



Daniel Jiang
@danielrjiang.bsky.social
Research Scientist Meta, Adjunct Professor at University of Pittsburgh. Interested in reinforcement learning, approximate DP, adaptive experimentation, Bayesian optimization, & operations research. http://danielrjiang.github.io
📍Chicago, IL
📍Chicago, IL
Reposted by Daniel Jiang

First draft online version of The RLHF Book is DONE. Recently I've been creating the advanced discussion chapters on everything from Constitutional AI to evaluation and character training, but I also sneak in consistent improvements to the RL specific chapter.
rlhfbook.com
rlhfbook.com

April 16, 2025 at 7:01 PM
First draft online version of The RLHF Book is DONE. Recently I've been creating the advanced discussion chapters on everything from Constitutional AI to evaluation and character training, but I also sneak in consistent improvements to the RL specific chapter.
rlhfbook.com
rlhfbook.com
At ICLR 2025 in Singapore, my co-authors and I presented two papers on RL. Feel free to let us know of any feedback and let me know if you'd like to chat!
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...


April 26, 2025 at 1:51 AM
At ICLR 2025 in Singapore, my co-authors and I presented two papers on RL. Feel free to let us know of any feedback and let me know if you'd like to chat!
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
Our team at Meta is hiring a postdoc researcher! Our group conducts both fundamental and applied research in reinforcement learning, with a focus on applications in Meta's advertising systems.
March 17, 2025 at 1:59 PM
Our team at Meta is hiring a postdoc researcher! Our group conducts both fundamental and applied research in reinforcement learning, with a focus on applications in Meta's advertising systems.
Reposted by Daniel Jiang

Congrats to this year's Turing award winners! www.nytimes.com/2025/03/05/t...
Incidentally, if you'd like to hear from them, we know a place they've given / are giving keynotes
Incidentally, if you'd like to hear from them, we know a place they've given / are giving keynotes

Turing Award Goes to A.I. Pioneers Andrew Barto and Richard Sutton
Andrew Barto and Richard Sutton developed reinforcement learning, a technique vital to chatbots like ChatGPT.
www.nytimes.com
March 7, 2025 at 2:38 AM
Congrats to this year's Turing award winners! www.nytimes.com/2025/03/05/t...
Incidentally, if you'd like to hear from them, we know a place they've given / are giving keynotes
Incidentally, if you'd like to hear from them, we know a place they've given / are giving keynotes
Reposted by Daniel Jiang

Given a high-quality verifier, language model accuracy can be improved by scaling inference-time compute (e.g., w/ repeated sampling). When can we expect similar gains without an external verifier?
New paper: Self-Improvement in Language Models: The Sharpening Mechanism
arxiv.org/abs/2412.01951
New paper: Self-Improvement in Language Models: The Sharpening Mechanism
arxiv.org/abs/2412.01951


December 14, 2024 at 4:10 PM
Given a high-quality verifier, language model accuracy can be improved by scaling inference-time compute (e.g., w/ repeated sampling). When can we expect similar gains without an external verifier?
New paper: Self-Improvement in Language Models: The Sharpening Mechanism
arxiv.org/abs/2412.01951
New paper: Self-Improvement in Language Models: The Sharpening Mechanism
arxiv.org/abs/2412.01951
Reposted by Daniel Jiang

An updated intro to reinforcement learning by Kevin Murphy: arxiv.org/abs/2412.05265! Like their books, it covers a lot and is quite up to date with modern approaches. It also is pretty unique in coverage, I don't think a lot of this is synthesized anywhere else yet

Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based met...
arxiv.org
December 9, 2024 at 2:27 PM
An updated intro to reinforcement learning by Kevin Murphy: arxiv.org/abs/2412.05265! Like their books, it covers a lot and is quite up to date with modern approaches. It also is pretty unique in coverage, I don't think a lot of this is synthesized anywhere else yet
Reposted by Daniel Jiang

I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
web.mit.edu
November 27, 2024 at 1:36 PM
I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
Reposted by Daniel Jiang

Want to learn / teach RL?
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.



November 25, 2024 at 12:08 PM
Want to learn / teach RL?
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.
Check out new book draft:
Reinforcement Learning - Foundations sites.google.com/view/rlfound...
W/ Shie Mannor & Yishay Mansour
This is a rigorous first course in RL, based on our teaching at TAU CS and Technion ECE.
Reposted by Daniel Jiang

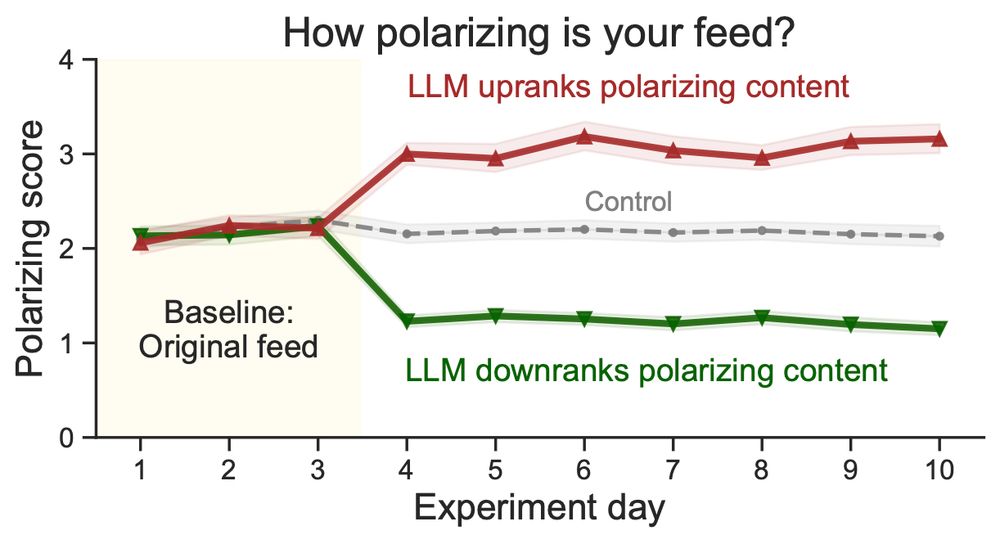
New paper: Do social media algorithms shape affective polarization?
We ran a field experiment on X/Twitter (N=1,256) using LLMs to rerank content in real-time, adjusting exposure to polarizing posts. Result: Algorithmic ranking impacts feelings toward the political outgroup! 🧵⬇️
We ran a field experiment on X/Twitter (N=1,256) using LLMs to rerank content in real-time, adjusting exposure to polarizing posts. Result: Algorithmic ranking impacts feelings toward the political outgroup! 🧵⬇️
November 25, 2024 at 8:32 PM
New paper: Do social media algorithms shape affective polarization?
We ran a field experiment on X/Twitter (N=1,256) using LLMs to rerank content in real-time, adjusting exposure to polarizing posts. Result: Algorithmic ranking impacts feelings toward the political outgroup! 🧵⬇️
We ran a field experiment on X/Twitter (N=1,256) using LLMs to rerank content in real-time, adjusting exposure to polarizing posts. Result: Algorithmic ranking impacts feelings toward the political outgroup! 🧵⬇️
Reposted by Daniel Jiang
The RL (and some non-RL folks) starter pack is almost full. Pretty clear that the academic move here has succeeded
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg
November 18, 2024 at 8:30 PM
The RL (and some non-RL folks) starter pack is almost full. Pretty clear that the academic move here has succeeded
go.bsky.app/3WPHcHg
go.bsky.app/3WPHcHg