



Jack Hessel
@jmhessel.bsky.social
jmhessel.com
@Anthropic. Seattle bike lane enjoyer. Opinions my own.
@Anthropic. Seattle bike lane enjoyer. Opinions my own.
life update: a few weeks ago, I made the difficult decision to move on from Samaya AI. Thank you to my collaborators for an exciting 2 years!! ❤️ Starting next month, I'll be joining Anthropic. Excited for a new adventure! 🦾
(I'm still based in Seattle 🏔️🌲🏕️; but in SF regularly)
(I'm still based in Seattle 🏔️🌲🏕️; but in SF regularly)

August 20, 2025 at 12:43 AM
life update: a few weeks ago, I made the difficult decision to move on from Samaya AI. Thank you to my collaborators for an exciting 2 years!! ❤️ Starting next month, I'll be joining Anthropic. Excited for a new adventure! 🦾
(I'm still based in Seattle 🏔️🌲🏕️; but in SF regularly)
(I'm still based in Seattle 🏔️🌲🏕️; but in SF regularly)
Reposted by Jack Hessel

It is a major policy failure that the US cannot accommodate top AI conferences due to visa issues.
buff.ly/DRJOGrB
buff.ly/DRJOGrB
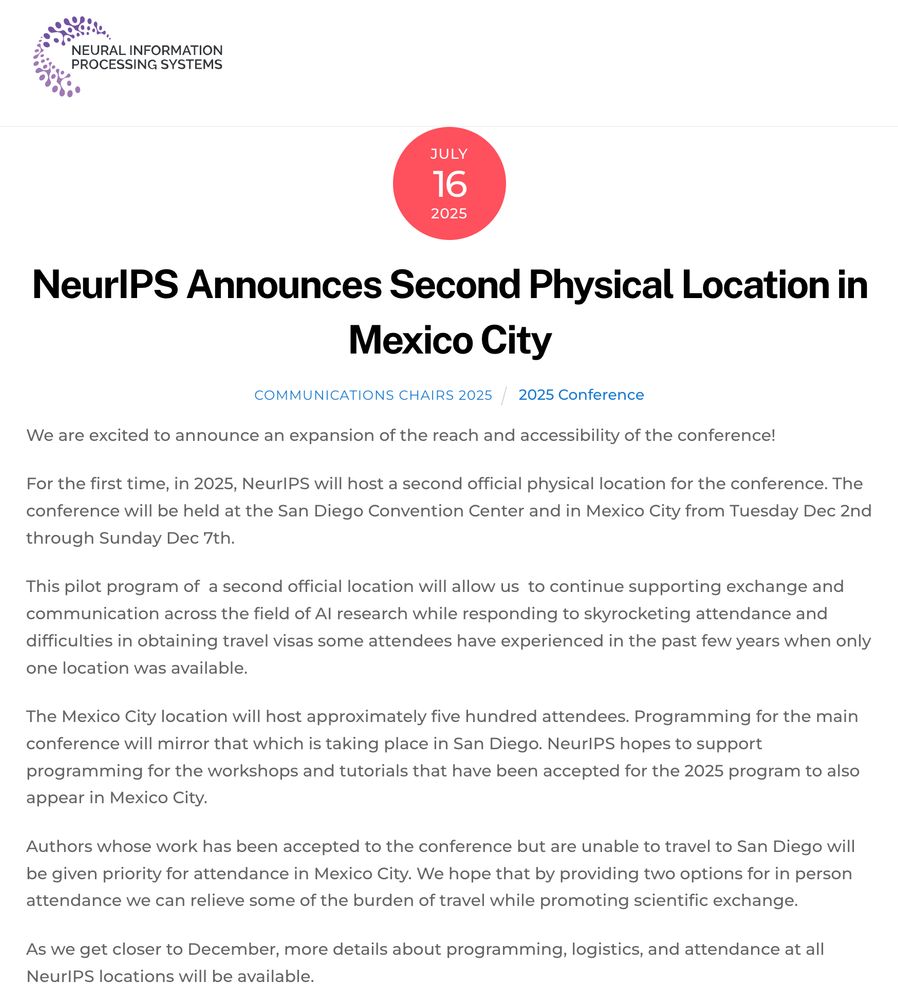
July 16, 2025 at 11:53 PM
It is a major policy failure that the US cannot accommodate top AI conferences due to visa issues.
buff.ly/DRJOGrB
buff.ly/DRJOGrB
bring back 8 page neurips papers
June 24, 2025 at 7:04 PM
bring back 8 page neurips papers
m̶e̶n̶ Americans will literally l̶e̶a̶r̶n̶ ̶e̶v̶e̶r̶y̶t̶h̶i̶n̶g̶ ̶a̶b̶o̶u̶t̶ ̶a̶n̶c̶i̶e̶n̶t̶ ̶R̶o̶m̶e̶ invest billions into self driving cars instead of g̶o̶i̶n̶g̶ ̶t̶o̶ ̶t̶h̶e̶r̶a̶p̶y̶ building transit
June 20, 2025 at 8:26 PM
m̶e̶n̶ Americans will literally l̶e̶a̶r̶n̶ ̶e̶v̶e̶r̶y̶t̶h̶i̶n̶g̶ ̶a̶b̶o̶u̶t̶ ̶a̶n̶c̶i̶e̶n̶t̶ ̶R̶o̶m̶e̶ invest billions into self driving cars instead of g̶o̶i̶n̶g̶ ̶t̶o̶ ̶t̶h̶e̶r̶a̶p̶y̶ building transit
bring back length limits for author responses
June 6, 2025 at 5:56 PM
bring back length limits for author responses
in llm-land, what is a tool, a function, an agent, and (most elusive of all): a "multi-agent system"? (This had been bothering me recently; are all these the same?)
@yoavgo.bsky.social's blog is a clarifying read on the topic -- I plan to adopt his terminology :-)
gist.github.com/yoavg/9142e5...
@yoavgo.bsky.social's blog is a clarifying read on the topic -- I plan to adopt his terminology :-)
gist.github.com/yoavg/9142e5...

What makes multi-agent LLM systems multi-agent?
What makes multi-agent LLM systems multi-agent? GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
June 4, 2025 at 10:07 PM
in llm-land, what is a tool, a function, an agent, and (most elusive of all): a "multi-agent system"? (This had been bothering me recently; are all these the same?)
@yoavgo.bsky.social's blog is a clarifying read on the topic -- I plan to adopt his terminology :-)
gist.github.com/yoavg/9142e5...
@yoavgo.bsky.social's blog is a clarifying read on the topic -- I plan to adopt his terminology :-)
gist.github.com/yoavg/9142e5...
If you're in WA and think imposing new taxes on things we want more of (e.g., bikes, transit) is a bad idea, consider contacting your reps using this simple form! <3

The Senate transportation budgets contain things we love ($450 million for safety on main street highways!) and others we strongly oppose, like new taxes on buses and e-bikes. Join us in asking legislators to say "no" to these taxes.
actionnetwork.org/letters/say-...
actionnetwork.org/letters/say-...

No Bus Tax, No Bike Tax!
Senate Bill 5801 proposes new fees on buses and a surcharge on electric bicycles to raise transportation revenue. Tell members of the House and Senate Transportation Committees to say "NO" to bus and ...
actionnetwork.org
March 27, 2025 at 6:35 PM
If you're in WA and think imposing new taxes on things we want more of (e.g., bikes, transit) is a bad idea, consider contacting your reps using this simple form! <3
Should you delete softmax from your attention layers? check out Songling Yang's (sustcsonglin.github.io) tutorial, moderated by @srushnlp.bsky.social, for a beginner-friendly tutorial of the why/how/beauty of linear attention :-) www.youtube.com/watch?v=d0HJ...
Songlin Yang
A simple, whitespace theme for academics. Based on [*folio](https://github.com/bogoli/-folio) design.
sustcsonglin.github.io
February 24, 2025 at 8:03 PM
Should you delete softmax from your attention layers? check out Songling Yang's (sustcsonglin.github.io) tutorial, moderated by @srushnlp.bsky.social, for a beginner-friendly tutorial of the why/how/beauty of linear attention :-) www.youtube.com/watch?v=d0HJ...
Reposted by Jack Hessel

I've spent the last two years trying to understand how LLMs might improve middle-school math education. I just published an article in the Journal of Educational Data Mining describing some of that work: "Designing Safe and Relevant Generative Chats for Math Learning in Intelligent Tutoring Systems"
Journal of Educational Data Mining
Large language models (LLMs) are flexible, personalizable, and available, which makes their use within Intelligent Tutoring Systems (ITSs) appealing. However, their flexibility creates risks: inaccura...
jedm.educationaldatamining.org
January 30, 2025 at 11:41 PM
I've spent the last two years trying to understand how LLMs might improve middle-school math education. I just published an article in the Journal of Educational Data Mining describing some of that work: "Designing Safe and Relevant Generative Chats for Math Learning in Intelligent Tutoring Systems"
Reposted by Jack Hessel

Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
How has DeepSeek improved the Transformer architecture?
This Gradient Updates issue goes over the major changes that went into DeepSeek’s most recent model.
epoch.ai
January 30, 2025 at 9:07 PM
Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
Reposted by Jack Hessel

I've posted the practice run of my LSA keynote. My core claim is that LLMs can be useful tools for doing close linguistic analysis. I illustrate with a detailed case study, drawing on corpus evidence, targeted syntactic evaluations, and causal intervention-based analyses: youtu.be/DBorepHuKDM
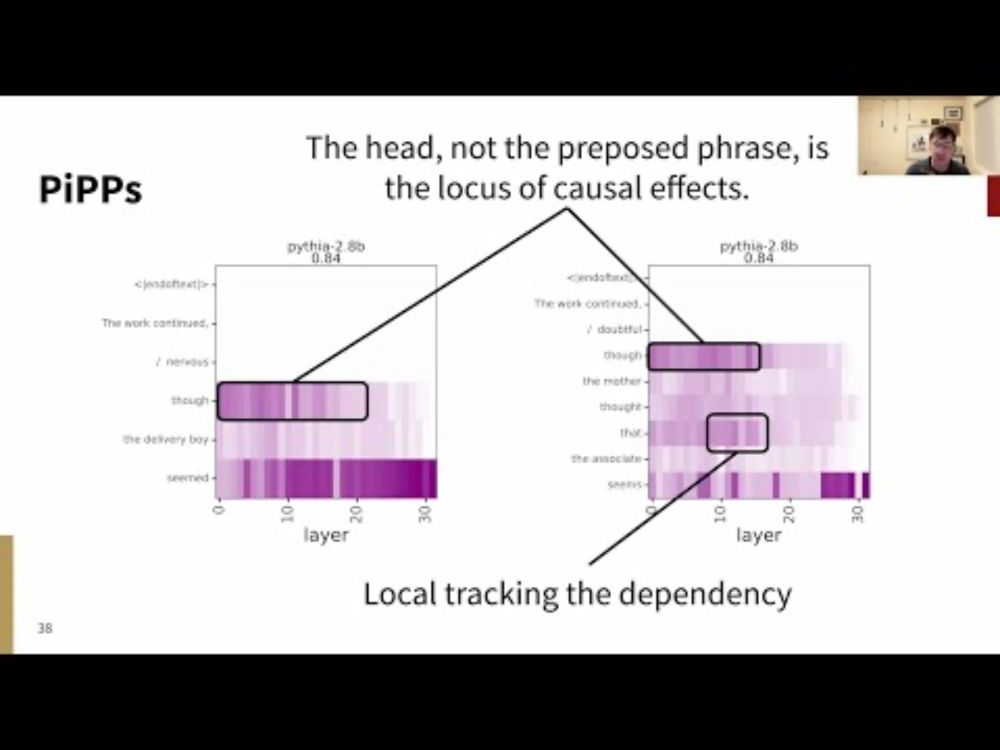
Finding linguistic structure in large language models
YouTube video by Chris Potts
youtu.be
January 13, 2025 at 2:41 AM
I've posted the practice run of my LSA keynote. My core claim is that LLMs can be useful tools for doing close linguistic analysis. I illustrate with a detailed case study, drawing on corpus evidence, targeted syntactic evaluations, and causal intervention-based analyses: youtu.be/DBorepHuKDM
Reposted by Jack Hessel

Here's my end-of-year review of things we learned out about LLMs in 2024 - we learned a LOT of things simonwillison.net/2024/Dec/31/...
Table of contents:
Table of contents:

December 31, 2024 at 6:10 PM
Here's my end-of-year review of things we learned out about LLMs in 2024 - we learned a LOT of things simonwillison.net/2024/Dec/31/...
Table of contents:
Table of contents:
Reposted by Jack Hessel

It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
So far the blog post draft is winning the distraction battle. Prepare for a very long and opinionated update about all the new tools and apps I’ve been using for work.
Flight prep for someone who hates flying:
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
December 31, 2024 at 5:38 AM
It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
Reposted by Jack Hessel

Sample and verify go brr

Six months ago someone put a for-loop around GPT-4o and got 50% on the ARC-AGI test set and 72% on a held-out training set redwoodresearch.substack.com/p/getting-50... Just sample 8000 times with beam search.
o3 is probably a more principled search technique...
o3 is probably a more principled search technique...
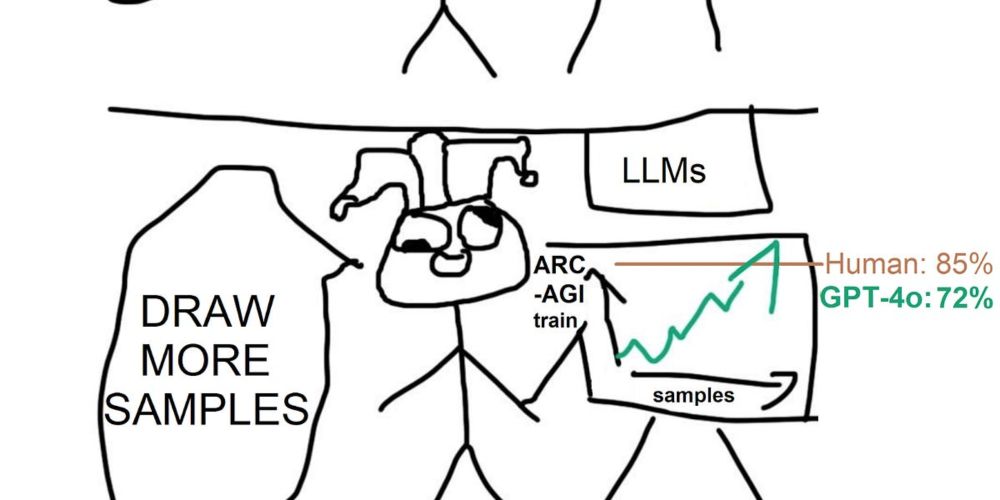
Getting 50% (SoTA) on ARC-AGI with GPT-4o
You can just draw more samples
redwoodresearch.substack.com
December 21, 2024 at 7:17 PM
Sample and verify go brr
Reposted by Jack Hessel

Check out our new encoder model, ModernBERT! 🤖
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
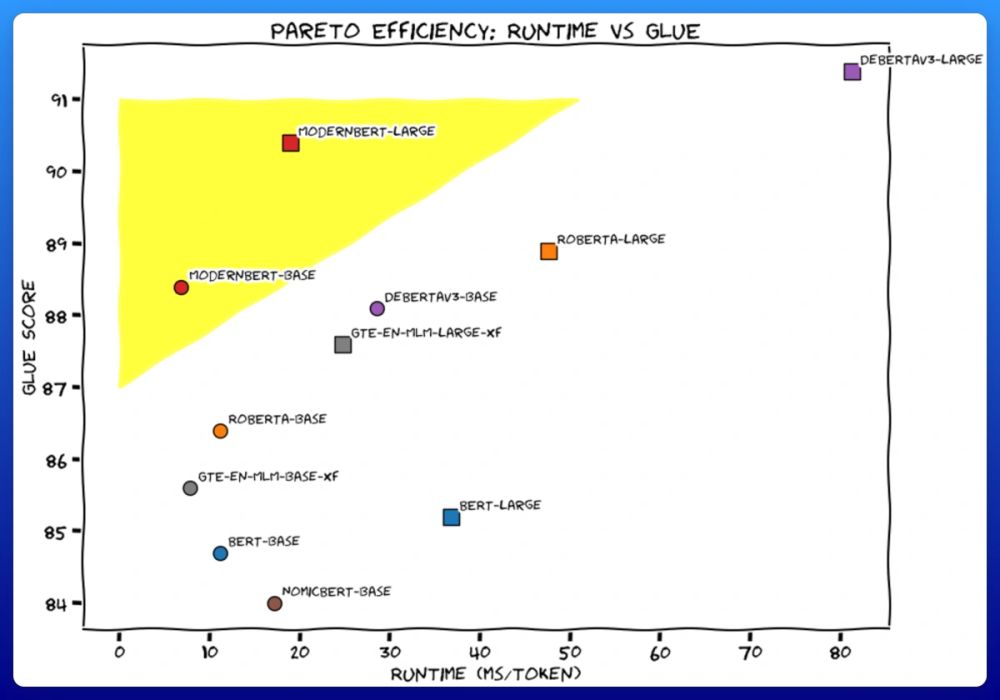
December 19, 2024 at 9:28 PM
Check out our new encoder model, ModernBERT! 🤖
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
Super grateful to have been part of such an awesome team effort and very excited about the gains for retrieval/RAG! 🚀
I'm not an """ AGI """ person or anything, but, I do think process reward model RL/scaling inference compute is quite promising for problems with easily verified solutions like (some) math/coding/ARC problems.
December 20, 2024 at 8:26 PM
I'm not an """ AGI """ person or anything, but, I do think process reward model RL/scaling inference compute is quite promising for problems with easily verified solutions like (some) math/coding/ARC problems.
Reposted by Jack Hessel

Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social


December 17, 2024 at 3:48 PM
Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi.com @eunsol.bsky.social @ranjaykrishna.bsky.social and @adtraghunathan.bsky.social
Meanwhile in my neighborhood in Seattle we've been fighting 5 years for (1) bus lane and 30 years for a (1) mile bike path

December 14, 2024 at 6:38 AM
Meanwhile in my neighborhood in Seattle we've been fighting 5 years for (1) bus lane and 30 years for a (1) mile bike path
excited to come to #neurips2024 workshops this weekend --- I'll be around sat/sun to say hi to folks :-)
December 13, 2024 at 1:52 AM
excited to come to #neurips2024 workshops this weekend --- I'll be around sat/sun to say hi to folks :-)
Reposted by Jack Hessel

🚨 I’m on the academic job market!
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵

December 7, 2024 at 10:32 PM
🚨 I’m on the academic job market!
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵
Reposted by Jack Hessel

“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
December 5, 2024 at 4:39 PM
“They said it could not be done”. We’re releasing Pleias 1.0, the first suite of models trained on open data (either permissibly licensed or uncopyrighted): Pleias-3b, Pleias-1b and Pleias-350m, all based on the two trillion tokens set from Common Corpus.
Reposted by Jack Hessel



Blue skies 🦋 , hot (?) takes 🔥
Constrained output for LLMs, e.g., outlines library for vllm which forces models to output json/pydantic schemas, is cool!
But, because output tokens cost much more latency than input tokens, if speed matters: bespoke, low-token output formats are often better.
Constrained output for LLMs, e.g., outlines library for vllm which forces models to output json/pydantic schemas, is cool!
But, because output tokens cost much more latency than input tokens, if speed matters: bespoke, low-token output formats are often better.
December 3, 2024 at 10:25 PM
Blue skies 🦋 , hot (?) takes 🔥
Constrained output for LLMs, e.g., outlines library for vllm which forces models to output json/pydantic schemas, is cool!
But, because output tokens cost much more latency than input tokens, if speed matters: bespoke, low-token output formats are often better.
Constrained output for LLMs, e.g., outlines library for vllm which forces models to output json/pydantic schemas, is cool!
But, because output tokens cost much more latency than input tokens, if speed matters: bespoke, low-token output formats are often better.
Information retrieval systems usually operate as a model "cascade" -- fast vector search over billions of documents followed by a more expressive LLM "re-ranking" the resulting top-K.
But beware 👻 !
Despite expressivity, top-K re-rankers generalize poorly as K increases.
arxiv.org/pdf/2411.11767
But beware 👻 !
Despite expressivity, top-K re-rankers generalize poorly as K increases.
arxiv.org/pdf/2411.11767

November 27, 2024 at 9:59 PM
Information retrieval systems usually operate as a model "cascade" -- fast vector search over billions of documents followed by a more expressive LLM "re-ranking" the resulting top-K.
But beware 👻 !
Despite expressivity, top-K re-rankers generalize poorly as K increases.
arxiv.org/pdf/2411.11767
But beware 👻 !
Despite expressivity, top-K re-rankers generalize poorly as K increases.
arxiv.org/pdf/2411.11767