




Gordon Forbes
@gforb.bsky.social
I love Netflix for their data science blog and The BBC for their ggplot2 resources.
Reposted by Gordon Forbes

Hey #rstats,
What's your rule for splitting R scripts that form part of a wider analysis pipeline / project?
I usually write a single script which includes sections for each step from data cleaning to the final results, but it can become unwieldy when the script becomes long.
...
What's your rule for splitting R scripts that form part of a wider analysis pipeline / project?
I usually write a single script which includes sections for each step from data cleaning to the final results, but it can become unwieldy when the script becomes long.
...
July 1, 2025 at 9:57 PM
Hey #rstats,
What's your rule for splitting R scripts that form part of a wider analysis pipeline / project?
I usually write a single script which includes sections for each step from data cleaning to the final results, but it can become unwieldy when the script becomes long.
...
What's your rule for splitting R scripts that form part of a wider analysis pipeline / project?
I usually write a single script which includes sections for each step from data cleaning to the final results, but it can become unwieldy when the script becomes long.
...
Reposted by Gordon Forbes

New paper posted on Arxiv: "When do composite estimands answer non-causal questions?"
This can happen more often than you think, and can have a dramatic impact on trial results (e.g. a false-positive rate of almost 90%)
arxiv.org/abs/2506.22610 @timpmorris.bsky.social
This can happen more often than you think, and can have a dramatic impact on trial results (e.g. a false-positive rate of almost 90%)
arxiv.org/abs/2506.22610 @timpmorris.bsky.social

When do composite estimands answer non-causal questions?
Under a composite estimand strategy, the occurrence of the intercurrent event is incorporated into the endpoint definition, for instance by assigning a poor outcome value to patients who experience th...
arxiv.org
July 1, 2025 at 9:31 AM
New paper posted on Arxiv: "When do composite estimands answer non-causal questions?"
This can happen more often than you think, and can have a dramatic impact on trial results (e.g. a false-positive rate of almost 90%)
arxiv.org/abs/2506.22610 @timpmorris.bsky.social
This can happen more often than you think, and can have a dramatic impact on trial results (e.g. a false-positive rate of almost 90%)
arxiv.org/abs/2506.22610 @timpmorris.bsky.social
On tabular health data, time and time again, I see linear (or generalised linear models) perform as well or better than machine learning algorithms that avoid linearity assumptions.
I am surprised by this, as the linearity assumption is unlikely to be true.
Does anyone else see this? Why is this?
I am surprised by this, as the linearity assumption is unlikely to be true.
Does anyone else see this? Why is this?

May 22, 2025 at 9:10 AM
On tabular health data, time and time again, I see linear (or generalised linear models) perform as well or better than machine learning algorithms that avoid linearity assumptions.
I am surprised by this, as the linearity assumption is unlikely to be true.
Does anyone else see this? Why is this?
I am surprised by this, as the linearity assumption is unlikely to be true.
Does anyone else see this? Why is this?
Simpson's paradox


May 9, 2025 at 12:23 PM
Simpson's paradox
Reposted by Gordon Forbes

Georgi Baklicharov asks: can treatment effect testing in trials with intercurrent events be nearly assumption-free? #EuroCIM2025


April 9, 2025 at 1:21 PM
Georgi Baklicharov asks: can treatment effect testing in trials with intercurrent events be nearly assumption-free? #EuroCIM2025
Reposted by Gordon Forbes

I wrote a short post on the benefits I have found using DuckDB and duckplyr in my day to day workflow. rorylawless.github.io/posts/r-duck... #rstats #data #duckdb #databs
R, DuckDB and Me
Over the past year, DuckDB has gradually become an important part of my data science workflow - at first clumsily, then seamlessly. I don’t typically work with large datasets, however, integrating Duc...
rorylawless.github.io
March 31, 2025 at 12:21 AM
I wrote a short post on the benefits I have found using DuckDB and duckplyr in my day to day workflow. rorylawless.github.io/posts/r-duck... #rstats #data #duckdb #databs
Reposted by Gordon Forbes

Happy to see that ordered beta regression reached 100 citations on Google Scholar!
The model has citations from work in climate science, ecology, medicine, psychology, & political science, just to name a few.
Thanks to all of you for using ordbetareg (or glmmTMB)!!
#rstats
The model has citations from work in climate science, ecology, medicine, psychology, & political science, just to name a few.
Thanks to all of you for using ordbetareg (or glmmTMB)!!
#rstats

March 25, 2025 at 1:35 AM
Happy to see that ordered beta regression reached 100 citations on Google Scholar!
The model has citations from work in climate science, ecology, medicine, psychology, & political science, just to name a few.
Thanks to all of you for using ordbetareg (or glmmTMB)!!
#rstats
The model has citations from work in climate science, ecology, medicine, psychology, & political science, just to name a few.
Thanks to all of you for using ordbetareg (or glmmTMB)!!
#rstats
Reposted by Gordon Forbes
I'm working with data that I'm not allowed to share -- I'd like to generate synthetic data so that others at least have something that they can run my code on!
Any pointers to tutorials, favorite packages etc.?
Any pointers to tutorials, favorite packages etc.?

a man wearing a mask is playing a keyboard with the words love synths written above him
ALT: a man wearing a mask is playing a keyboard with the words love synths written above him
media.tenor.com
March 21, 2025 at 2:29 PM
I'm working with data that I'm not allowed to share -- I'd like to generate synthetic data so that others at least have something that they can run my code on!
Any pointers to tutorials, favorite packages etc.?
Any pointers to tutorials, favorite packages etc.?
Reposted by Gordon Forbes

Check out my new screencast, where I walk through how I use #Positron for #rstats package development work. I decided to release a new version of an R package to CRAN ✨live✨ this time around!
youtu.be/uL3NZQIMrpk
youtu.be/uL3NZQIMrpk
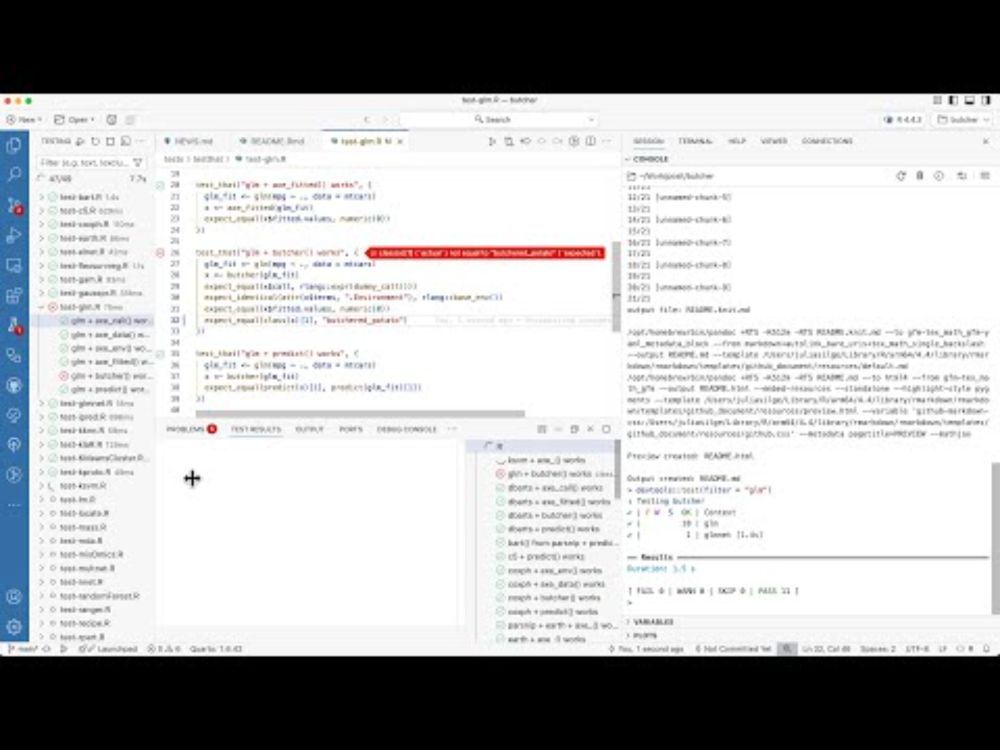
Release an R package with Positron
YouTube video by Julia Silge
youtu.be
March 19, 2025 at 3:36 PM
Check out my new screencast, where I walk through how I use #Positron for #rstats package development work. I decided to release a new version of an R package to CRAN ✨live✨ this time around!
youtu.be/uL3NZQIMrpk
youtu.be/uL3NZQIMrpk
Reposted by Gordon Forbes

In coursework, the contrast between ridge regression and the LASSO is really emphasized. After all, the latter actually does feature selection, by virtue of having a sparse solution to the minimum l1 problem, versus ridge's nonsparse solution in l2, pretty cool. 1/2
March 13, 2025 at 2:45 AM
In coursework, the contrast between ridge regression and the LASSO is really emphasized. After all, the latter actually does feature selection, by virtue of having a sparse solution to the minimum l1 problem, versus ridge's nonsparse solution in l2, pretty cool. 1/2
R packages for consort diagrams

Lots of Word Doc templates out there if you just search "consort diagram template".
Also, several R packages to help develop these.
www.riinu.me/2024/02/cons...
Also, several R packages to help develop these.
www.riinu.me/2024/02/cons...
March 12, 2025 at 4:40 PM
R packages for consort diagrams
Reposted by Gordon Forbes

We tried to look at ways to obtain flexible calibration plots in clustered (e.g. multicenter) validation studies.
Work with @lasaibarrenada.bsky.social @laurewynants.bsky.social @bavodccampo.bsky.social
arxiv.org/abs/2503.08389
Work with @lasaibarrenada.bsky.social @laurewynants.bsky.social @bavodccampo.bsky.social
arxiv.org/abs/2503.08389

Clustered Flexible Calibration Plots For Binary Outcomes Using Random Effects Modeling
Evaluation of clinical prediction models across multiple clusters, whether centers or datasets, is becoming increasingly common. A comprehensive evaluation includes an assessment of the agreement betw...
arxiv.org
March 12, 2025 at 8:43 AM
We tried to look at ways to obtain flexible calibration plots in clustered (e.g. multicenter) validation studies.
Work with @lasaibarrenada.bsky.social @laurewynants.bsky.social @bavodccampo.bsky.social
arxiv.org/abs/2503.08389
Work with @lasaibarrenada.bsky.social @laurewynants.bsky.social @bavodccampo.bsky.social
arxiv.org/abs/2503.08389
Reposted by Gordon Forbes
The term "digital twin" as it is now used in medicine has no real relationship to how the term is used in engineering. Yet every paper on the former talks about the success of the latter as if that's relevant. They are not the same!
March 12, 2025 at 9:44 AM
The term "digital twin" as it is now used in medicine has no real relationship to how the term is used in engineering. Yet every paper on the former talks about the success of the latter as if that's relevant. They are not the same!
My spell check is trying to change bootstrap to Boomer.
As in Boomer p-values.
I didn't know the generation wars had made it to statistical inference. What next? Millennial credible intervals?
As in Boomer p-values.
I didn't know the generation wars had made it to statistical inference. What next? Millennial credible intervals?
March 11, 2025 at 9:56 AM
My spell check is trying to change bootstrap to Boomer.
As in Boomer p-values.
I didn't know the generation wars had made it to statistical inference. What next? Millennial credible intervals?
As in Boomer p-values.
I didn't know the generation wars had made it to statistical inference. What next? Millennial credible intervals?
Reposted by Gordon Forbes
I think you mean "non-specific".

March 6, 2025 at 11:40 AM
I think you mean "non-specific".
It's amazing how far back ideas go.
This paper from 1984 by @f2harrell.bsky.social discusses the need for train/test data splits and the importance of assessing model calibration and discrimination and instability in variable selection methods.
onlinelibrary.wiley.com/doi/epdf/10....
This paper from 1984 by @f2harrell.bsky.social discusses the need for train/test data splits and the importance of assessing model calibration and discrimination and instability in variable selection methods.
onlinelibrary.wiley.com/doi/epdf/10....

Regression modelling strategies for improved prognostic prediction
Regression models such as the Cox proportional hazards model have had increasing use in modelling and estimating the prognosis of patients with a variety of diseases. Many applications involve a larg...
onlinelibrary.wiley.com
March 5, 2025 at 11:08 AM
It's amazing how far back ideas go.
This paper from 1984 by @f2harrell.bsky.social discusses the need for train/test data splits and the importance of assessing model calibration and discrimination and instability in variable selection methods.
onlinelibrary.wiley.com/doi/epdf/10....
This paper from 1984 by @f2harrell.bsky.social discusses the need for train/test data splits and the importance of assessing model calibration and discrimination and instability in variable selection methods.
onlinelibrary.wiley.com/doi/epdf/10....
Reposted by Gordon Forbes

A minor stylistic preference I’ve recently found myself using: When introducing a key initialism or acronym in a paper, put the compressed version in the text and its expansion in parentheses.
Instead of ‘under missing at random (MAR)’, use ‘under MAR (missing at random)’.
1/
Instead of ‘under missing at random (MAR)’, use ‘under MAR (missing at random)’.
1/
February 28, 2025 at 9:49 AM
A minor stylistic preference I’ve recently found myself using: When introducing a key initialism or acronym in a paper, put the compressed version in the text and its expansion in parentheses.
Instead of ‘under missing at random (MAR)’, use ‘under MAR (missing at random)’.
1/
Instead of ‘under missing at random (MAR)’, use ‘under MAR (missing at random)’.
1/
Reposted by Gordon Forbes

What advice do folks have for organising projects that will be deployed to production? How do you organise your directories? What do you do if you're deploying multiple "things" (e.g. an app and an api) from the same project?
February 27, 2025 at 2:15 PM
What advice do folks have for organising projects that will be deployed to production? How do you organise your directories? What do you do if you're deploying multiple "things" (e.g. an app and an api) from the same project?
Reposted by Gordon Forbes

Just published a couple of pre-prints for those interested in sample size calculations for precise and fair individual-level predictions ... (not the end of the story, but a useful contribution we hope):
Binary outcomes: arxiv.org/abs/2407.09293
Survival outcomes: arxiv.org/abs/2501.14482
Binary outcomes: arxiv.org/abs/2407.09293
Survival outcomes: arxiv.org/abs/2501.14482

A decomposition of Fisher's information to inform sample size for developing fair and precise clinical prediction models -- part 1: binary outcomes
When developing a clinical prediction model, the sample size of the development dataset is a key consideration. Small sample sizes lead to greater concerns of overfitting, instability, poor performanc...
arxiv.org
February 12, 2025 at 4:15 PM
Just published a couple of pre-prints for those interested in sample size calculations for precise and fair individual-level predictions ... (not the end of the story, but a useful contribution we hope):
Binary outcomes: arxiv.org/abs/2407.09293
Survival outcomes: arxiv.org/abs/2501.14482
Binary outcomes: arxiv.org/abs/2407.09293
Survival outcomes: arxiv.org/abs/2501.14482
Reposted by Gordon Forbes

Am looking for a particular article that argued that results of "explanatory" trials might generally be more timeless than those of pragmatic trials, since the latter might be reliant on a particular context at a given moment in time. Can't remember who this was by - something from imp science lit?
February 4, 2025 at 8:39 AM
Am looking for a particular article that argued that results of "explanatory" trials might generally be more timeless than those of pragmatic trials, since the latter might be reliant on a particular context at a given moment in time. Can't remember who this was by - something from imp science lit?
Reposted by Gordon Forbes

'Estimating hypothetical estimands with causal inference and missing data estimators in a diabetes trial case study', led by Camila Olarte Parra, with Rhian Daniel and David Wright, now available open access in Biometrics: doi.org/10.1093/biom...

Estimating hypothetical estimands with causal inference and missing data estimators in a diabetes trial case study
ABSTRACT. The ICH E9 addendum on estimands in clinical trials provides a framework for precisely defining the treatment effect that is to be estimated, but
doi.org
January 29, 2025 at 12:41 PM
'Estimating hypothetical estimands with causal inference and missing data estimators in a diabetes trial case study', led by Camila Olarte Parra, with Rhian Daniel and David Wright, now available open access in Biometrics: doi.org/10.1093/biom...
Reposted by Gordon Forbes

#statstab #267 That’s a Lot to Process! Pitfalls of Popular Path Models
Thoughts: The number of senior psych researchers that just loooove Process...and all use it post hoc 😩 Causal inference is not easy.
#mediation #process #spss #causalinference #SEM
journals.sagepub.com/doi/10.1177/...
Thoughts: The number of senior psych researchers that just loooove Process...and all use it post hoc 😩 Causal inference is not easy.
#mediation #process #spss #causalinference #SEM
journals.sagepub.com/doi/10.1177/...

That’s a Lot to Process! Pitfalls of Popular Path Models - Julia M. Rohrer, Paul Hünermund, Ruben C. Arslan, Malte Elson, 2022
Path models to test claims about mediation and moderation are a staple of psychology. But applied researchers may sometimes not understand the underlying causal...
journals.sagepub.com
January 28, 2025 at 6:36 PM
#statstab #267 That’s a Lot to Process! Pitfalls of Popular Path Models
Thoughts: The number of senior psych researchers that just loooove Process...and all use it post hoc 😩 Causal inference is not easy.
#mediation #process #spss #causalinference #SEM
journals.sagepub.com/doi/10.1177/...
Thoughts: The number of senior psych researchers that just loooove Process...and all use it post hoc 😩 Causal inference is not easy.
#mediation #process #spss #causalinference #SEM
journals.sagepub.com/doi/10.1177/...
"Many widely used models amount to an elaborate means of making up numbers—but once a number has been produced, it tends to be taken seriously and its source (the model) is rarely examined carefully."
Ouch.
doi.org/10.1007/s000...
Ouch.
doi.org/10.1007/s000...

Pay No Attention to the Model Behind the Curtain - Pure and Applied Geophysics
Many widely used models amount to an elaborate means of making up numbers—but once a number has been produced, it tends to be taken seriously and its source (the model) is rarely examined carefully. M...
doi.org
January 10, 2025 at 10:42 AM
"Many widely used models amount to an elaborate means of making up numbers—but once a number has been produced, it tends to be taken seriously and its source (the model) is rarely examined carefully."
Ouch.
doi.org/10.1007/s000...
Ouch.
doi.org/10.1007/s000...
This is really good.
December 19, 2024 at 11:01 AM
This is really good.