



Jaswanth Reddy
@jasreddy.bsky.social
AI Engineer | Exploring LLMs, RAG, and Fine-Tuning
Reposted by Jaswanth Reddy

Microsoft's MarkItDown
The MarkItDown library is a utility tool for converting various files to Markdown (e.g., for indexing, text analysis, etc.)
Repo: github.com/microsoft/ma...
The MarkItDown library is a utility tool for converting various files to Markdown (e.g., for indexing, text analysis, etc.)
Repo: github.com/microsoft/ma...

GitHub - microsoft/markitdown: Python tool for converting files and office documents to Markdown.
Python tool for converting files and office documents to Markdown. - microsoft/markitdown
github.com
December 12, 2024 at 9:56 PM
Microsoft's MarkItDown
The MarkItDown library is a utility tool for converting various files to Markdown (e.g., for indexing, text analysis, etc.)
Repo: github.com/microsoft/ma...
The MarkItDown library is a utility tool for converting various files to Markdown (e.g., for indexing, text analysis, etc.)
Repo: github.com/microsoft/ma...
Reposted by Jaswanth Reddy

For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
December 3, 2024 at 9:21 AM
For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
Reposted by Jaswanth Reddy

Struggling with RAG over PDF files?
You might want to give Docling a try.
𝗪𝗵𝗮𝘁'𝘀 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Python package by IBM
• OS (MIT license)
• PDF, DOCX, PPTX → Markdown, JSON
𝗪𝗵𝘆 𝘂𝘀𝗲 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Doesn’t require fancy gear, lots of memory, or cloud services
• Works on regular computers or Google Colab Pro
You might want to give Docling a try.
𝗪𝗵𝗮𝘁'𝘀 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Python package by IBM
• OS (MIT license)
• PDF, DOCX, PPTX → Markdown, JSON
𝗪𝗵𝘆 𝘂𝘀𝗲 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Doesn’t require fancy gear, lots of memory, or cloud services
• Works on regular computers or Google Colab Pro

November 28, 2024 at 1:34 PM
Struggling with RAG over PDF files?
You might want to give Docling a try.
𝗪𝗵𝗮𝘁'𝘀 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Python package by IBM
• OS (MIT license)
• PDF, DOCX, PPTX → Markdown, JSON
𝗪𝗵𝘆 𝘂𝘀𝗲 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Doesn’t require fancy gear, lots of memory, or cloud services
• Works on regular computers or Google Colab Pro
You might want to give Docling a try.
𝗪𝗵𝗮𝘁'𝘀 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Python package by IBM
• OS (MIT license)
• PDF, DOCX, PPTX → Markdown, JSON
𝗪𝗵𝘆 𝘂𝘀𝗲 𝗗𝗼𝗰𝗹𝗶𝗻𝗴?
• Doesn’t require fancy gear, lots of memory, or cloud services
• Works on regular computers or Google Colab Pro
Reposted by Jaswanth Reddy
Improve the LLM inference with a long context time by up to 11x while preserving 95-100% of accuracy.
Nvidia's Star Attention: Efficient LLM Inference over Long Sequences
Nvidia's Star Attention: Efficient LLM Inference over Long Sequences

November 27, 2024 at 5:58 PM
Improve the LLM inference with a long context time by up to 11x while preserving 95-100% of accuracy.
Nvidia's Star Attention: Efficient LLM Inference over Long Sequences
Nvidia's Star Attention: Efficient LLM Inference over Long Sequences
Reposted by Jaswanth Reddy

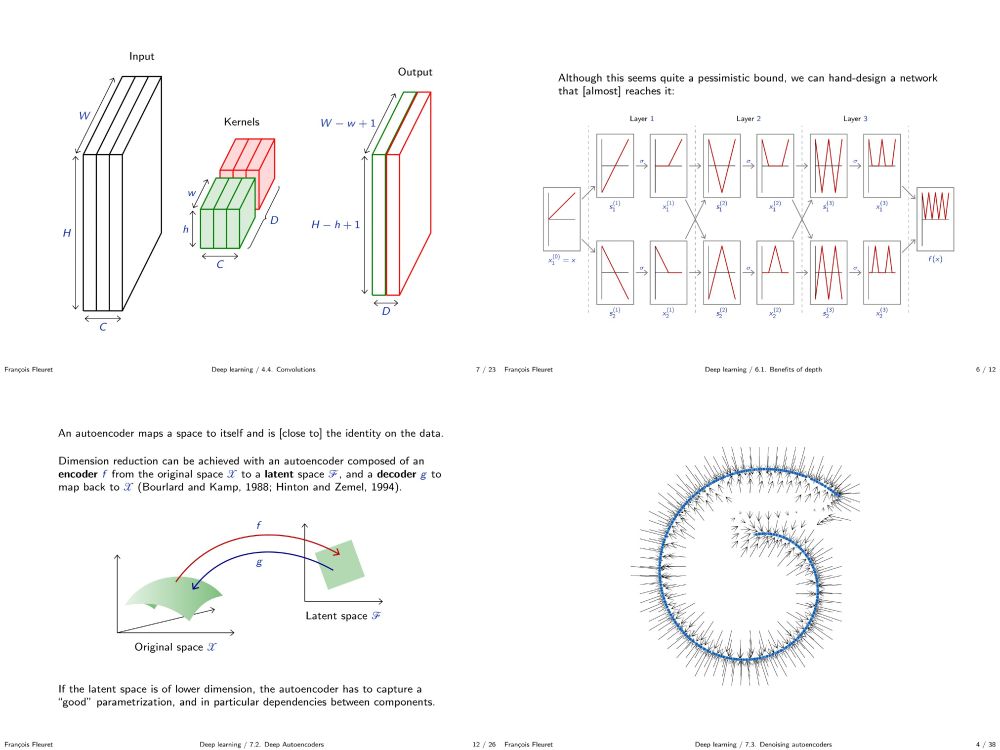
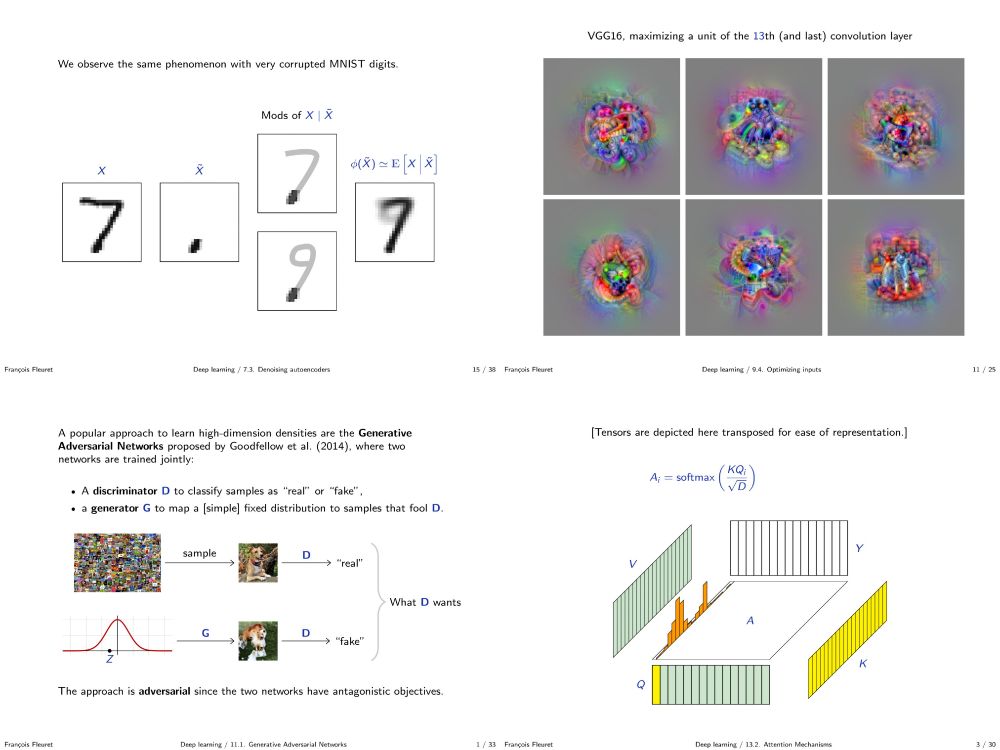
My deep learning course at the University of Geneva is available on-line. 1000+ slides, ~20h of screen-casts. Full of examples in PyTorch.
fleuret.org/dlc/
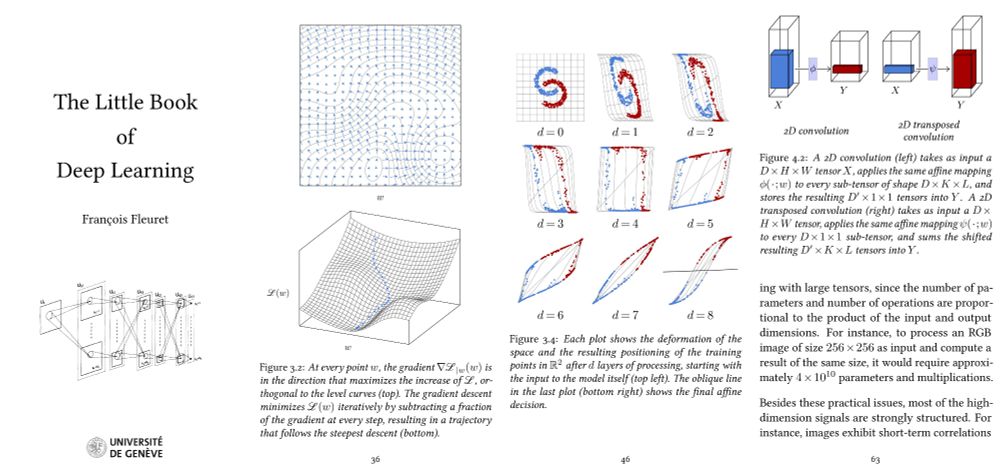
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
November 26, 2024 at 6:15 AM
My deep learning course at the University of Geneva is available on-line. 1000+ slides, ~20h of screen-casts. Full of examples in PyTorch.
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
fleuret.org/dlc/
And my "Little Book of Deep Learning" is available as a phone-formatted pdf (nearing 700k downloads!)
fleuret.org/lbdl/
Reposted by Jaswanth Reddy

Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.

November 22, 2024 at 11:27 AM
Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led b UCL DARK's @dpaglieri.bsky.social! Douwe Kiela plot below is maybe the scariest for AI progress — LLM benchmarks are saturating at an accelerating rate. BALROG to the rescue. This will keep us busy for years.
Reposted by Jaswanth Reddy

LLMs generate novel word sequences not contained in their pretraining data. However, compared to humans, models generate significantly fewer novel n-grams.
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265

November 22, 2024 at 6:14 AM
LLMs generate novel word sequences not contained in their pretraining data. However, compared to humans, models generate significantly fewer novel n-grams.
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265
Reposted by Jaswanth Reddy

Hot take: if you believe that talk therapy is useful, you have to believe that LLMs will eventually be the best and most available therapists
November 22, 2024 at 12:45 PM
Hot take: if you believe that talk therapy is useful, you have to believe that LLMs will eventually be the best and most available therapists
Reposted by Jaswanth Reddy

Just realized BlueSky allows sharing valuable stuff cause it doesn't punish links. 🤩
Let's start with "What are embeddings" by @vickiboykis.com
The book is a great summary of embeddings, from history to modern approaches.
The best part: it's free.
Link: vickiboykis.com/what_are_emb...
Let's start with "What are embeddings" by @vickiboykis.com
The book is a great summary of embeddings, from history to modern approaches.
The best part: it's free.
Link: vickiboykis.com/what_are_emb...



November 22, 2024 at 11:13 AM
Just realized BlueSky allows sharing valuable stuff cause it doesn't punish links. 🤩
Let's start with "What are embeddings" by @vickiboykis.com
The book is a great summary of embeddings, from history to modern approaches.
The best part: it's free.
Link: vickiboykis.com/what_are_emb...
Let's start with "What are embeddings" by @vickiboykis.com
The book is a great summary of embeddings, from history to modern approaches.
The best part: it's free.
Link: vickiboykis.com/what_are_emb...
Reposted by Jaswanth Reddy

Why are some LLMs better at chess than others
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/

Something weird is happening with LLMs and chess
are they good or bad?
dynomight.net
November 22, 2024 at 4:16 PM
Why are some LLMs better at chess than others
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Reposted by Jaswanth Reddy

What's the secret sauce of SmolLM2 to beat LLM titans like Llama3.2 and Qwen2.5?
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
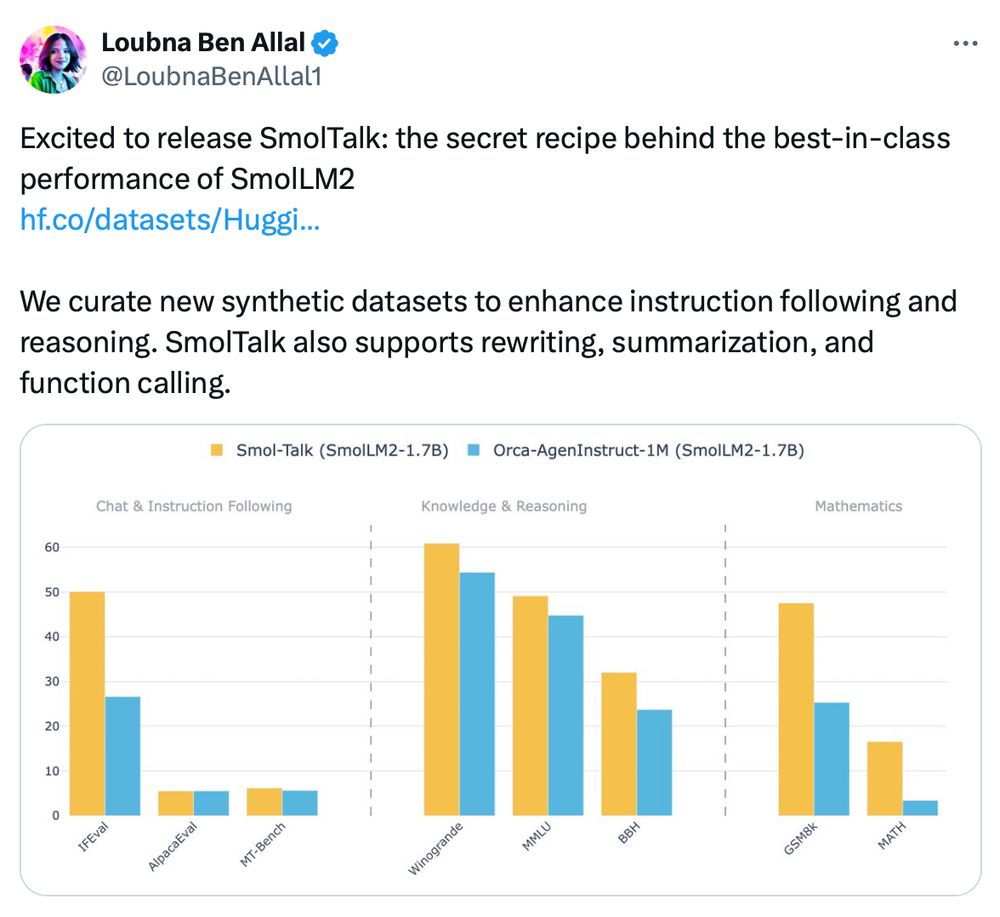
November 21, 2024 at 2:17 PM
What's the secret sauce of SmolLM2 to beat LLM titans like Llama3.2 and Qwen2.5?
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
Reposted by Jaswanth Reddy
Free eBook: Machine Learning Systems by Vijay Janapa Reddi
Principles and Practices of Engineering Artificially Intelligent Systems
mlsysbook.ai
Principles and Practices of Engineering Artificially Intelligent Systems
mlsysbook.ai

November 21, 2024 at 3:05 AM
Free eBook: Machine Learning Systems by Vijay Janapa Reddi
Principles and Practices of Engineering Artificially Intelligent Systems
mlsysbook.ai
Principles and Practices of Engineering Artificially Intelligent Systems
mlsysbook.ai
Reposted by Jaswanth Reddy
Oh wow!
A surprising result from Databricks when measuring embeddings and rerankers on internal evals.
1- Reranking few docs improves recall (expected).
2- Reranking many docs degrades quality (!).
3- Reranking too many documents is quite often worse than using embedding model alone (!!).
A surprising result from Databricks when measuring embeddings and rerankers on internal evals.
1- Reranking few docs improves recall (expected).
2- Reranking many docs degrades quality (!).
3- Reranking too many documents is quite often worse than using embedding model alone (!!).

November 20, 2024 at 8:46 PM
Oh wow!
A surprising result from Databricks when measuring embeddings and rerankers on internal evals.
1- Reranking few docs improves recall (expected).
2- Reranking many docs degrades quality (!).
3- Reranking too many documents is quite often worse than using embedding model alone (!!).
A surprising result from Databricks when measuring embeddings and rerankers on internal evals.
1- Reranking few docs improves recall (expected).
2- Reranking many docs degrades quality (!).
3- Reranking too many documents is quite often worse than using embedding model alone (!!).
Reposted by Jaswanth Reddy
DeepSeek-R1-Lite-Preview Test Number 1

November 20, 2024 at 3:24 PM
DeepSeek-R1-Lite-Preview Test Number 1
Reposted by Jaswanth Reddy
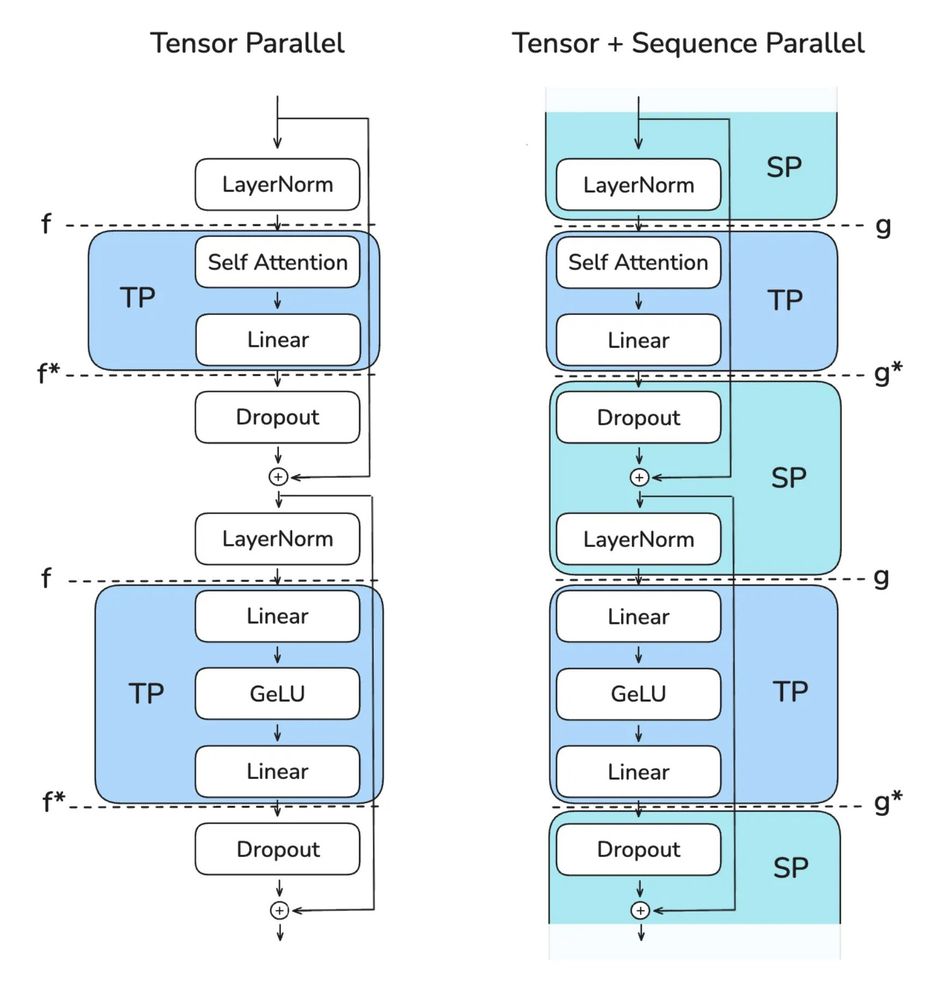
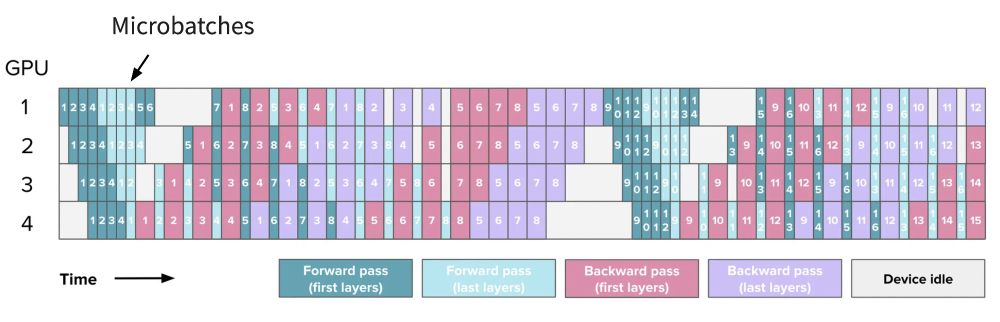
All the things you need to know to pretrain an LLM at home*!
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
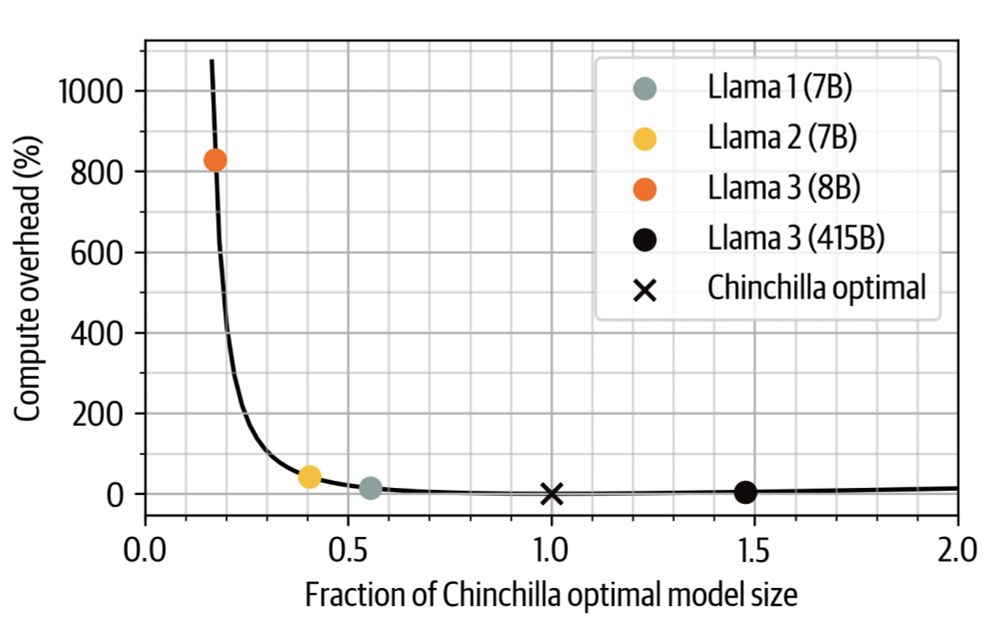
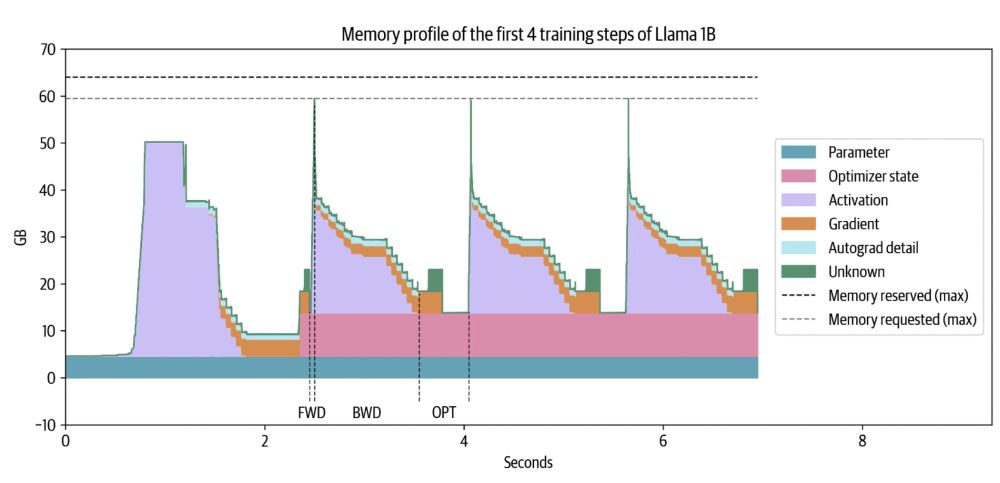
November 19, 2024 at 8:37 PM
All the things you need to know to pretrain an LLM at home*!
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster