



@isidrolauscher.bsky.social
Kudos to Sonia Zumalave in my lab for working out how to flag and remove such fold-back-like artifacts, with key contributions from @hbelrick.bsky.social @carolinmsa.bsky.social and @jevalleinclan.bsky.social. Thread on our algorithm bsky.app/profile/isid... and ..
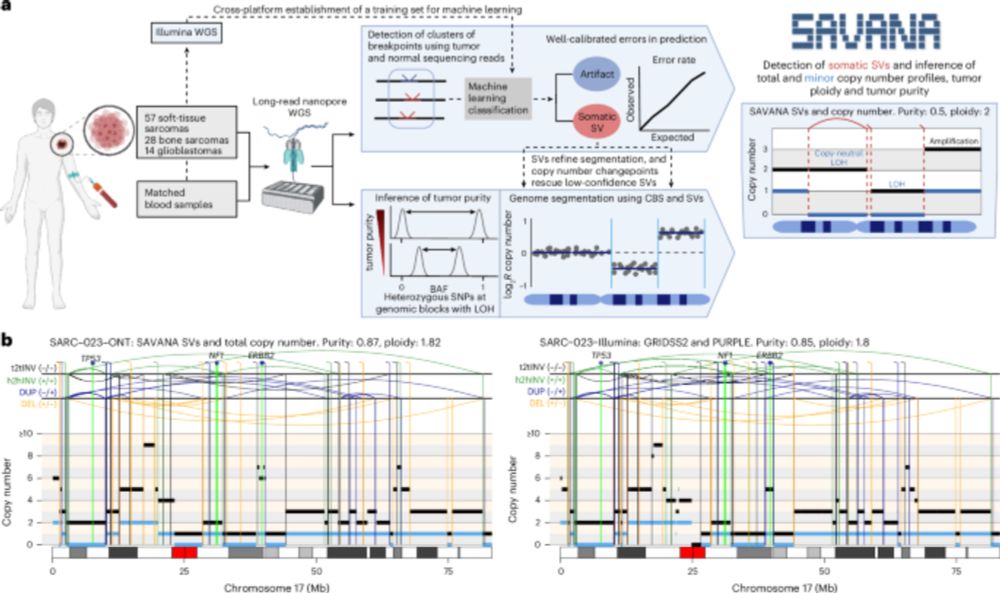
Thrilled to see #SAVANA out in @natmethods.nature.com 🥳 SAVANA detects haplotype-resolved somatic SVs, copy number aberrations & infers tumour purity & ploidy using long-read sequencing with or WITHOUT a matched germline control 👇https://www.nature.com/articles/s41592-025-02708-0
July 20, 2025 at 11:35 PM
Kudos to Sonia Zumalave in my lab for working out how to flag and remove such fold-back-like artifacts, with key contributions from @hbelrick.bsky.social @carolinmsa.bsky.social and @jevalleinclan.bsky.social. Thread on our algorithm bsky.app/profile/isid... and ..
Reposted

Work by researchers in the group of @isidrolauscher.bsky.social at EMBL-EBI, the R&D lab of @genomicsengland.bsky.social, in collaboration with clinical partners at @ucl.ac.uk, Royal National Orthopaedic Hospital, Instituto de Medicina Molecular João Lobo Antunes, and Boston Children’s Hospital.
May 29, 2025 at 8:57 AM
Work by researchers in the group of @isidrolauscher.bsky.social at EMBL-EBI, the R&D lab of @genomicsengland.bsky.social, in collaboration with clinical partners at @ucl.ac.uk, Royal National Orthopaedic Hospital, Instituto de Medicina Molecular João Lobo Antunes, and Boston Children’s Hospital.
Link to full text (open access) www.nature.com/articles/s41...
SAVANA: reliable analysis of somatic structural variants and copy number aberrations using long-read sequencing - Nature Methods
SAVANA is a tool to detect somatic structural variants and copy number aberrations using long-read sequencing data, offering high sensitivity, specificity and compatibility with or without germline co...
www.nature.com
May 28, 2025 at 8:47 PM
Link to full text (open access) www.nature.com/articles/s41...
and huge thanks to our funders 🙏 @curesarcoma.bsky.social CTOS, @embl.org and others!
May 28, 2025 at 5:36 PM
and huge thanks to our funders 🙏 @curesarcoma.bsky.social CTOS, @embl.org and others!
HT @jevalleinclan.bsky.social nclan.bsky.social, and other lab members at @ebi.embl.org bl.org, our great collaborators at @bostonchildrens.bsky.social s.bsky.social Melanie Tanguy and Greg Elgar @genomicsengland.bsky.social sengland.bsky.social IMM Lisbon...
Bluesky
s.bsky.social
May 28, 2025 at 5:36 PM
HT @jevalleinclan.bsky.social nclan.bsky.social, and other lab members at @ebi.embl.org bl.org, our great collaborators at @bostonchildrens.bsky.social s.bsky.social Melanie Tanguy and Greg Elgar @genomicsengland.bsky.social sengland.bsky.social IMM Lisbon...
SAVANA was developed by two superstars in the lab @hbelrick.bsky.social & Carolin Sauer in close collaboration once again with Prof. Flanagan and team at @ucl.ac.uk with key contributions from...
May 28, 2025 at 5:36 PM
SAVANA was developed by two superstars in the lab @hbelrick.bsky.social & Carolin Sauer in close collaboration once again with Prof. Flanagan and team at @ucl.ac.uk with key contributions from...
In sum, we establish best practices for benchmarking SV detection methods for somatic (eg cancer) genome analysis, and show that SAVANA enables the application of long-read sequencing to detect SVs and SCNAs reliably in clinical samples.
May 28, 2025 at 5:36 PM
In sum, we establish best practices for benchmarking SV detection methods for somatic (eg cancer) genome analysis, and show that SAVANA enables the application of long-read sequencing to detect SVs and SCNAs reliably in clinical samples.
Finally, SAVANA predictive modelling framework incorporates Conformal Prediction, a mathematically sound method to control the error rate of predictions (hence the ‘reliable’ in the title). Conformal prediction is a robust method we've used in other contexts as well eg pubs.acs.org/doi/10.1021/...
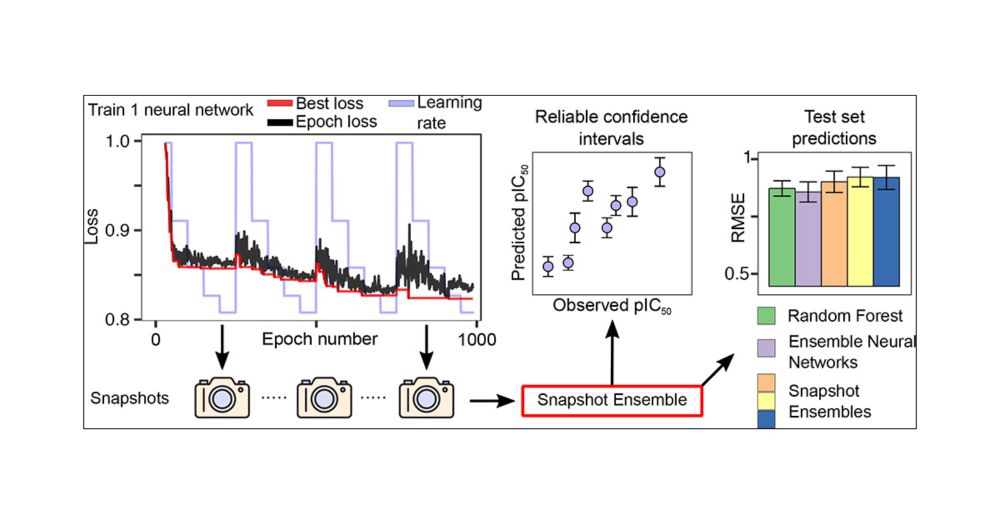
Deep Confidence: A Computationally Efficient Framework for Calculating Reliable Prediction Errors for Deep Neural Networks
Deep learning architectures have proved versatile in a number of drug discovery applications, including the modeling of in vitro compound activity. While controlling for prediction confidence is essen...
pubs.acs.org
May 28, 2025 at 5:36 PM
Finally, SAVANA predictive modelling framework incorporates Conformal Prediction, a mathematically sound method to control the error rate of predictions (hence the ‘reliable’ in the title). Conformal prediction is a robust method we've used in other contexts as well eg pubs.acs.org/doi/10.1021/...
Importantly, #SAVANA harnesses read-phasing information during model training & provides haplotype-resolved SV calls, facilitating the assembly of complex SVs at single-haplotype resolution, eg our work on LTA chromothripsis in osteosarcoma @cellpress.bsky.social
www.cell.com/cell/fulltex...
www.cell.com/cell/fulltex...
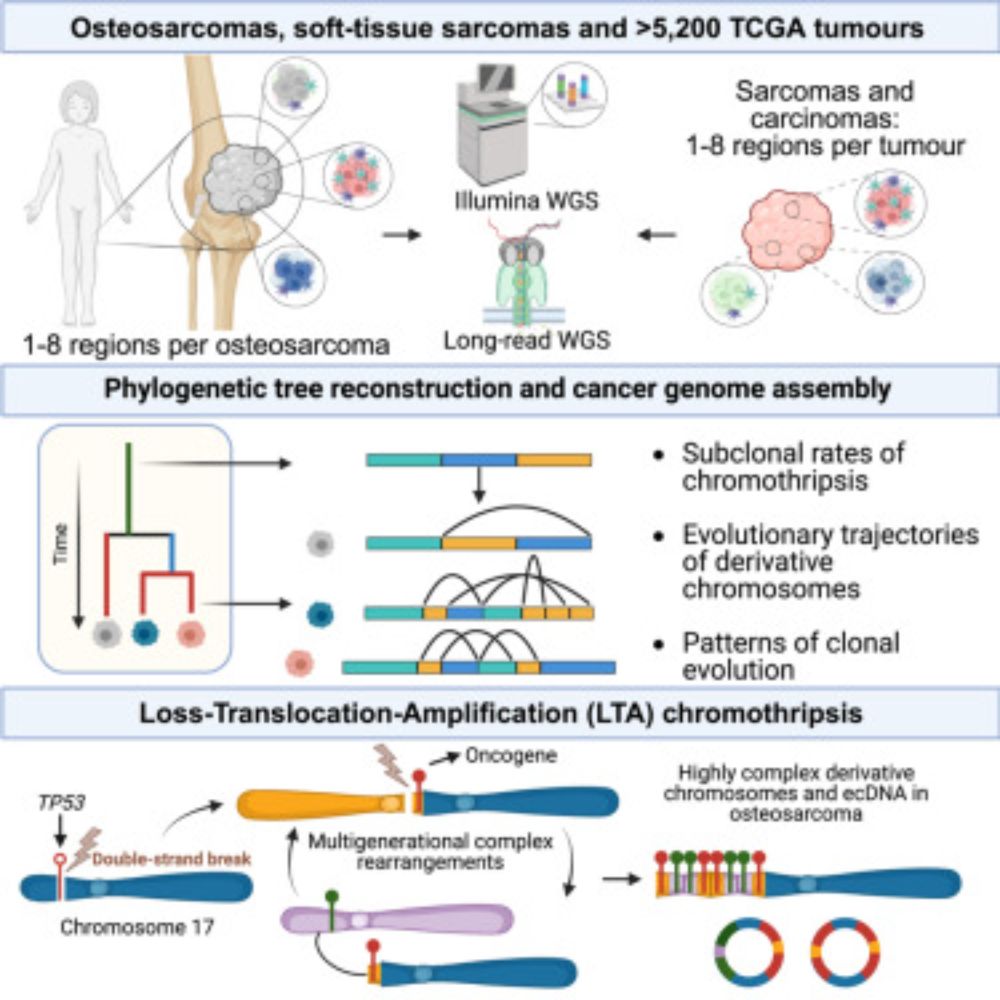
Ongoing chromothripsis underpins osteosarcoma genome complexity and clonal evolution
Ongoing chromothripsis shapes genomic evolution in a diverse range of sarcomas and
carcinomas. High-grade osteosarcoma is predominantly driven by the mechanism of loss-translocation-amplification
chro...
www.cell.com
May 28, 2025 at 5:36 PM
Importantly, #SAVANA harnesses read-phasing information during model training & provides haplotype-resolved SV calls, facilitating the assembly of complex SVs at single-haplotype resolution, eg our work on LTA chromothripsis in osteosarcoma @cellpress.bsky.social
www.cell.com/cell/fulltex...
www.cell.com/cell/fulltex...
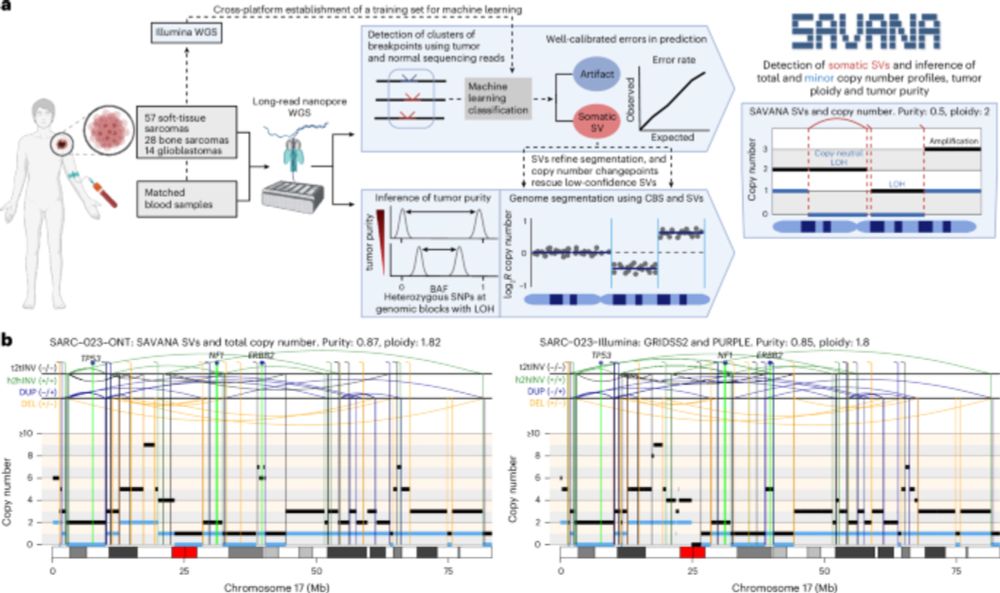
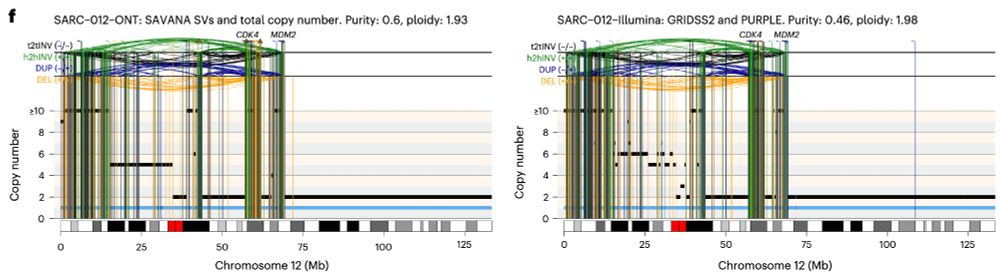
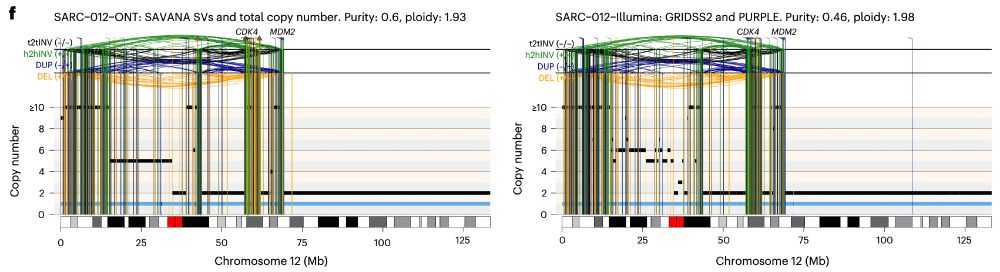
In practice, this means that we can now study, reliably, complex genomic rearrangements (e.g. #chromothripsis) and clinically relevant events causing tumour suppressor gene loss using long reads (left) with comparable accuracy to Illumina (right):
May 28, 2025 at 5:36 PM
In practice, this means that we can now study, reliably, complex genomic rearrangements (e.g. #chromothripsis) and clinically relevant events causing tumour suppressor gene loss using long reads (left) with comparable accuracy to Illumina (right):
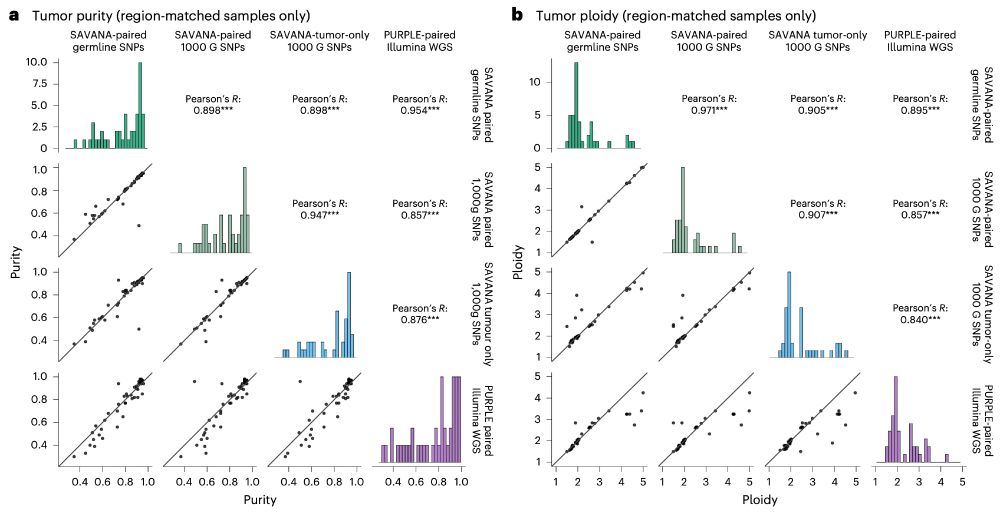
Moreover, using #SAVANA, we can estimate tumour purity and ploidy with comparable accuracy to illumina data (using the fantastic pipeline developed by the Hartwig Medical Foundation @ecuppen.bsky.social @danielisskeptical.bsky.social for clinical reports) even WITHOUT a germline control!
May 28, 2025 at 5:36 PM
Moreover, using #SAVANA, we can estimate tumour purity and ploidy with comparable accuracy to illumina data (using the fantastic pipeline developed by the Hartwig Medical Foundation @ecuppen.bsky.social @danielisskeptical.bsky.social for clinical reports) even WITHOUT a germline control!
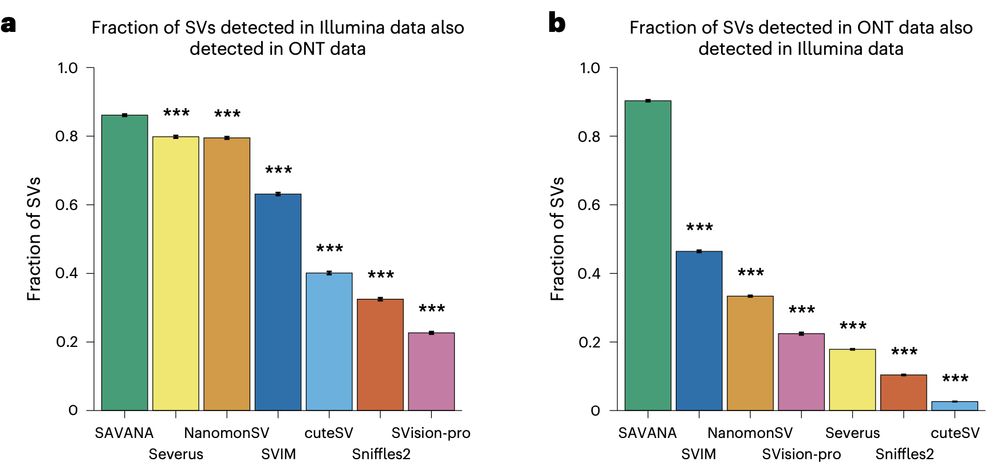
Using SAVANA, we recover most of the SVs detected in short-read data (note the higher than two-fold diff in coverage between long and short reads here!!), and most of the SVs detected using long reads are detected in illumina data (note that we are not using ultra-long reads)
May 28, 2025 at 5:36 PM
Using SAVANA, we recover most of the SVs detected in short-read data (note the higher than two-fold diff in coverage between long and short reads here!!), and most of the SVs detected using long reads are detected in illumina data (note that we are not using ultra-long reads)
Now that we have a robustly-validated algorithm we can address the question you are all waiting for (and which many colleagues have asked us many times): what is the relative performance of long & short reads to analyze human cancer genomes?
May 28, 2025 at 5:36 PM
Now that we have a robustly-validated algorithm we can address the question you are all waiting for (and which many colleagues have asked us many times): what is the relative performance of long & short reads to analyze human cancer genomes?
What underpins the higher performance of SAVANA? A key innovation of SAVANA is the use of machine learning to distinguish true somatic signal from artefacts. The key challenge here was to curate a large training set (see details in the paper).
May 28, 2025 at 5:36 PM
What underpins the higher performance of SAVANA? A key innovation of SAVANA is the use of machine learning to distinguish true somatic signal from artefacts. The key challenge here was to curate a large training set (see details in the paper).
In sum, these data indicate that SAVANA delivers SV results consistent with tumour biology, and the differences in SV rates across algorithms are caused by variable algorithmic performance, rather than true biological signal (see other analysis in support of this conclusion in the paper)
May 28, 2025 at 5:36 PM
In sum, these data indicate that SAVANA delivers SV results consistent with tumour biology, and the differences in SV rates across algorithms are caused by variable algorithmic performance, rather than true biological signal (see other analysis in support of this conclusion in the paper)
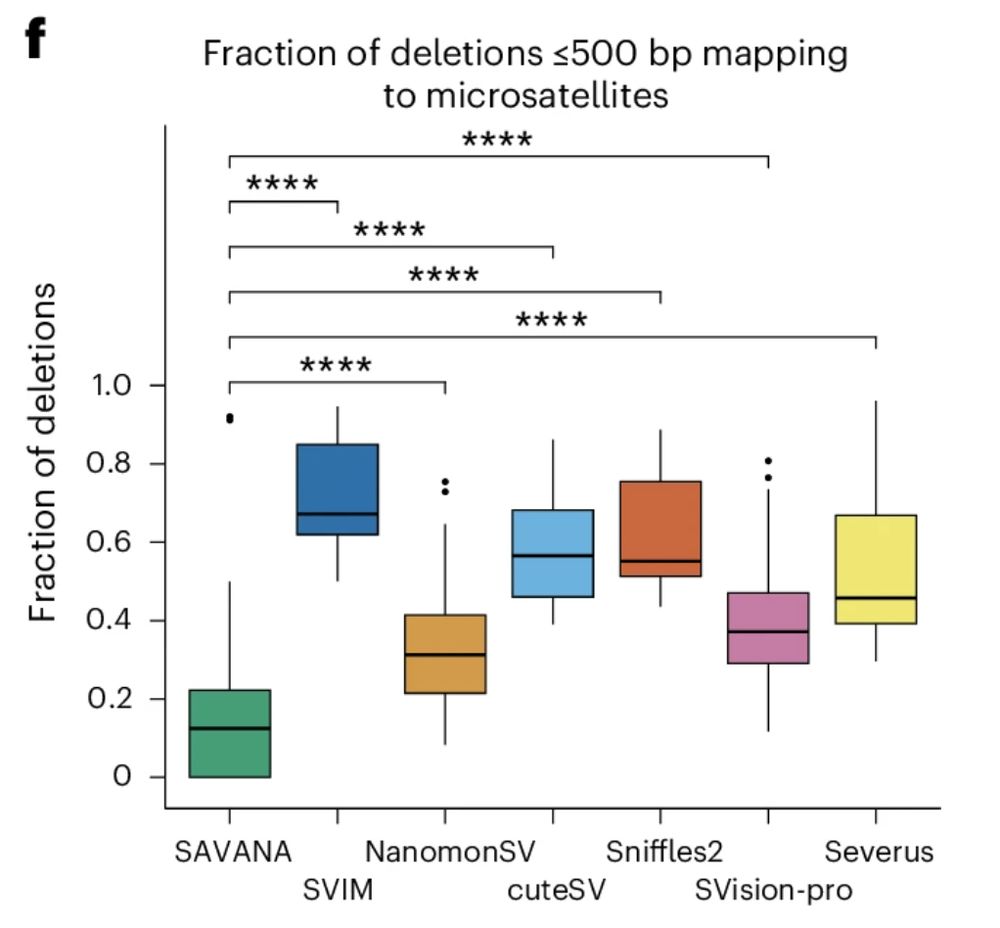
For example, existing methods detect 100s to 1000s of SVs in each sample mapping to microsatellite regions (#SAVANA doesn’t). The tumour types we analysed (sarcomas and glioblastomas) rarely show such levels of repeat instability, which we confirmed for our sample using illumina
May 28, 2025 at 5:36 PM
For example, existing methods detect 100s to 1000s of SVs in each sample mapping to microsatellite regions (#SAVANA doesn’t). The tumour types we analysed (sarcomas and glioblastomas) rarely show such levels of repeat instability, which we confirmed for our sample using illumina
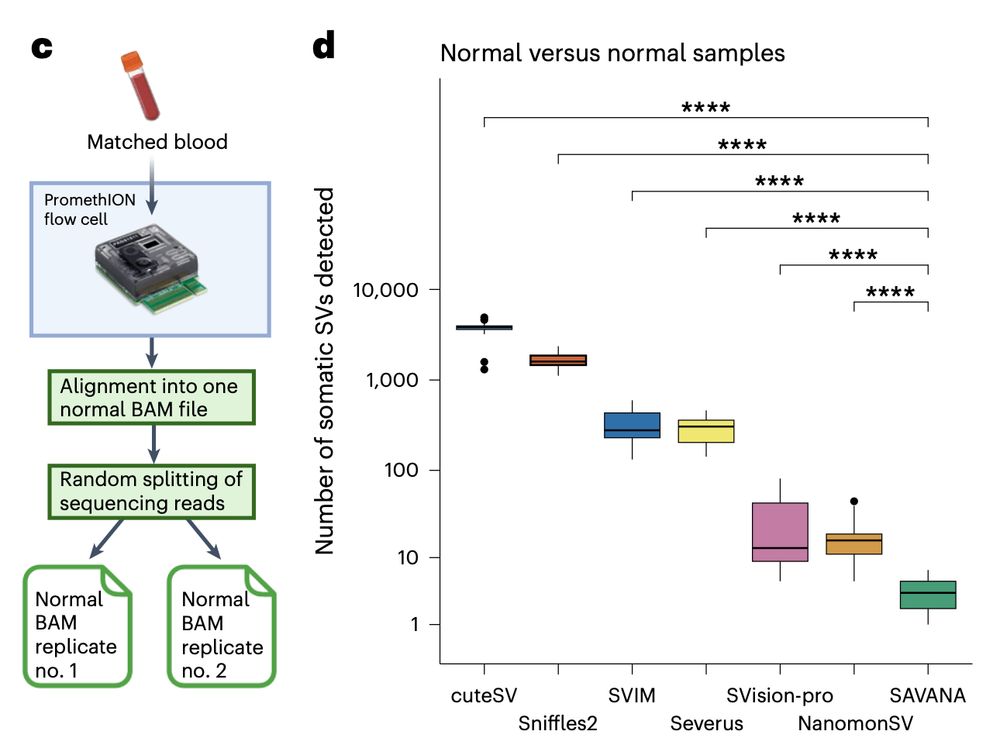
We found the same when using simulated sequencing replicates of the blood samples we use as germline controls. So, what are the false positive SVs called by some algorithms and not by others? What drives such strong differences in performance?
May 28, 2025 at 5:36 PM
We found the same when using simulated sequencing replicates of the blood samples we use as germline controls. So, what are the false positive SVs called by some algorithms and not by others? What drives such strong differences in performance?
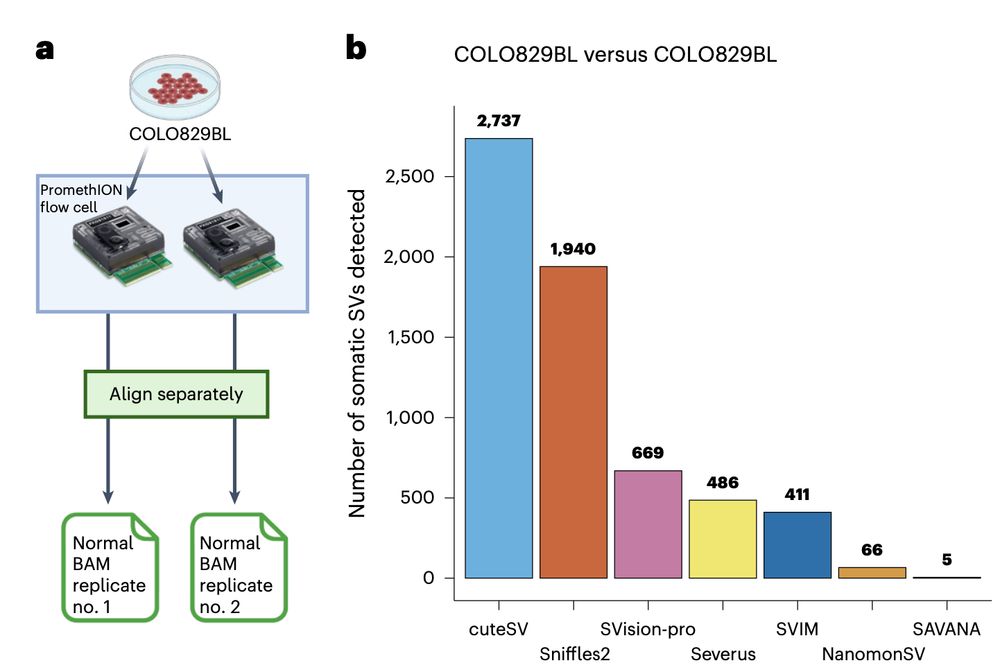
Using sequencing replicates of the normal cell line COLO829BL, we found that SAVANA shows 13- and 82-times higher specificity than the second and third-best performing algorithms (391x higher than the worse performing one). In practice, this means 10s-1000s less false positives..
May 28, 2025 at 5:36 PM
Using sequencing replicates of the normal cell line COLO829BL, we found that SAVANA shows 13- and 82-times higher specificity than the second and third-best performing algorithms (391x higher than the worse performing one). In practice, this means 10s-1000s less false positives..
Still not convinced? We also reasoned the following. If you use the same sample as both the tumour and matched germline sample to look for somatic SVs, how many would you detect? The answer is: 0, as you are comparing the same sample against itself. In other words: 1-1=0
May 28, 2025 at 5:36 PM
Still not convinced? We also reasoned the following. If you use the same sample as both the tumour and matched germline sample to look for somatic SVs, how many would you detect? The answer is: 0, as you are comparing the same sample against itself. In other words: 1-1=0
Well, nullius in verba, let the data speak. SAVANA shows uniform and much higher replication rates across SV clonality levels, sizes, types, samples and genomic regions. Thus, SAVANA's performance if driven by higher sensitivity and specificity!
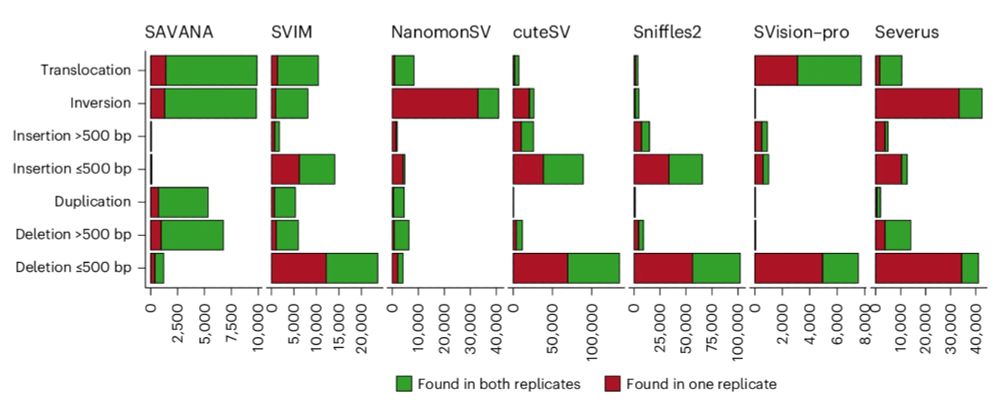
May 28, 2025 at 5:36 PM
Well, nullius in verba, let the data speak. SAVANA shows uniform and much higher replication rates across SV clonality levels, sizes, types, samples and genomic regions. Thus, SAVANA's performance if driven by higher sensitivity and specificity!