




Christopher Schröder
@cschroeder.bsky.social
PhD Candidate @ Leipzig University. Active Learning, Text Classification and LLMs. Check out my active learning library: small-text. #NLP #NLProc #ActiveLearning #LLM #ML #AI
Reposted by Christopher Schröder

We just released "German Commons", the largest openly-licensed German text dataset for LLM training: 154B tokens with clear usage rights for research and commercial use.
huggingface.co/datasets/coral-nlp/german-commons
huggingface.co/datasets/coral-nlp/german-commons

coral-nlp/german-commons · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
October 27, 2025 at 12:45 PM
We just released "German Commons", the largest openly-licensed German text dataset for LLM training: 154B tokens with clear usage rights for research and commercial use.
huggingface.co/datasets/coral-nlp/german-commons
huggingface.co/datasets/coral-nlp/german-commons
Reposted by Christopher Schröder

🏆 Thrilled to share that our HateDay paper has received an Outstanding Paper Award at #ACL2025
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...

July 31, 2025 at 8:05 AM
🏆 Thrilled to share that our HateDay paper has received an Outstanding Paper Award at #ACL2025
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Reposted by Christopher Schröder
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.

July 18, 2025 at 2:18 PM
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Reposted by Christopher Schröder
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...

July 16, 2025 at 9:04 PM
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...
Reposted by Christopher Schröder

Do not forget to participate in the #TREC2025 Tip-of-the-Tongue (ToT) Track :)
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines

June 27, 2025 at 2:46 PM
Do not forget to participate in the #TREC2025 Tip-of-the-Tongue (ToT) Track :)
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines

Big fan of @ai2.bsky.social's semantic scholar feeds. Usually great for paper recommendations. Yesterday it recommended... a paper that blatantly plagiarized from a former student's thesis that I co-supervised. So, I guess the algorithm really knows my interests 😅.
May 26, 2025 at 6:00 PM
Big fan of @ai2.bsky.social's semantic scholar feeds. Usually great for paper recommendations. Yesterday it recommended... a paper that blatantly plagiarized from a former student's thesis that I co-supervised. So, I guess the algorithm really knows my interests 😅.
Reposted by Christopher Schröder

Our recent paper on the impact of register (genre) on LLM performance. Key points: news do poor in evaluation, while opinionated texts are among the best. We hope this work can be used to understand the impact of register on LLMs and improve training data mixes! arxiv.org/abs/2504.01542

April 15, 2025 at 12:57 PM
Our recent paper on the impact of register (genre) on LLM performance. Key points: news do poor in evaluation, while opinionated texts are among the best. We hope this work can be used to understand the impact of register on LLMs and improve training data mixes! arxiv.org/abs/2504.01542
Reposted by Christopher Schröder

Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
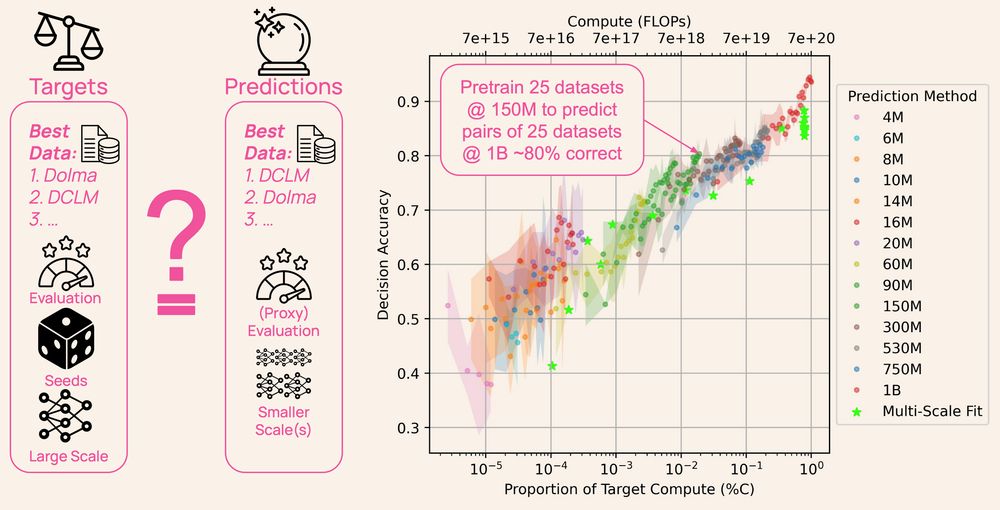
April 15, 2025 at 1:01 PM
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
Reposted by Christopher Schröder

A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏

March 20, 2025 at 6:20 PM
A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Reposted by Christopher Schröder

Can a Large Language Model (LLM) with zero Pokémon-specific training achieve expert-level performance in competitive Pokémon battles?
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!

March 7, 2025 at 3:47 PM
Can a Large Language Model (LLM) with zero Pokémon-specific training achieve expert-level performance in competitive Pokémon battles?
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!
Reposted by Christopher Schröder

(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
February 20, 2025 at 6:08 PM
(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
Reposted by Christopher Schröder

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 6:10 PM
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
Reposted by Christopher Schröder

More than 8500 submissions to ACL 2025 (ARR February 2025 cycle)! That is an increase of 3000 submissions compared to ACL 2024. It will be a fun reviewing period. 😅💯
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
February 16, 2025 at 1:19 PM
More than 8500 submissions to ACL 2025 (ARR February 2025 cycle)! That is an increase of 3000 submissions compared to ACL 2024. It will be a fun reviewing period. 😅💯
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
🔥 𝐅𝐢𝐧𝐚𝐥 𝐂𝐚𝐥𝐥 𝐚𝐧𝐝 𝐃𝐞𝐚𝐝𝐥𝐢𝐧𝐞 𝐄𝐱𝐭𝐞𝐧𝐬𝐢𝐨𝐧: Survey on Data Annotation and Active Learning
We need your support in web survey in which we investigate how recent advancements in NLP, particularly LLMs, have influenced the need for labeled data in supervised machine learning.
#NLP #NLProc #ML #AI
We need your support in web survey in which we investigate how recent advancements in NLP, particularly LLMs, have influenced the need for labeled data in supervised machine learning.
#NLP #NLProc #ML #AI

January 12, 2025 at 5:26 PM
Reposted by Christopher Schröder

Hallo and happy New Year #NLProc :) Julia Romberg, a postdoc in my group in Cologne, together with other collaborators, is conducting a survey on the use of Active Learning in NLP. Find the link in the thread below!
January 6, 2025 at 11:57 AM
Hallo and happy New Year #NLProc :) Julia Romberg, a postdoc in my group in Cologne, together with other collaborators, is conducting a survey on the use of Active Learning in NLP. Find the link in the thread below!
Here’s just one of the many exciting questions from our survey. If these topics resonate with you and you have experience working on supervised learning with text (i.e., supervised learning in Natural Language Processing), we warmly invite you to participate!

December 27, 2024 at 2:25 PM
Here’s just one of the many exciting questions from our survey. If these topics resonate with you and you have experience working on supervised learning with text (i.e., supervised learning in Natural Language Processing), we warmly invite you to participate!
Reposted by Christopher Schröder
Hello bluesky #NLProc world! Happy to announce the 12th Argument Mining workshop will be colocated with #ACL2025 in Vienna!

We are thrilled to announce the 12th Workshop on Argument Mining, focusing on Broadening the Scope of Argument Mining. The workshop will be co-located with
#ACL2025 in Vienna, Austria. More information will be available on the website argmining-org.github.io
#Argmining2025
#ACL2025 in Vienna, Austria. More information will be available on the website argmining-org.github.io
#Argmining2025
argmining-org.github.io
December 6, 2024 at 5:57 PM
Reposted by Christopher Schröder

A librarian that previously worked at the British Library created a relatively small dataset of bsky posts, hundreds of times smaller than previous researchers, to help folks create toxicity filters and stuff.
So people bullied him & posted death threats.
He took it down.
Nice one, folks.
So people bullied him & posted death threats.
He took it down.
Nice one, folks.
November 28, 2024 at 5:33 AM
A librarian that previously worked at the British Library created a relatively small dataset of bsky posts, hundreds of times smaller than previous researchers, to help folks create toxicity filters and stuff.
So people bullied him & posted death threats.
He took it down.
Nice one, folks.
So people bullied him & posted death threats.
He took it down.
Nice one, folks.
Oh, I forgot... this is also the first version for which I dropped the Twitter share button 😛. Let me know once there is a replacement for bluesky.
🐣 New release: small-text v2.0.0.dev1
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms

November 26, 2024 at 4:26 PM
Oh, I forgot... this is also the first version for which I dropped the Twitter share button 😛. Let me know once there is a replacement for bluesky.
Reposted by Christopher Schröder

Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
November 26, 2024 at 6:29 AM
Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
Reposted by Christopher Schröder

🐣 New release: small-text v2.0.0.dev1
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms
November 24, 2024 at 7:39 PM
🐣 New release: small-text v2.0.0.dev1
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms
With Small Language Models on the rise, the new version of small-text has been long overdue! Despite the generative AI hype, many real-world tasks still rely on supervised learning—which is reliant on labeled data.
#activelearning #nlproc #nlp #llms
Reposted by Christopher Schröder

Hope I'm the first to post this all time classic on this platform
November 19, 2024 at 4:51 AM
Hope I'm the first to post this all time classic on this platform