




Jiri Fajtl
@fajtl.com
Research Scientist @Kingston University London | Computer Vision | Continual Learning | Scene Understanding | Multimodal Models | Open-Ended Learning
Reposted by Jiri Fajtl

Can LLMs reason by analogy like humans? We investigate this question in a new paper published in the Journal of Memory and Language (link below). This was a long-running but very rewarding project. Here are a few thoughts on our methodology and main findings. 1/9

August 11, 2025 at 8:02 AM
Can LLMs reason by analogy like humans? We investigate this question in a new paper published in the Journal of Memory and Language (link below). This was a long-running but very rewarding project. Here are a few thoughts on our methodology and main findings. 1/9
Reposted by Jiri Fajtl

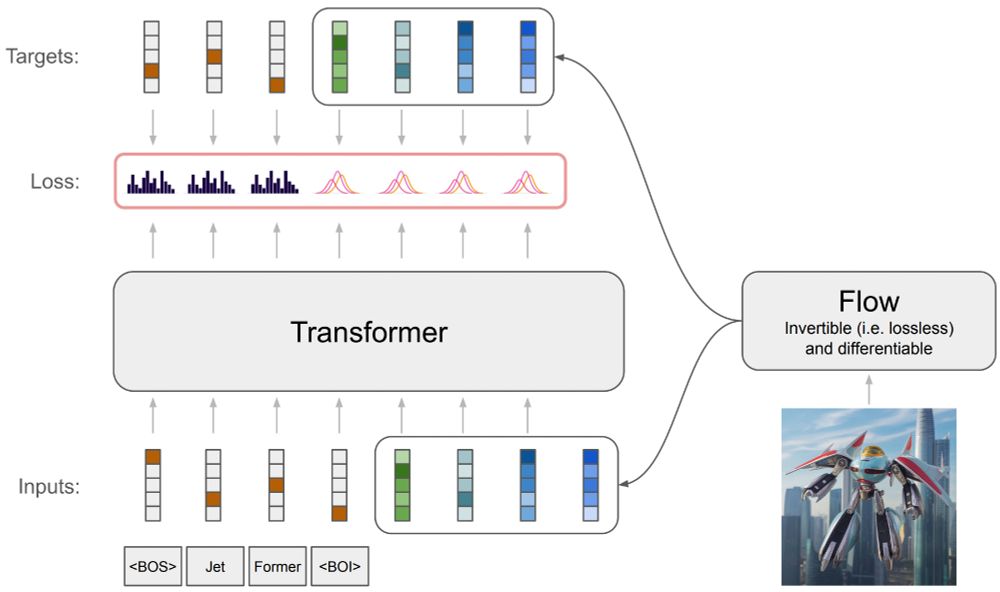
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Reposted by Jiri Fajtl

We just released RUKA, a $1300 humanoid hand that is 3D-printable, strong, precise, and fully open sourced!
The key technical breakthrough here is that we can control joints and fingertips of the robot **without joint encoders**. All we need here is self-supervised data collection and learning.
The key technical breakthrough here is that we can control joints and fingertips of the robot **without joint encoders**. All we need here is self-supervised data collection and learning.
April 18, 2025 at 6:53 PM
We just released RUKA, a $1300 humanoid hand that is 3D-printable, strong, precise, and fully open sourced!
The key technical breakthrough here is that we can control joints and fingertips of the robot **without joint encoders**. All we need here is self-supervised data collection and learning.
The key technical breakthrough here is that we can control joints and fingertips of the robot **without joint encoders**. All we need here is self-supervised data collection and learning.
Reposted by Jiri Fajtl

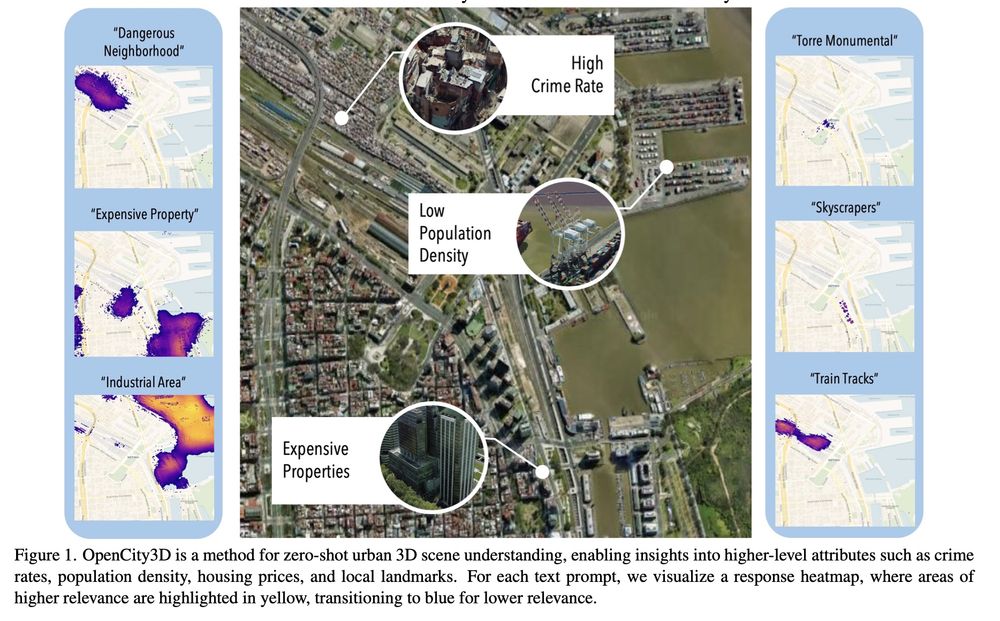
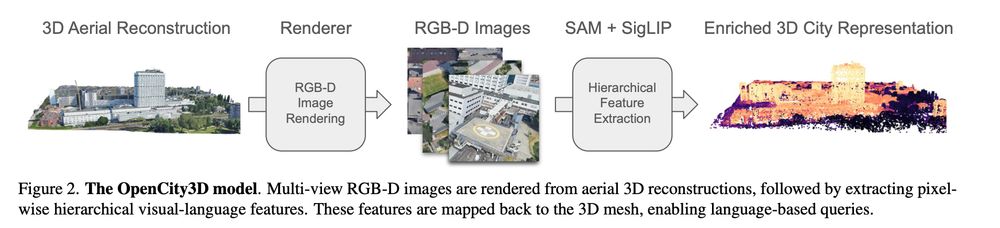
OpenCity3D: What do Vision-Language Models know about Urban Environments?
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
March 24, 2025 at 10:21 AM
OpenCity3D: What do Vision-Language Models know about Urban Environments?
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Reposted by Jiri Fajtl


Reposted by Jiri Fajtl

President Zelenskyy has been one of the greatest leaders of our time, guiding Ukraine through the darkest period of its recent history, rising up to Russia’s unwarranted aggression, being an inspiration to the Ukrainian people and ensuring that Ukraine’s voice is heard on the world stage.
February 20, 2025 at 12:14 AM
President Zelenskyy has been one of the greatest leaders of our time, guiding Ukraine through the darkest period of its recent history, rising up to Russia’s unwarranted aggression, being an inspiration to the Ukrainian people and ensuring that Ukraine’s voice is heard on the world stage.
Reposted by Jiri Fajtl

MoM: Linear Sequence Modeling with Mixture-of-Memories
By Du et al.
arxiv.org/abs/2502.13685
TLDR: combine multiple RNNs with a routing/gating network.
Evaluated on language tasks. Seems to outperform transformers? Would have loved to see comparisons with SSMs and xLSTM.
By Du et al.
arxiv.org/abs/2502.13685
TLDR: combine multiple RNNs with a routing/gating network.
Evaluated on language tasks. Seems to outperform transformers? Would have loved to see comparisons with SSMs and xLSTM.


February 20, 2025 at 7:10 AM
MoM: Linear Sequence Modeling with Mixture-of-Memories
By Du et al.
arxiv.org/abs/2502.13685
TLDR: combine multiple RNNs with a routing/gating network.
Evaluated on language tasks. Seems to outperform transformers? Would have loved to see comparisons with SSMs and xLSTM.
By Du et al.
arxiv.org/abs/2502.13685
TLDR: combine multiple RNNs with a routing/gating network.
Evaluated on language tasks. Seems to outperform transformers? Would have loved to see comparisons with SSMs and xLSTM.
Reposted by Jiri Fajtl

pySLAM: An Open-Source, Modular, and Extensible Framework for SLAM
Luigi Freda
tl;dr: python implementation of a Visual SLAM pipeline, support monocular, stereo and RGBD cameras
github.com/luigifreda/p...
arxiv.org/abs/2502.11955
Luigi Freda
tl;dr: python implementation of a Visual SLAM pipeline, support monocular, stereo and RGBD cameras
github.com/luigifreda/p...
arxiv.org/abs/2502.11955



February 20, 2025 at 9:03 AM
pySLAM: An Open-Source, Modular, and Extensible Framework for SLAM
Luigi Freda
tl;dr: python implementation of a Visual SLAM pipeline, support monocular, stereo and RGBD cameras
github.com/luigifreda/p...
arxiv.org/abs/2502.11955
Luigi Freda
tl;dr: python implementation of a Visual SLAM pipeline, support monocular, stereo and RGBD cameras
github.com/luigifreda/p...
arxiv.org/abs/2502.11955
Reposted by Jiri Fajtl
GS-GVINS: A Tightly-integrated GNSS-Visual-Inertial Navigation System Augmented by 3D Gaussian Splatting
Zelin Zhou, Saurav Uprety, Shichuang Nie, Hongzhou Yang
tl;dr: GICI-LIB+3DGS
arxiv.org/abs/2502.10975
Zelin Zhou, Saurav Uprety, Shichuang Nie, Hongzhou Yang
tl;dr: GICI-LIB+3DGS
arxiv.org/abs/2502.10975




February 20, 2025 at 8:59 AM
GS-GVINS: A Tightly-integrated GNSS-Visual-Inertial Navigation System Augmented by 3D Gaussian Splatting
Zelin Zhou, Saurav Uprety, Shichuang Nie, Hongzhou Yang
tl;dr: GICI-LIB+3DGS
arxiv.org/abs/2502.10975
Zelin Zhou, Saurav Uprety, Shichuang Nie, Hongzhou Yang
tl;dr: GICI-LIB+3DGS
arxiv.org/abs/2502.10975
Reposted by Jiri Fajtl
IM360: Textured Mesh Reconstruction for Large-scale Indoor Mapping with 360
Dongki Jung, Jaehoon Choi, Yonghan Lee, Dinesh Manocha
tl;dr: spherical camera model->SfM; DebSDF; classical texture mapping->differentiable rendering->neural texture fine-tuning
arxiv.org/abs/2502.12545
Dongki Jung, Jaehoon Choi, Yonghan Lee, Dinesh Manocha
tl;dr: spherical camera model->SfM; DebSDF; classical texture mapping->differentiable rendering->neural texture fine-tuning
arxiv.org/abs/2502.12545




February 20, 2025 at 9:01 AM
IM360: Textured Mesh Reconstruction for Large-scale Indoor Mapping with 360
Dongki Jung, Jaehoon Choi, Yonghan Lee, Dinesh Manocha
tl;dr: spherical camera model->SfM; DebSDF; classical texture mapping->differentiable rendering->neural texture fine-tuning
arxiv.org/abs/2502.12545
Dongki Jung, Jaehoon Choi, Yonghan Lee, Dinesh Manocha
tl;dr: spherical camera model->SfM; DebSDF; classical texture mapping->differentiable rendering->neural texture fine-tuning
arxiv.org/abs/2502.12545
Reposted by Jiri Fajtl

1/ 🎉 Excited to share our work, "Composed Image Retrieval for Training-Free Domain Conversion", accepted at WACV 2025! 🚀

December 5, 2024 at 12:59 PM
1/ 🎉 Excited to share our work, "Composed Image Retrieval for Training-Free Domain Conversion", accepted at WACV 2025! 🚀
Reposted by Jiri Fajtl

Yes yes yesssssss
I've been waiting for this for a while. Open source procedural scene generation from NVIDIA. This kind of thing would be really useful for scaling up simulation data for robots: joss.theoj.org/papers/10.21...

February 3, 2025 at 11:45 PM
Yes yes yesssssss
Reposted by Jiri Fajtl

I've been waiting for this for a while. Open source procedural scene generation from NVIDIA. This kind of thing would be really useful for scaling up simulation data for robots: joss.theoj.org/papers/10.21...
February 3, 2025 at 11:42 PM
I've been waiting for this for a while. Open source procedural scene generation from NVIDIA. This kind of thing would be really useful for scaling up simulation data for robots: joss.theoj.org/papers/10.21...
Reposted by Jiri Fajtl

📢 ScanNet++ v2 Benchmark Release! 🏆
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
January 31, 2025 at 4:29 PM
📢 ScanNet++ v2 Benchmark Release! 🏆
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
Test your state-of-the-art models on:
🔹 Novel View Synthesis 📸➡️🖼️
🔹 3D Semantic & Instance Segmentation 🤖🔍🕶️
Shoutout to @awhiteguitar.bsky.social & Yueh-Cheng Liu for their incredible work👏
🚀Check it out: kaldir.vc.in.tum.de/scannetpp/
Reposted by Jiri Fajtl

Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
How has DeepSeek improved the Transformer architecture?
This Gradient Updates issue goes over the major changes that went into DeepSeek’s most recent model.
epoch.ai
January 30, 2025 at 9:07 PM
Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
Reposted by Jiri Fajtl

This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235

January 29, 2025 at 4:15 PM
This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235
Reposted by Jiri Fajtl

I noticed that I'm not using bsky much anymore. Not sure why, vibes.
Anyways, someone noticing that DeepSeek refuses to answer *anything* about Xi Jinping, even the question whether he exists at all, triggered me writing a short snippet on safety fine-tuning: lb.eyer.be/s/safety-sft...
Anyways, someone noticing that DeepSeek refuses to answer *anything* about Xi Jinping, even the question whether he exists at all, triggered me writing a short snippet on safety fine-tuning: lb.eyer.be/s/safety-sft...

January 26, 2025 at 9:21 PM
I noticed that I'm not using bsky much anymore. Not sure why, vibes.
Anyways, someone noticing that DeepSeek refuses to answer *anything* about Xi Jinping, even the question whether he exists at all, triggered me writing a short snippet on safety fine-tuning: lb.eyer.be/s/safety-sft...
Anyways, someone noticing that DeepSeek refuses to answer *anything* about Xi Jinping, even the question whether he exists at all, triggered me writing a short snippet on safety fine-tuning: lb.eyer.be/s/safety-sft...
Reposted by Jiri Fajtl
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465

January 22, 2025 at 9:11 AM
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465
Reposted by Jiri Fajtl

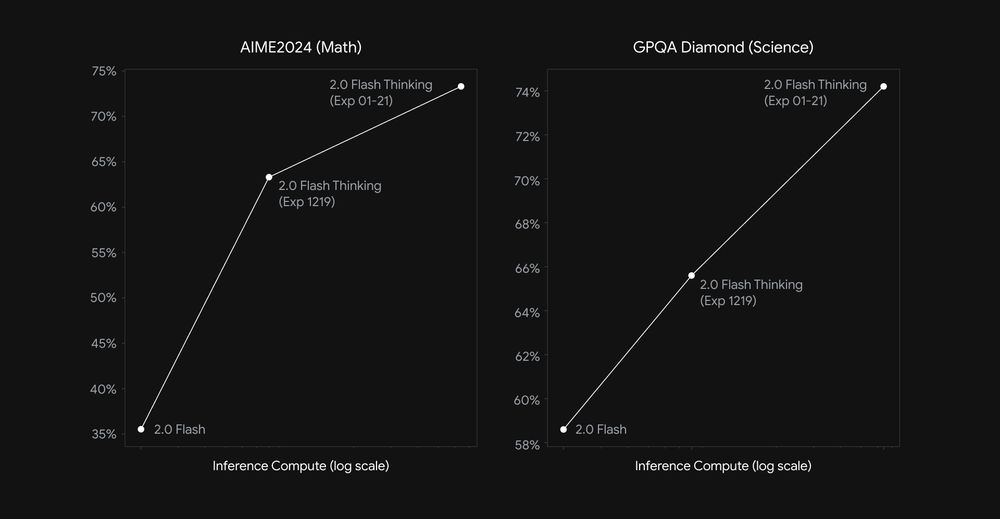
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
January 22, 2025 at 12:31 AM
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Reposted by Jiri Fajtl
Given the r1 furor, folks should really read this paper on policy-gradient based search: arxiv.org/abs/1904.03646

Policy Gradient Search: Online Planning and Expert Iteration without Search Trees
Monte Carlo Tree Search (MCTS) algorithms perform simulation-based search to improve policies online. During search, the simulation policy is adapted to explore the most promising lines of play. MCTS ...
arxiv.org
January 21, 2025 at 5:01 PM
Given the r1 furor, folks should really read this paper on policy-gradient based search: arxiv.org/abs/1904.03646
Reposted by Jiri Fajtl

Exactly why @bsky.app is so important. Engaging on this platform is important. As is growing this platform.
Which one of these men joins Tom Anderson and MySoace in the annals of history first ?
Their greed is our opportunity.
Which one of these men joins Tom Anderson and MySoace in the annals of history first ?
Their greed is our opportunity.

It is not free speech when Trump aligned oligarchs have their thumbs on the algorithms of all the social media apps.

January 21, 2025 at 3:15 AM
Exactly why @bsky.app is so important. Engaging on this platform is important. As is growing this platform.
Which one of these men joins Tom Anderson and MySoace in the annals of history first ?
Their greed is our opportunity.
Which one of these men joins Tom Anderson and MySoace in the annals of history first ?
Their greed is our opportunity.
Reposted by Jiri Fajtl

DeepSeek AI just released DeepSeek-R1, an open-source "reasoning" AI model that claims to match or surpass OpenAI's o1 in certain benchmarks, including AIME, MATH-500, and SWE-bench Verified.
1/5
1/5

January 21, 2025 at 2:04 PM
DeepSeek AI just released DeepSeek-R1, an open-source "reasoning" AI model that claims to match or surpass OpenAI's o1 in certain benchmarks, including AIME, MATH-500, and SWE-bench Verified.
1/5
1/5
Reposted by Jiri Fajtl

New Glenn got payload to orbit on their first try. Lost the booster sometime around restart for landing. Amazingly good first try for any rocket system (I grew up with Europa, where my dad flew to Woomera in the desert every week; 10 launches, 10 failures. Ouch!) This is great!!!!
January 16, 2025 at 7:24 AM
New Glenn got payload to orbit on their first try. Lost the booster sometime around restart for landing. Amazingly good first try for any rocket system (I grew up with Europa, where my dad flew to Woomera in the desert every week; 10 launches, 10 failures. Ouch!) This is great!!!!
Reposted by Jiri Fajtl

Excited to share that today our paper recommender platform www.scholar-inbox.com has reached 20k users! We hope to reach 100k by the end of the year.. Lots of new features are being worked on currently and rolled out soon.

January 15, 2025 at 10:03 PM
Excited to share that today our paper recommender platform www.scholar-inbox.com has reached 20k users! We hope to reach 100k by the end of the year.. Lots of new features are being worked on currently and rolled out soon.
Reposted by Jiri Fajtl

Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!
December 19, 2024 at 4:50 PM
Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!