




Juraj Vladika
@jvladika.bsky.social
PhD student of NLP at TU Munich 🥨🇩🇪
Working on scientific fact verification, LLM factuality, biomedical NLP. 🌐🧑🏻🎓🇭🇷
Working on scientific fact verification, LLM factuality, biomedical NLP. 🌐🧑🏻🎓🇭🇷
Delighted to share "Facts Fade Fast: Evaluating Memorization of Outdated Medical Knowledge in LLMs", accepted to Findings of #EMNLP2025 !🐼
Wit a novel dataset of changed medical knowledge, we discover the alarming presence of obsolete advice in eight popular LLMs.⌛
📝: arxiv.org/abs/2509.04304 #NLP
Wit a novel dataset of changed medical knowledge, we discover the alarming presence of obsolete advice in eight popular LLMs.⌛
📝: arxiv.org/abs/2509.04304 #NLP

September 6, 2025 at 4:29 PM
Delighted to share "Facts Fade Fast: Evaluating Memorization of Outdated Medical Knowledge in LLMs", accepted to Findings of #EMNLP2025 !🐼
Wit a novel dataset of changed medical knowledge, we discover the alarming presence of obsolete advice in eight popular LLMs.⌛
📝: arxiv.org/abs/2509.04304 #NLP
Wit a novel dataset of changed medical knowledge, we discover the alarming presence of obsolete advice in eight popular LLMs.⌛
📝: arxiv.org/abs/2509.04304 #NLP
Also happy to share that “On the Influence of Context Size and Model Choice in RAG Systems” was accepted to Findings of #NAACL2025! 🇺🇸🏜️
We test how the RAG performance on QA tasks changes (and plateaus) with increasing context size across different LLMs and retrievers.
📝 arxiv.org/abs/2502.14759
We test how the RAG performance on QA tasks changes (and plateaus) with increasing context size across different LLMs and retrievers.
📝 arxiv.org/abs/2502.14759

February 23, 2025 at 4:46 PM
Also happy to share that “On the Influence of Context Size and Model Choice in RAG Systems” was accepted to Findings of #NAACL2025! 🇺🇸🏜️
We test how the RAG performance on QA tasks changes (and plateaus) with increasing context size across different LLMs and retrievers.
📝 arxiv.org/abs/2502.14759
We test how the RAG performance on QA tasks changes (and plateaus) with increasing context size across different LLMs and retrievers.
📝 arxiv.org/abs/2502.14759
Thrilled to share that "Step-by-Step Fact Verification for Medical Claims with Explainable Reasoning" was accepted to #NAACL2025! 🇺🇸🏜️
This system iteratively collects new knowledge via generated Q&A pairs, making the verification process more robust and explainable.
📜 arxiv.org/abs/2502.14765 #NLP
This system iteratively collects new knowledge via generated Q&A pairs, making the verification process more robust and explainable.
📜 arxiv.org/abs/2502.14765 #NLP

February 23, 2025 at 4:44 PM
Thrilled to share that "Step-by-Step Fact Verification for Medical Claims with Explainable Reasoning" was accepted to #NAACL2025! 🇺🇸🏜️
This system iteratively collects new knowledge via generated Q&A pairs, making the verification process more robust and explainable.
📜 arxiv.org/abs/2502.14765 #NLP
This system iteratively collects new knowledge via generated Q&A pairs, making the verification process more robust and explainable.
📜 arxiv.org/abs/2502.14765 #NLP
More than 8500 submissions to ACL 2025 (ARR February 2025 cycle)! That is an increase of 3000 submissions compared to ACL 2024. It will be a fun reviewing period. 😅💯
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
February 16, 2025 at 1:19 PM
More than 8500 submissions to ACL 2025 (ARR February 2025 cycle)! That is an increase of 3000 submissions compared to ACL 2024. It will be a fun reviewing period. 😅💯
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
@aclmeeting.bsky.social #ACL2025 #ACL2025nlp #NLP
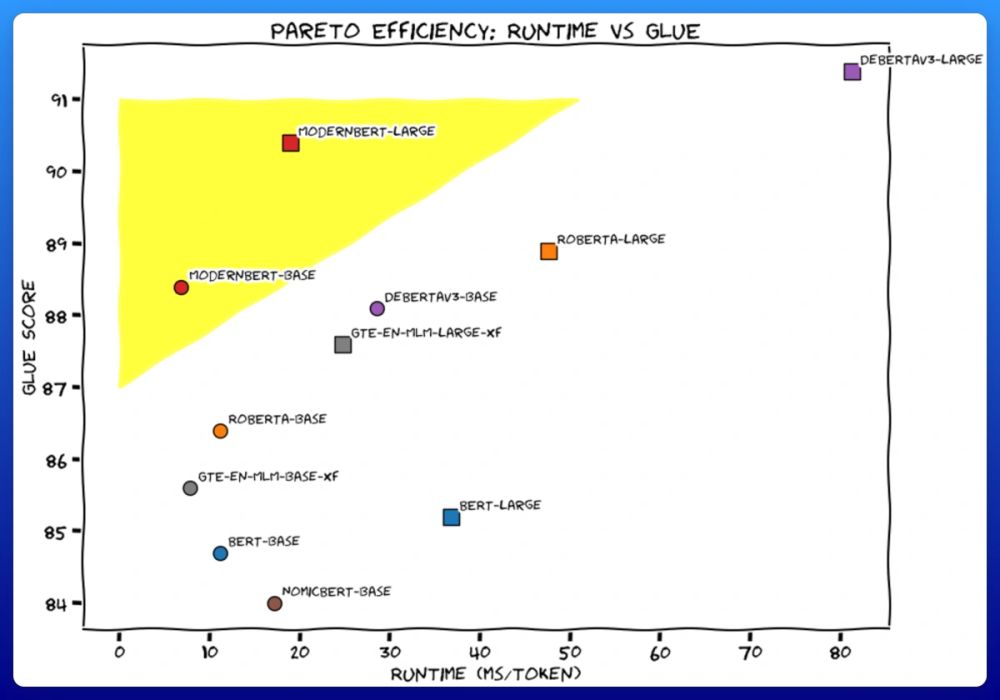
Most exciting update to encoder-only models in a long time! Love to use them for classification tasks where LLMs are an overkill #ModernBERT

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 21, 2024 at 12:29 AM
Most exciting update to encoder-only models in a long time! Love to use them for classification tasks where LLMs are an overkill #ModernBERT
Organizing hackaTUM 2024 was an incredible experience!
Around 1000 participants with 3 days full of intense coding, new experiences, exciting sponsor challenges and workshops, fun side activities, tasty food, creative final solutions, and overall awesome fun! 😊
Join us next year 💙🧑💻🔜 hack.tum.de
Around 1000 participants with 3 days full of intense coding, new experiences, exciting sponsor challenges and workshops, fun side activities, tasty food, creative final solutions, and overall awesome fun! 😊
Join us next year 💙🧑💻🔜 hack.tum.de




November 26, 2024 at 11:06 PM
Organizing hackaTUM 2024 was an incredible experience!
Around 1000 participants with 3 days full of intense coding, new experiences, exciting sponsor challenges and workshops, fun side activities, tasty food, creative final solutions, and overall awesome fun! 😊
Join us next year 💙🧑💻🔜 hack.tum.de
Around 1000 participants with 3 days full of intense coding, new experiences, exciting sponsor challenges and workshops, fun side activities, tasty food, creative final solutions, and overall awesome fun! 😊
Join us next year 💙🧑💻🔜 hack.tum.de
Reposted by Juraj Vladika

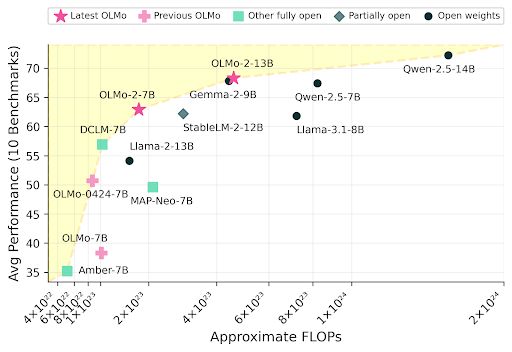
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁