



Seth Karten
@sethkarten.ai
Autonomous Agents | PhD @ Princeton | Prev: CMU, Waymo | NSF GRFP Fellow
Pinned
Seth Karten
@sethkarten.ai
· Jul 23
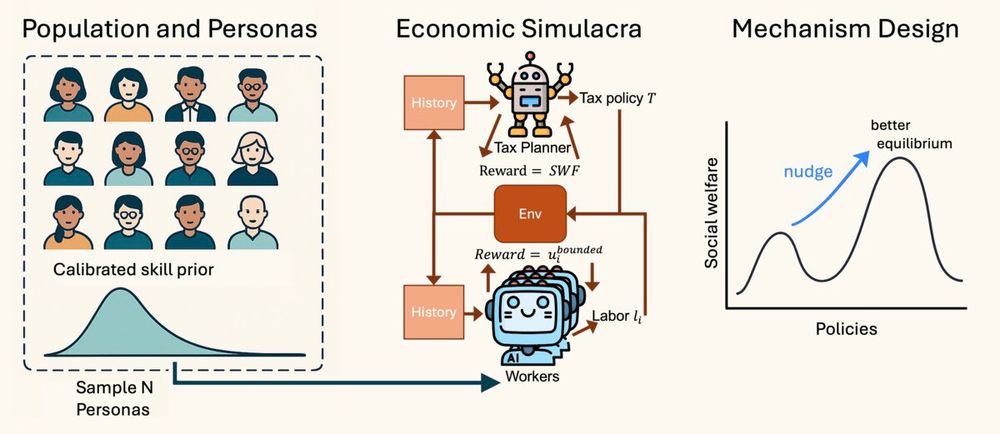
🚀 New preprint!
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
I think I accidentally stumbled upon engagement baiting from first principles
Ill stay on bluesky as long as the 10 accounts I like to see still post here
Ill stay on bluesky as long as the 10 accounts I like to see still post here
December 25, 2025 at 7:58 PM
I think I accidentally stumbled upon engagement baiting from first principles
Ill stay on bluesky as long as the 10 accounts I like to see still post here
Ill stay on bluesky as long as the 10 accounts I like to see still post here
You should make one of those github repos called
Awesome-Multi-agent-Papers
Because this looks like a solid list
Awesome-Multi-agent-Papers
Because this looks like a solid list
December 25, 2025 at 7:56 PM
You should make one of those github repos called
Awesome-Multi-agent-Papers
Because this looks like a solid list
Awesome-Multi-agent-Papers
Because this looks like a solid list
I do appreciate you for making this contribution, but it is hard to compete with other platforms that do it centralized
December 24, 2025 at 7:32 AM
I do appreciate you for making this contribution, but it is hard to compete with other platforms that do it centralized
I already use it and it doesnt solve the issue with bugs, lack of discoverability, lack of useful recommendation, and otherwise a worse experience than X or even linkedin
December 24, 2025 at 7:32 AM
I already use it and it doesnt solve the issue with bugs, lack of discoverability, lack of useful recommendation, and otherwise a worse experience than X or even linkedin
I think I might leave bluesky tbh

December 24, 2025 at 7:24 AM
I think I might leave bluesky tbh
Blanket use of LLMs should not decrease significance of results. I am distrusting of any researcher that would not use their own product
December 10, 2025 at 5:09 AM
Blanket use of LLMs should not decrease significance of results. I am distrusting of any researcher that would not use their own product
Personally I am worried about this effect in disclosure

December 9, 2025 at 8:01 PM
Personally I am worried about this effect in disclosure
Reposted by Seth Karten
How do we close the gap between specialist RL and generalist LLM agents?
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)

November 24, 2025 at 5:50 PM
How do we close the gap between specialist RL and generalist LLM agents?
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
Best account to aggregate MAS research
December 3, 2025 at 5:16 PM
Best account to aggregate MAS research
The assumption is not that bad. Additionally it is not a hard threshold so the methods will scale as models get better
November 28, 2025 at 6:47 PM
The assumption is not that bad. Additionally it is not a hard threshold so the methods will scale as models get better
EC is partially solved with foundation models. The social settings arent and the LLM Economist takeaways are going to be very practical moving forward. If you have aligned agents, many multi-agent problems become simple optimization problems. You just need to train with a scaffold like claude code
November 28, 2025 at 6:29 AM
EC is partially solved with foundation models. The social settings arent and the LLM Economist takeaways are going to be very practical moving forward. If you have aligned agents, many multi-agent problems become simple optimization problems. You just need to train with a scaffold like claude code
These are pretty cool.. but i guess nothing ever happened with it? I like the jersey city uber eats robots a lot too
But we should still be building and deploying things here 100x faster
But we should still be building and deploying things here 100x faster
November 27, 2025 at 9:23 PM
These are pretty cool.. but i guess nothing ever happened with it? I like the jersey city uber eats robots a lot too
But we should still be building and deploying things here 100x faster
But we should still be building and deploying things here 100x faster
Philly is a good place to deploy. My issue is the general anti AI sentiment is stronger in the northeast. (At least my perception as a lifelong northeaster) Many view the world as zero sum instead of general sum. It is much easier to build something new when you can abundantly find likeminded people
November 27, 2025 at 8:58 PM
Philly is a good place to deploy. My issue is the general anti AI sentiment is stronger in the northeast. (At least my perception as a lifelong northeaster) Many view the world as zero sum instead of general sum. It is much easier to build something new when you can abundantly find likeminded people
Between setbacks in boston from taxi unions and now this, i have pretty much given up on the northeast long term. At this rate the northeast will become a 20th century museum like europe
November 27, 2025 at 8:43 PM
Between setbacks in boston from taxi unions and now this, i have pretty much given up on the northeast long term. At this rate the northeast will become a 20th century museum like europe
Trains should be autonomous
November 26, 2025 at 10:32 PM
Trains should be autonomous
I’ll be in San Diego at NeurIPS Dec 3-7!
DM or email if you want to chat about
- building the foundation agents through games
- PokeAgent Challenge & PokéChamp
- LLM Economist & autonomous business agents
DM or email if you want to chat about
- building the foundation agents through games
- PokeAgent Challenge & PokéChamp
- LLM Economist & autonomous business agents
November 26, 2025 at 9:32 PM
I’ll be in San Diego at NeurIPS Dec 3-7!
DM or email if you want to chat about
- building the foundation agents through games
- PokeAgent Challenge & PokéChamp
- LLM Economist & autonomous business agents
DM or email if you want to chat about
- building the foundation agents through games
- PokeAgent Challenge & PokéChamp
- LLM Economist & autonomous business agents
How do we close the gap between specialist RL and generalist LLM agents?
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
November 24, 2025 at 5:50 PM
How do we close the gap between specialist RL and generalist LLM agents?
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
We're benchmarking it in Pokémon. Join us at the PokeAgent Challenge competition workshop @ NeurIPS 2025.
📍 Dec 7, 8AM
🎮 Track 1: Competitive Pokémon (game-theoretic reasoning)
🗺️ Track 2: Speedrunning (long-horizon planning)
Yes, please bring on the supply
We need:
- cheap energy
- cheap housing
- cheap food
Only possible by increasing supply
We need:
- cheap energy
- cheap housing
- cheap food
Only possible by increasing supply
November 11, 2025 at 8:45 PM
Yes, please bring on the supply
We need:
- cheap energy
- cheap housing
- cheap food
Only possible by increasing supply
We need:
- cheap energy
- cheap housing
- cheap food
Only possible by increasing supply
Gen 1 OU Pokemon Qualifiers end tonight and I'm not even competing, yet I'm nervously watching error bars converge.
(5/5)
(5/5)
October 20, 2025 at 3:50 AM
Gen 1 OU Pokemon Qualifiers end tonight and I'm not even competing, yet I'm nervously watching error bars converge.
(5/5)
(5/5)
Most LLM arenas use Bradley-Terry (batch MLE)—accurate but requires full recomputation. Glicko-1 offers the best of both worlds: online updates and convergence to the batch optimum, with uncertainty estimates included.
(4/5)
(4/5)
October 20, 2025 at 3:50 AM
Most LLM arenas use Bradley-Terry (batch MLE)—accurate but requires full recomputation. Glicko-1 offers the best of both worlds: online updates and convergence to the batch optimum, with uncertainty estimates included.
(4/5)
(4/5)
Top-3 agents converge across all methods (250+ games each). But ranks 4+ show systematic disagreement:
-Elo diverges from HR even when HR's error bars don't overlap
-Glicko-1 agrees with HR despite being online
(3/5)
-Elo diverges from HR even when HR's error bars don't overlap
-Glicko-1 agrees with HR despite being online
(3/5)
October 20, 2025 at 3:50 AM
Top-3 agents converge across all methods (250+ games each). But ranks 4+ show systematic disagreement:
-Elo diverges from HR even when HR's error bars don't overlap
-Glicko-1 agrees with HR despite being online
(3/5)
-Elo diverges from HR even when HR's error bars don't overlap
-Glicko-1 agrees with HR despite being online
(3/5)
In the NeurIPS PokeAgent Challenge, we stress-test 4 ranking systems across (100k+ agent matches):
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)


October 20, 2025 at 3:50 AM
In the NeurIPS PokeAgent Challenge, we stress-test 4 ranking systems across (100k+ agent matches):
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
Every LLM eval uses Bradley-Terry Elo rankings. Almost none report uncertainty. Should we trust them? Maybe there is something better... 👇
(1/5)
(1/5)
October 20, 2025 at 3:50 AM
Every LLM eval uses Bradley-Terry Elo rankings. Almost none report uncertainty. Should we trust them? Maybe there is something better... 👇
(1/5)
(1/5)