



Gabriel Martín Blázquez
@gabrielmb.com
ML Engineer @hf.co 🤗 Building tools for you to take care of your datasets like Argilla or distilabel!
SmolLM2 paper is out! We wrote a paper detailing the steps we took to train one of the best smol LM 🤏 out there: pre-training and post-training data, training ablations and some interesting findings 💡
Go check it out and don't hesitate to write your thoughts/questions in the comments section!
Go check it out and don't hesitate to write your thoughts/questions in the comments section!

February 6, 2025 at 10:56 AM
SmolLM2 paper is out! We wrote a paper detailing the steps we took to train one of the best smol LM 🤏 out there: pre-training and post-training data, training ablations and some interesting findings 💡
Go check it out and don't hesitate to write your thoughts/questions in the comments section!
Go check it out and don't hesitate to write your thoughts/questions in the comments section!
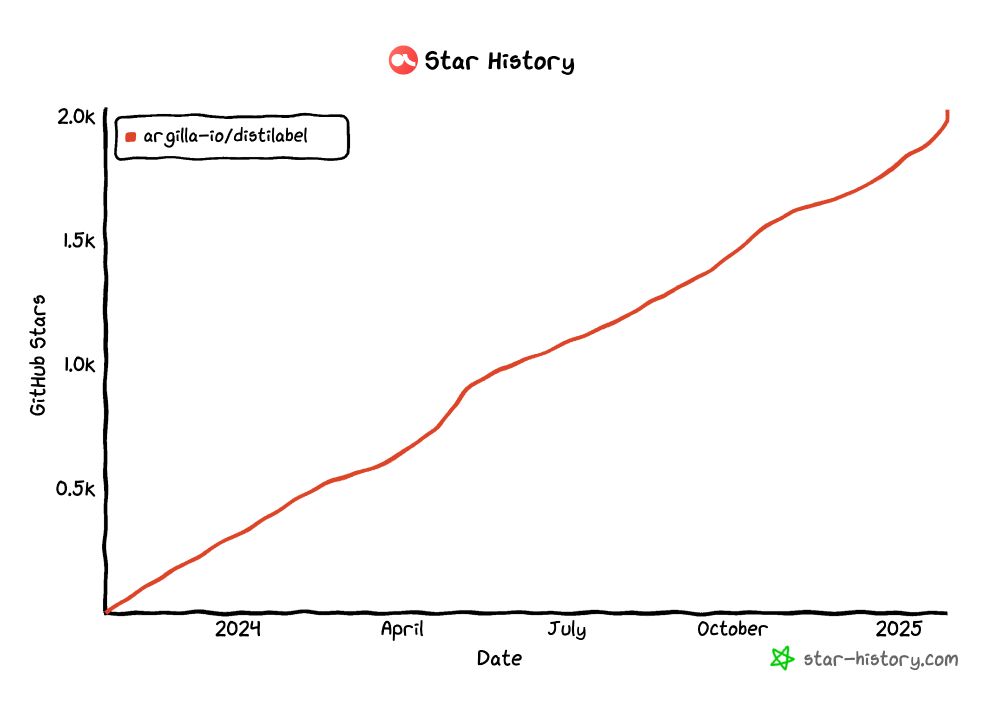
distilabel ⚗️ reached the 2k ⭐️ on GitHub!
January 27, 2025 at 3:58 PM
distilabel ⚗️ reached the 2k ⭐️ on GitHub!
Reposted by Gabriel Martín Blázquez

We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...

GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
January 25, 2025 at 1:29 PM
We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...
Reposted by Gabriel Martín Blázquez

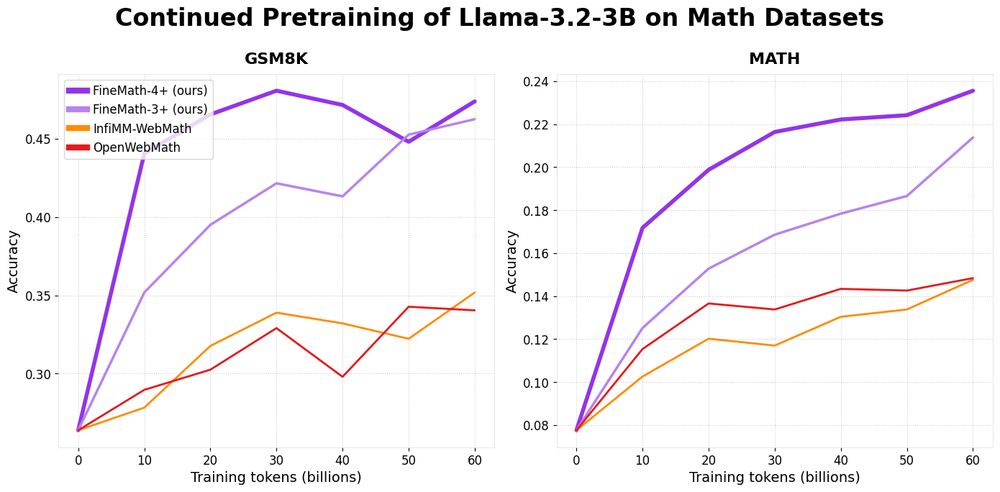
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
December 19, 2024 at 3:55 PM
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Reposted by Gabriel Martín Blázquez

🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
December 19, 2024 at 12:39 PM
🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
How many regular expressions have you written without the help of an LLM since ChatGPT appeared?
December 13, 2024 at 10:00 AM
How many regular expressions have you written without the help of an LLM since ChatGPT appeared?
Reposted by Gabriel Martín Blázquez

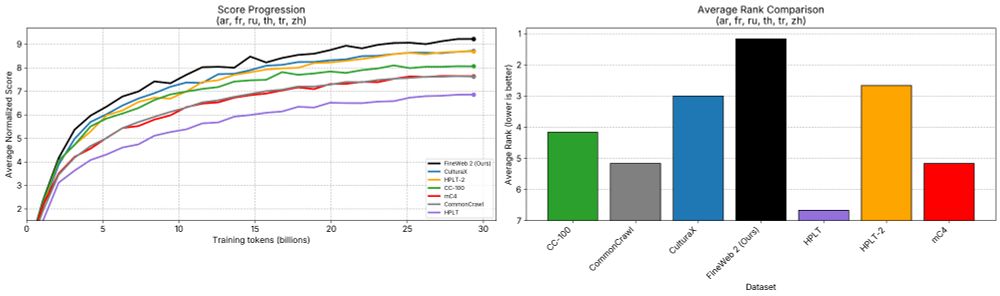
The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
December 8, 2024 at 9:08 AM
The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
Reposted by Gabriel Martín Blázquez

For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
December 3, 2024 at 9:21 AM
For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
It's just me or the latest Claude 3.5 Sonnet is too prone to generate code when asking technical questions not directly related to coding?
November 27, 2024 at 9:24 AM
It's just me or the latest Claude 3.5 Sonnet is too prone to generate code when asking technical questions not directly related to coding?
Reposted by Gabriel Martín Blázquez

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
As part of the SmolTalk release, the dataset mixture used for @huggingface.bsky.social SmolLM2 model, we built a new version of the MagPie Ultra dataset using Llama 405B Instruct.
It contains 1M rows of multi-turn conversations with diverse instructions!
huggingface.co/datasets/arg...
It contains 1M rows of multi-turn conversations with diverse instructions!
huggingface.co/datasets/arg...

argilla/magpie-ultra-v1.0 · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 26, 2024 at 3:22 PM
As part of the SmolTalk release, the dataset mixture used for @huggingface.bsky.social SmolLM2 model, we built a new version of the MagPie Ultra dataset using Llama 405B Instruct.
It contains 1M rows of multi-turn conversations with diverse instructions!
huggingface.co/datasets/arg...
It contains 1M rows of multi-turn conversations with diverse instructions!
huggingface.co/datasets/arg...
Reposted by Gabriel Martín Blázquez

Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
November 26, 2024 at 6:29 AM
Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
Reposted by Gabriel Martín Blázquez
I am very excited to launch a new community initiative next week.
Let's build the largest open community dataset to evaluate and improve image generation models.
Follow:
huggingface.co/data-is-bett...
And stay tuned here
Let's build the largest open community dataset to evaluate and improve image generation models.
Follow:
huggingface.co/data-is-bett...
And stay tuned here

data-is-better-together (Data Is Better Together)
Building better datasets together
huggingface.co
November 24, 2024 at 5:51 PM
I am very excited to launch a new community initiative next week.
Let's build the largest open community dataset to evaluate and improve image generation models.
Follow:
huggingface.co/data-is-bett...
And stay tuned here
Let's build the largest open community dataset to evaluate and improve image generation models.
Follow:
huggingface.co/data-is-bett...
And stay tuned here
Reposted by Gabriel Martín Blázquez

Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
Everything about the SmolLM & SmolLM2 family of models - GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
github.com
November 24, 2024 at 7:16 AM
Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...

HuggingFaceTB/smoltalk · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 21, 2024 at 3:22 PM
Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
Reposted by Gabriel Martín Blázquez
Here's a notebook where I do SFT SmolLM2 on the synthetic dataset: colab.research.google.com/drive/1lioed...
thanks @philschmid.bsky.social for the finetuning code
thanks @huggingface.bsky.social for the smol model
thanks @qgallouedec.bsky.social and friends for TRL
thanks @philschmid.bsky.social for the finetuning code
thanks @huggingface.bsky.social for the smol model
thanks @qgallouedec.bsky.social and friends for TRL

Google Colab
colab.research.google.com
November 21, 2024 at 10:34 AM
Here's a notebook where I do SFT SmolLM2 on the synthetic dataset: colab.research.google.com/drive/1lioed...
thanks @philschmid.bsky.social for the finetuning code
thanks @huggingface.bsky.social for the smol model
thanks @qgallouedec.bsky.social and friends for TRL
thanks @philschmid.bsky.social for the finetuning code
thanks @huggingface.bsky.social for the smol model
thanks @qgallouedec.bsky.social and friends for TRL
The great exile!
For those who don’t know me, I’m Gabriel, ML Engineer at @huggingface.bsky.social where I work developing tools like distilabel or Argilla for you to take care of your data 🤗
The content of my posts here will be mainly related to synthetic data and LLM post-training.
For those who don’t know me, I’m Gabriel, ML Engineer at @huggingface.bsky.social where I work developing tools like distilabel or Argilla for you to take care of your data 🤗
The content of my posts here will be mainly related to synthetic data and LLM post-training.
November 20, 2024 at 7:29 AM
The great exile!
For those who don’t know me, I’m Gabriel, ML Engineer at @huggingface.bsky.social where I work developing tools like distilabel or Argilla for you to take care of your data 🤗
The content of my posts here will be mainly related to synthetic data and LLM post-training.
For those who don’t know me, I’m Gabriel, ML Engineer at @huggingface.bsky.social where I work developing tools like distilabel or Argilla for you to take care of your data 🤗
The content of my posts here will be mainly related to synthetic data and LLM post-training.