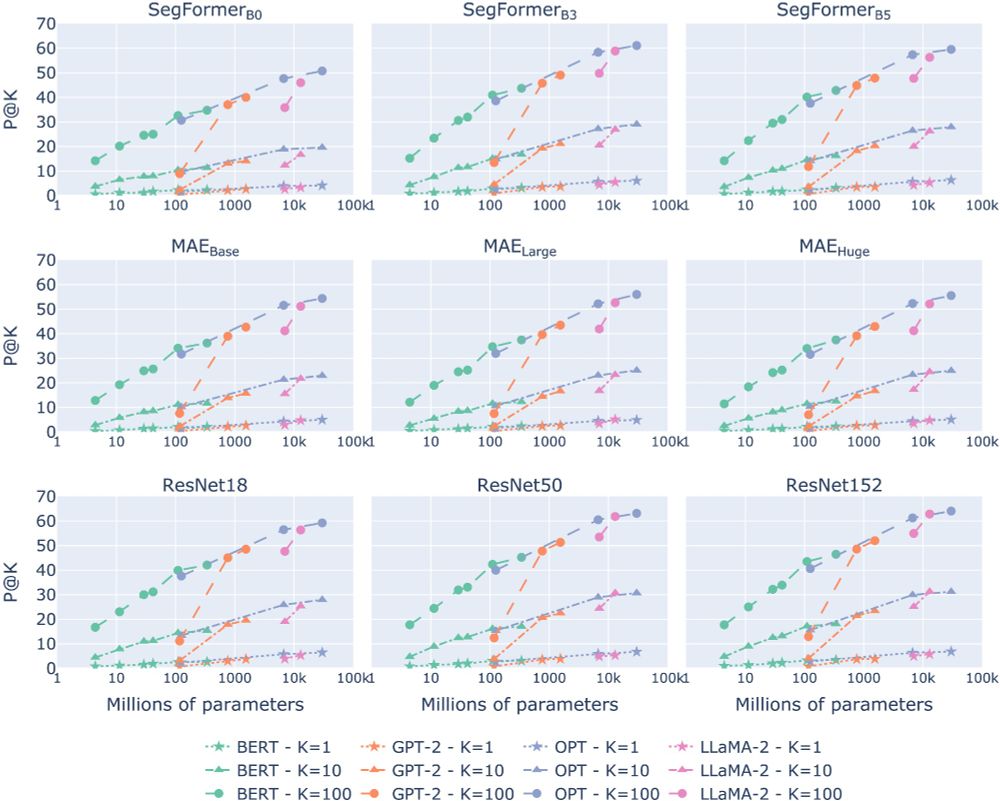
The results show a clear trend:
✨LMs converge toward the geometry of visual models as they grow bigger and better.
🧵(3/8)
✨LMs converge toward the geometry of visual models as they grow bigger and better.
🧵(3/8)
November 19, 2024 at 12:48 PM
The results show a clear trend:
✨LMs converge toward the geometry of visual models as they grow bigger and better.
🧵(3/8)
✨LMs converge toward the geometry of visual models as they grow bigger and better.
🧵(3/8)
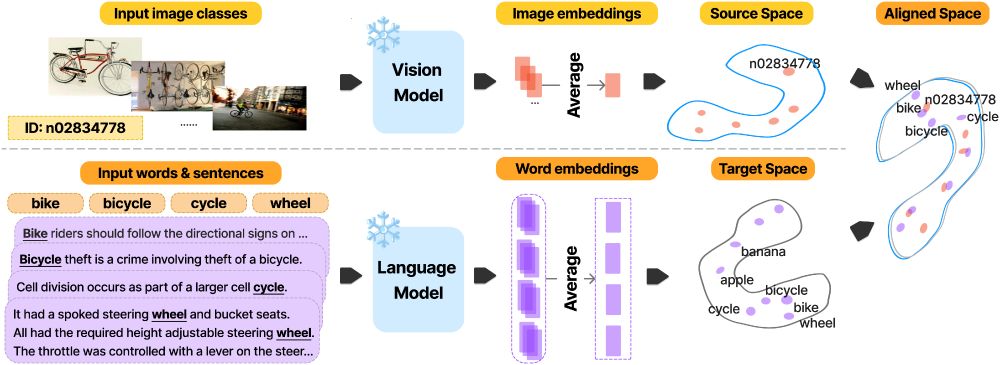
Mapping vector spaces:
🎯We measure the alignment between vision models and LMs by mapping their vector spaces and evaluating retrieval precision on held-out data.
🧵(2/8)
🎯We measure the alignment between vision models and LMs by mapping their vector spaces and evaluating retrieval precision on held-out data.
🧵(2/8)
November 19, 2024 at 12:48 PM
Mapping vector spaces:
🎯We measure the alignment between vision models and LMs by mapping their vector spaces and evaluating retrieval precision on held-out data.
🧵(2/8)
🎯We measure the alignment between vision models and LMs by mapping their vector spaces and evaluating retrieval precision on held-out data.
🧵(2/8)
🤔Do Vision and Language Models Share Concepts? 🚀
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...

November 19, 2024 at 12:48 PM
🤔Do Vision and Language Models Share Concepts? 🚀
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...