



Seth Karten
@sethkarten.ai
Autonomous Agents | PhD @ Princeton | Prev: CMU, Waymo | NSF GRFP Fellow
In the NeurIPS PokeAgent Challenge, we stress-test 4 ranking systems across (100k+ agent matches):
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)


October 20, 2025 at 3:50 AM
In the NeurIPS PokeAgent Challenge, we stress-test 4 ranking systems across (100k+ agent matches):
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
- Bradley-terry (batch MLE, our ground truth)
- Elo (online, chess-standard)
- Glicko-1 (online, uncertainty-aware)
- GXE: (Glicko-derived win %)
(2/5)
A benchmark environment is nothing without data so you can pretrain before you RL.
Announcing our replay archive preview: We are releasing an additional 25k games to help you train a metagame exploiter (5 million more released after qualifier)
replays.pokeagentshowdown. com:8443/
(3/3)
Announcing our replay archive preview: We are releasing an additional 25k games to help you train a metagame exploiter (5 million more released after qualifier)
replays.pokeagentshowdown. com:8443/
(3/3)

October 15, 2025 at 5:50 PM
A benchmark environment is nothing without data so you can pretrain before you RL.
Announcing our replay archive preview: We are releasing an additional 25k games to help you train a metagame exploiter (5 million more released after qualifier)
replays.pokeagentshowdown. com:8443/
(3/3)
Announcing our replay archive preview: We are releasing an additional 25k games to help you train a metagame exploiter (5 million more released after qualifier)
replays.pokeagentshowdown. com:8443/
(3/3)
Pokemon is truly the pareto frontier of agent research
- The RPG requires an autonomous embodied agentic agent with perception, planning, memory, and control
- VGC and Gen 9 OU penalize erroneous actions with fast-paced opponent-modeling in short games
(1/3)
- The RPG requires an autonomous embodied agentic agent with perception, planning, memory, and control
- VGC and Gen 9 OU penalize erroneous actions with fast-paced opponent-modeling in short games
(1/3)
October 15, 2025 at 5:50 PM
Pokemon is truly the pareto frontier of agent research
- The RPG requires an autonomous embodied agentic agent with perception, planning, memory, and control
- VGC and Gen 9 OU penalize erroneous actions with fast-paced opponent-modeling in short games
(1/3)
- The RPG requires an autonomous embodied agentic agent with perception, planning, memory, and control
- VGC and Gen 9 OU penalize erroneous actions with fast-paced opponent-modeling in short games
(1/3)
If you arent paying attention, we are in a rapidly shifting period of ML paper culture. ICLR/ICML/NeurIPS are being treated as random, out of touch processes with more and more unnecessary work to submit
Most people are saying TMLR is the only good alternative, but are skeptical
Most people are saying TMLR is the only good alternative, but are skeptical

September 24, 2025 at 2:31 PM
If you arent paying attention, we are in a rapidly shifting period of ML paper culture. ICLR/ICML/NeurIPS are being treated as random, out of touch processes with more and more unnecessary work to submit
Most people are saying TMLR is the only good alternative, but are skeptical
Most people are saying TMLR is the only good alternative, but are skeptical
🚨 Hackathon Weekend! 🚨
Jumpstart your PokéAgent Challenge submission ahead of NeurIPS!
📅 Sept 13–14
✅ Leaderboards reset Sat 10AM EDT
🎙️ Lightning talks in LLMs, RL, and Pokemon
💬 Live Office hours
🏆 $2k in prizes
Jumpstart your PokéAgent Challenge submission ahead of NeurIPS!
📅 Sept 13–14
✅ Leaderboards reset Sat 10AM EDT
🎙️ Lightning talks in LLMs, RL, and Pokemon
💬 Live Office hours
🏆 $2k in prizes

September 2, 2025 at 1:44 PM
🚨 Hackathon Weekend! 🚨
Jumpstart your PokéAgent Challenge submission ahead of NeurIPS!
📅 Sept 13–14
✅ Leaderboards reset Sat 10AM EDT
🎙️ Lightning talks in LLMs, RL, and Pokemon
💬 Live Office hours
🏆 $2k in prizes
Jumpstart your PokéAgent Challenge submission ahead of NeurIPS!
📅 Sept 13–14
✅ Leaderboards reset Sat 10AM EDT
🎙️ Lightning talks in LLMs, RL, and Pokemon
💬 Live Office hours
🏆 $2k in prizes
The solution would generalize to another two player partially observable turn-based text game. The most bespoke items are tools, but there has been work recently that shows that you can make these tools modular LLM calls, further increasing generality

August 20, 2025 at 5:47 PM
The solution would generalize to another two player partially observable turn-based text game. The most bespoke items are tools, but there has been work recently that shows that you can make these tools modular LLM calls, further increasing generality

Papers are dead. Maybe it is time to start the youtube channel…

August 12, 2025 at 6:43 AM
Papers are dead. Maybe it is time to start the youtube channel…
Democratic alignment: in a special case, periodic citizen voting can fire the planner. Leader turnover keeps welfare high and prevents policy drift—central nudging plus decentralized oversight in one sandbox.
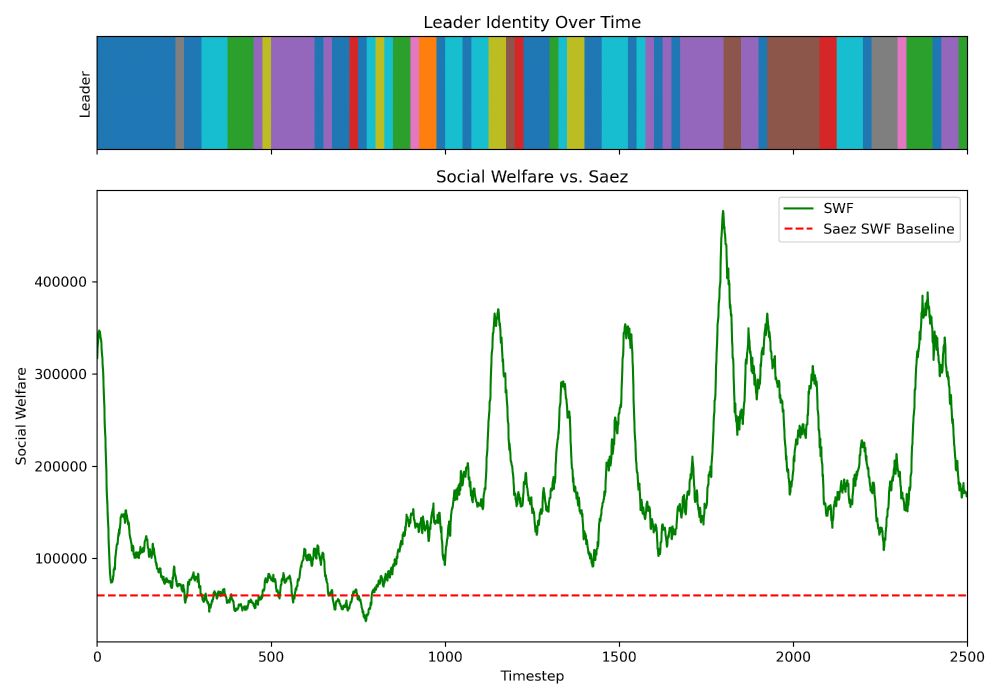
July 23, 2025 at 5:30 PM
Democratic alignment: in a special case, periodic citizen voting can fire the planner. Leader turnover keeps welfare high and prevents policy drift—central nudging plus decentralized oversight in one sandbox.
Centralized nudging: the planner’s marginal taxes beat U.S. statutory rates and approach Saez on aggregate welfare (almost double vs baseline).
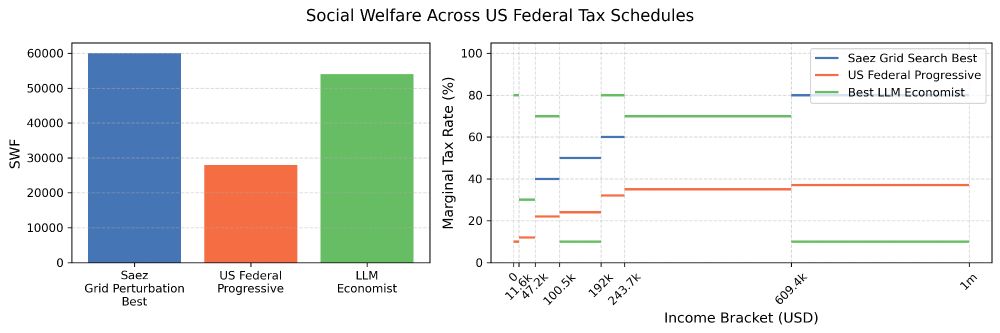
July 23, 2025 at 5:30 PM
Centralized nudging: the planner’s marginal taxes beat U.S. statutory rates and approach Saez on aggregate welfare (almost double vs baseline).
Synthetic behavioral policies → we sample workers from 2023 ACS skills & demographics, then let each agent verify its own bounded rational utility from individualized preferences, enabling counterfactual reasoning.
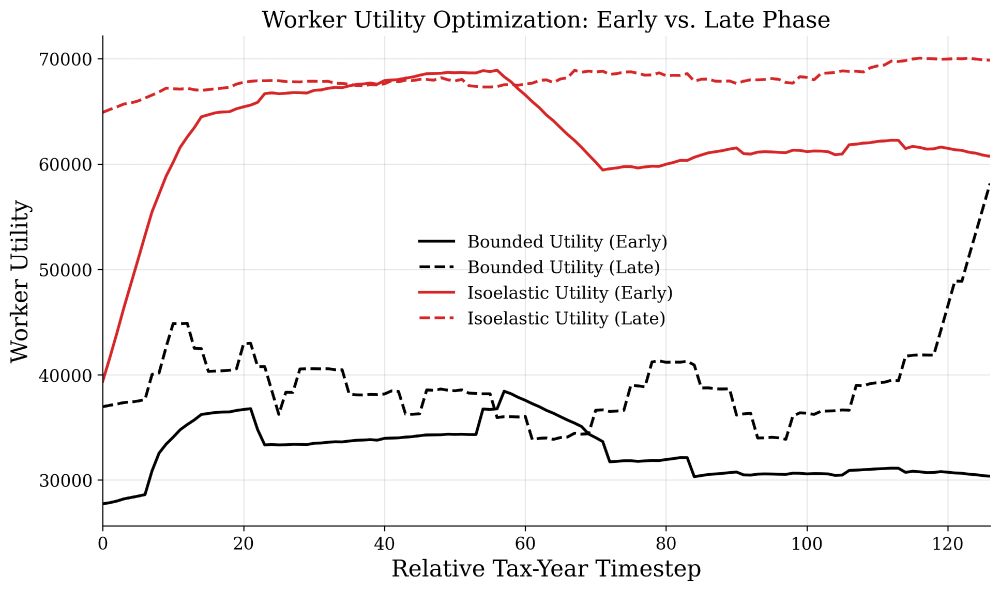
July 23, 2025 at 5:30 PM
Synthetic behavioral policies → we sample workers from 2023 ACS skills & demographics, then let each agent verify its own bounded rational utility from individualized preferences, enabling counterfactual reasoning.
🚀 New preprint!
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
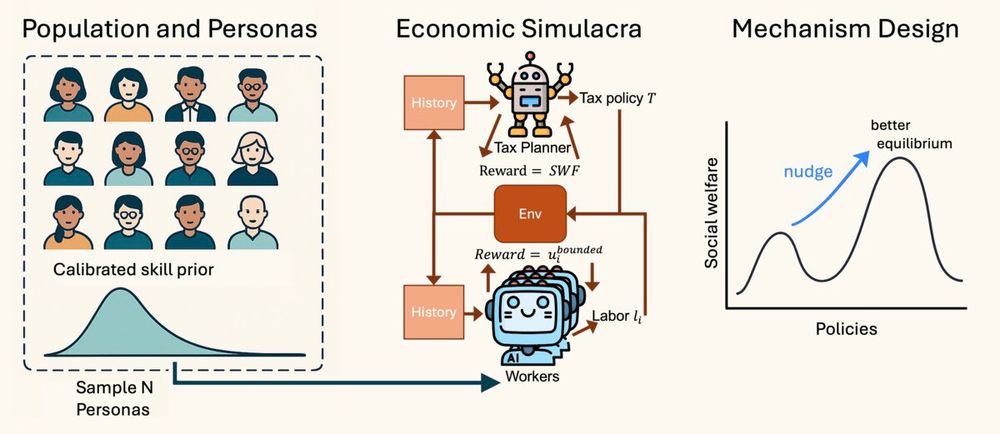
July 23, 2025 at 5:30 PM
🚀 New preprint!
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
🤔 Can one agent “nudge” a synthetic civilization of Census‑grounded agents toward higher social welfare—all by optimizing utilities in‑context? Meet the LLM Economist ↓
Open review doesnt seem public yet but here are the titles
July 18, 2025 at 8:05 PM
Open review doesnt seem public yet but here are the titles
🚀 Launch day! The NeurIPS 2025 PokéAgent Challenge is live. @neuripsconf.bsky.social
Two tracks:
① Showdown Battling – imperfect-info, turn-based strategy
② Pokemon Emerald Speedrunning – long horizon RPG planning
5 M labeled replays • starter kit • baselines.
Bring your LLM, RL, or hybrid agent!
Two tracks:
① Showdown Battling – imperfect-info, turn-based strategy
② Pokemon Emerald Speedrunning – long horizon RPG planning
5 M labeled replays • starter kit • baselines.
Bring your LLM, RL, or hybrid agent!

July 14, 2025 at 4:33 PM
🚀 Launch day! The NeurIPS 2025 PokéAgent Challenge is live. @neuripsconf.bsky.social
Two tracks:
① Showdown Battling – imperfect-info, turn-based strategy
② Pokemon Emerald Speedrunning – long horizon RPG planning
5 M labeled replays • starter kit • baselines.
Bring your LLM, RL, or hybrid agent!
Two tracks:
① Showdown Battling – imperfect-info, turn-based strategy
② Pokemon Emerald Speedrunning – long horizon RPG planning
5 M labeled replays • starter kit • baselines.
Bring your LLM, RL, or hybrid agent!
🚀 5 days until my ICML spotlight poster!
Key insights we’ll unpack:
• Base LLM + test-time planning
• Game-theoretic scaffolding
• Context-engineered opponent prediction
• Comparative LLM-as-judge (relative > absolute)
Catch me Thu Jul 17, 4:30-7 PM PT👇
Key insights we’ll unpack:
• Base LLM + test-time planning
• Game-theoretic scaffolding
• Context-engineered opponent prediction
• Comparative LLM-as-judge (relative > absolute)
Catch me Thu Jul 17, 4:30-7 PM PT👇

July 12, 2025 at 6:12 PM
🚀 5 days until my ICML spotlight poster!
Key insights we’ll unpack:
• Base LLM + test-time planning
• Game-theoretic scaffolding
• Context-engineered opponent prediction
• Comparative LLM-as-judge (relative > absolute)
Catch me Thu Jul 17, 4:30-7 PM PT👇
Key insights we’ll unpack:
• Base LLM + test-time planning
• Game-theoretic scaffolding
• Context-engineered opponent prediction
• Comparative LLM-as-judge (relative > absolute)
Catch me Thu Jul 17, 4:30-7 PM PT👇
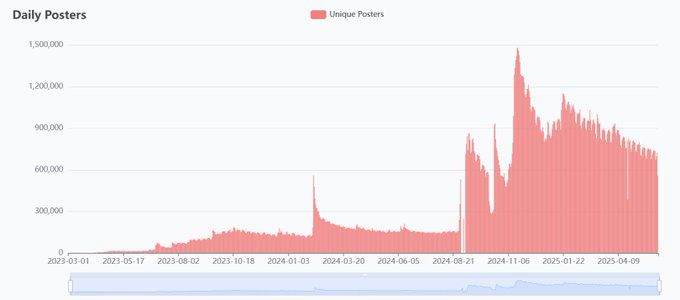
Social media takeoff is hard. Bluesky still lacks the capability to compete with twitter
June 4, 2025 at 5:43 PM
Social media takeoff is hard. Bluesky still lacks the capability to compete with twitter
Excited to announce that I will be spending the summer at @Waymo on the simulation realism team! I’ll be working on learning to generate simulated worlds.
🚙🚙🚙
Send me a message if youre in the bay area and want to chat!
🚙🚙🚙
Send me a message if youre in the bay area and want to chat!

May 30, 2025 at 4:42 PM
Excited to announce that I will be spending the summer at @Waymo on the simulation realism team! I’ll be working on learning to generate simulated worlds.
🚙🚙🚙
Send me a message if youre in the bay area and want to chat!
🚙🚙🚙
Send me a message if youre in the bay area and want to chat!
Excited to share that the PokeAgent challenge was accepted as a NeurIPS competition!
This should serve as an excellent benchmark for competitive games AND ‘speedrunning’ the RPG. I hope to see both the RL and LLM agent communities working together here to eval agents in Pokemon
More info soon👀
This should serve as an excellent benchmark for competitive games AND ‘speedrunning’ the RPG. I hope to see both the RL and LLM agent communities working together here to eval agents in Pokemon
More info soon👀
May 26, 2025 at 7:55 PM
Excited to share that the PokeAgent challenge was accepted as a NeurIPS competition!
This should serve as an excellent benchmark for competitive games AND ‘speedrunning’ the RPG. I hope to see both the RL and LLM agent communities working together here to eval agents in Pokemon
More info soon👀
This should serve as an excellent benchmark for competitive games AND ‘speedrunning’ the RPG. I hope to see both the RL and LLM agent communities working together here to eval agents in Pokemon
More info soon👀
What happens to TRI though? I thought they had an AV division. Also Toyotas arent EVs so I am confused how the driving tech stack would work. I think Waymo is just diversifying their risk into personal vehicles

April 29, 2025 at 11:59 PM
What happens to TRI though? I thought they had an AV division. Also Toyotas arent EVs so I am confused how the driving tech stack would work. I think Waymo is just diversifying their risk into personal vehicles
Insane new study from zurich studies the influence of the LLMs for persuasion on the r/ChangeMyView subreddit. Let's just say people are outraged...
Is the study justified since bots are already rampant on reddit?
Or does this cross ethical lines?
Is the study justified since bots are already rampant on reddit?
Or does this cross ethical lines?

April 28, 2025 at 7:00 PM
Insane new study from zurich studies the influence of the LLMs for persuasion on the r/ChangeMyView subreddit. Let's just say people are outraged...
Is the study justified since bots are already rampant on reddit?
Or does this cross ethical lines?
Is the study justified since bots are already rampant on reddit?
Or does this cross ethical lines?
Stay tuned for our upcoming dataset release (3M+ ranked human games)!

March 7, 2025 at 3:47 PM
Stay tuned for our upcoming dataset release (3M+ ranked human games)!
How does PokéChamp perform in competitive Pokémon battles?
Our agent, powered by GPT-4, achieves a win rate of 84% against Abyssal (best rule-based bot) and a local Elo of 1268, outperforming all baselines, including other LLM-based agents and traditional methods!
Our agent, powered by GPT-4, achieves a win rate of 84% against Abyssal (best rule-based bot) and a local Elo of 1268, outperforming all baselines, including other LLM-based agents and traditional methods!

March 7, 2025 at 3:47 PM
How does PokéChamp perform in competitive Pokémon battles?
Our agent, powered by GPT-4, achieves a win rate of 84% against Abyssal (best rule-based bot) and a local Elo of 1268, outperforming all baselines, including other LLM-based agents and traditional methods!
Our agent, powered by GPT-4, achieves a win rate of 84% against Abyssal (best rule-based bot) and a local Elo of 1268, outperforming all baselines, including other LLM-based agents and traditional methods!
PokéChamp uses an LLM to decide to use one-step lookahead tools for domain-specific calculations (e.g., damage calcs) or a small-scale minimax search enhanced by action sampling, opponent modeling, and value function estimation.
Result: Expert-level play at human speed!
Result: Expert-level play at human speed!

March 7, 2025 at 3:47 PM
PokéChamp uses an LLM to decide to use one-step lookahead tools for domain-specific calculations (e.g., damage calcs) or a small-scale minimax search enhanced by action sampling, opponent modeling, and value function estimation.
Result: Expert-level play at human speed!
Result: Expert-level play at human speed!
Why Pokémon? It's the perfect testbed for LLM agents: constantly changing ruleset, partial observability, and rich strategic depth.
PokéChamp leverages an LLM for action sampling, opponent modeling and value estimation, with no domain-specific training required
PokéChamp leverages an LLM for action sampling, opponent modeling and value estimation, with no domain-specific training required

March 7, 2025 at 3:47 PM
Why Pokémon? It's the perfect testbed for LLM agents: constantly changing ruleset, partial observability, and rich strategic depth.
PokéChamp leverages an LLM for action sampling, opponent modeling and value estimation, with no domain-specific training required
PokéChamp leverages an LLM for action sampling, opponent modeling and value estimation, with no domain-specific training required
Can a Large Language Model (LLM) with zero Pokémon-specific training achieve expert-level performance in competitive Pokémon battles?
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!

March 7, 2025 at 3:47 PM
Can a Large Language Model (LLM) with zero Pokémon-specific training achieve expert-level performance in competitive Pokémon battles?
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!
Introducing PokéChamp, our minimax LLM agent that reaches top 30%-10% human-level Elo on Pokémon Showdown!
New paper on arXiv and code on github!