



Anubrata Das @ NAACL 2025
@anubrata.bsky.social
Pinned
Reposted by Anubrata Das @ NAACL 2025

Explainable AI is often assumed to build trust. A study of sonographers estimating gestational age found AI predictions improved accuracy, but explanations did not. In fact, explanations made some clinicians perform worse, highlighting user variability.
#MedSky #MLSky
#MedSky #MLSky

The human factor in explainable artificial intelligence: clinician variability in trust, reliance, and performance - npj Digital Medicine
npj Digital Medicine - The human factor in explainable artificial intelligence: clinician variability in trust, reliance, and performance
www.nature.com
November 14, 2025 at 5:10 PM
Thrilled to be selected for the 🎓 Rising Stars in Data Science Workshop! Grateful to @stanforddata.bsky.social, @HCID UC San Diego, and @dsi-uchicago.bsky.social for this opportunity.
Excited to share my work on trustworthy and collaborative AI and connect with amazing peers and mentors.
🔗 👇
Excited to share my work on trustworthy and collaborative AI and connect with amazing peers and mentors.
🔗 👇

November 7, 2025 at 6:31 PM
Thrilled to be selected for the 🎓 Rising Stars in Data Science Workshop! Grateful to @stanforddata.bsky.social, @HCID UC San Diego, and @dsi-uchicago.bsky.social for this opportunity.
Excited to share my work on trustworthy and collaborative AI and connect with amazing peers and mentors.
🔗 👇
Excited to share my work on trustworthy and collaborative AI and connect with amazing peers and mentors.
🔗 👇
Yes, more so with code for running quick experiments! i definitely want my code to NOT fail gracefully. (And save myself hours of debugging time because there is a default parameter somewhere I did not notice!)

One thing i really hate about ai gen code is the number of safety checks it adds (hasattr(x) for example). like i'd really rather the code just fail and give me (or the agent) a proper error. i assume this is a side effect of the RL objective.
October 24, 2025 at 9:53 PM
Yes, more so with code for running quick experiments! i definitely want my code to NOT fail gracefully. (And save myself hours of debugging time because there is a default parameter somewhere I did not notice!)
Reposted by Anubrata Das @ NAACL 2025

In a stunning moment of self-delusion, the Wall Street Journal headline writers admitted that they don't know how LLM chatbots work.

July 21, 2025 at 1:48 AM
In a stunning moment of self-delusion, the Wall Street Journal headline writers admitted that they don't know how LLM chatbots work.
Reposted by Anubrata Das @ NAACL 2025

What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
July 10, 2025 at 5:26 PM
What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Can content moderation models balance accuracy & fairness?
UT McCombs news featured our iConference paper by Soumyajit Gupta on optimizing the fairness-accuracy tradeoff in toxicity detection. In collaboration with Venelin Kovatchev @mariadearteaga.bsky.social @mattlease.bsky.social
UT McCombs news featured our iConference paper by Soumyajit Gupta on optimizing the fairness-accuracy tradeoff in toxicity detection. In collaboration with Venelin Kovatchev @mariadearteaga.bsky.social @mattlease.bsky.social
June 6, 2025 at 3:06 PM
Can content moderation models balance accuracy & fairness?
UT McCombs news featured our iConference paper by Soumyajit Gupta on optimizing the fairness-accuracy tradeoff in toxicity detection. In collaboration with Venelin Kovatchev @mariadearteaga.bsky.social @mattlease.bsky.social
UT McCombs news featured our iConference paper by Soumyajit Gupta on optimizing the fairness-accuracy tradeoff in toxicity detection. In collaboration with Venelin Kovatchev @mariadearteaga.bsky.social @mattlease.bsky.social
Reposted by Anubrata Das @ NAACL 2025

How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵


June 2, 2025 at 3:42 PM
How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
Please join us for the TrustNLP workshop (215 San Miguel) @naaclmeeting.bsky.social #trustNLP2025
May 3, 2025 at 3:27 PM
Please join us for the TrustNLP workshop (215 San Miguel) @naaclmeeting.bsky.social #trustNLP2025
May 3, 2025 at 3:25 PM
Please join us for the TrustNLP workshop (215 San Miguel) @naaclmeeting.bsky.social #trustNLP2025
Excited to present my internship work at
Amazon AGI at @naaclmeeting.bsky.social tomorrow at 2:00 pm local time. Please come say hi if you are around.
Amazon AGI at @naaclmeeting.bsky.social tomorrow at 2:00 pm local time. Please come say hi if you are around.
May 1, 2025 at 5:21 AM
Excited to present my internship work at
Amazon AGI at @naaclmeeting.bsky.social tomorrow at 2:00 pm local time. Please come say hi if you are around.
Amazon AGI at @naaclmeeting.bsky.social tomorrow at 2:00 pm local time. Please come say hi if you are around.
Reposted by Anubrata Das @ NAACL 2025

thinking of calling this "The Illusion Illusion"
(more examples below)
(more examples below)

December 1, 2024 at 2:33 PM
thinking of calling this "The Illusion Illusion"
(more examples below)
(more examples below)
Reposted by Anubrata Das @ NAACL 2025

Created a small starter pack including folks whose work I believe contributes to more rigorous and grounded AI research -- I'll grow this slowly and likely move it to a list at some point :) go.bsky.app/P86UbQw
November 30, 2024 at 7:58 PM
Created a small starter pack including folks whose work I believe contributes to more rigorous and grounded AI research -- I'll grow this slowly and likely move it to a list at some point :) go.bsky.app/P86UbQw
Reposted by Anubrata Das @ NAACL 2025

NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
November 27, 2024 at 5:32 PM
NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Reposted by Anubrata Das @ NAACL 2025

@tomcostello.bsky.social 's Qualitrics materials and tutorial video for integrating LLMs into Qualtrics can be accessed at publish.obsidian.md/qualtrics-do...

Home - Obsidian Publish
Request If you use our template (.QSF) to set up your research, we would appreciate it if you cite our paper when describing your method: Durably reducing conspiracy beliefs through dialogues with AI…
publish.obsidian.md
November 25, 2024 at 3:40 PM
@tomcostello.bsky.social 's Qualitrics materials and tutorial video for integrating LLMs into Qualtrics can be accessed at publish.obsidian.md/qualtrics-do...
Reposted by Anubrata Das @ NAACL 2025
I did a starter pack of ML/AI people at @utaustin.bsky.social Please distribute and feel free to self nominate!
go.bsky.app/QLQznZg
go.bsky.app/QLQznZg
November 22, 2024 at 9:25 AM
I did a starter pack of ML/AI people at @utaustin.bsky.social Please distribute and feel free to self nominate!
go.bsky.app/QLQznZg
go.bsky.app/QLQznZg
Reposted by Anubrata Das @ NAACL 2025

A starter pack for the NLP and Computational Linguistics researchers at UT Austin!
go.bsky.app/75g9JLT
go.bsky.app/75g9JLT

NLP at UT Austin
Join the conversation
go.bsky.app
November 22, 2024 at 5:18 PM
A starter pack for the NLP and Computational Linguistics researchers at UT Austin!
go.bsky.app/75g9JLT
go.bsky.app/75g9JLT
Reposted by Anubrata Das @ NAACL 2025
Ok, I am so excited about this!
I built a new algorithmic ranked feed based off my starter pack, and did it on skyfeed.app
I'm probably going to tweak mine a bit, if you wanted a ranked feed of the best post from a selected list of followers, here is how you can do it. 1/8🧵
🧪 🩺🖥️ 🛟 #AcademicSky
I built a new algorithmic ranked feed based off my starter pack, and did it on skyfeed.app
I'm probably going to tweak mine a bit, if you wanted a ranked feed of the best post from a selected list of followers, here is how you can do it. 1/8🧵
🧪 🩺🖥️ 🛟 #AcademicSky
November 20, 2024 at 4:24 PM
Ok, I am so excited about this!
I built a new algorithmic ranked feed based off my starter pack, and did it on skyfeed.app
I'm probably going to tweak mine a bit, if you wanted a ranked feed of the best post from a selected list of followers, here is how you can do it. 1/8🧵
🧪 🩺🖥️ 🛟 #AcademicSky
I built a new algorithmic ranked feed based off my starter pack, and did it on skyfeed.app
I'm probably going to tweak mine a bit, if you wanted a ranked feed of the best post from a selected list of followers, here is how you can do it. 1/8🧵
🧪 🩺🖥️ 🛟 #AcademicSky
Reposted by Anubrata Das @ NAACL 2025

We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2025! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: t.co/OPrxO3yMhf
Learn more & apply: t.co/OPrxO3yMhf
http://tinyurl.com/use-inspired-ai-f25
t.co
November 20, 2024 at 8:43 PM
We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2025! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: t.co/OPrxO3yMhf
Learn more & apply: t.co/OPrxO3yMhf
Reposted by Anubrata Das @ NAACL 2025

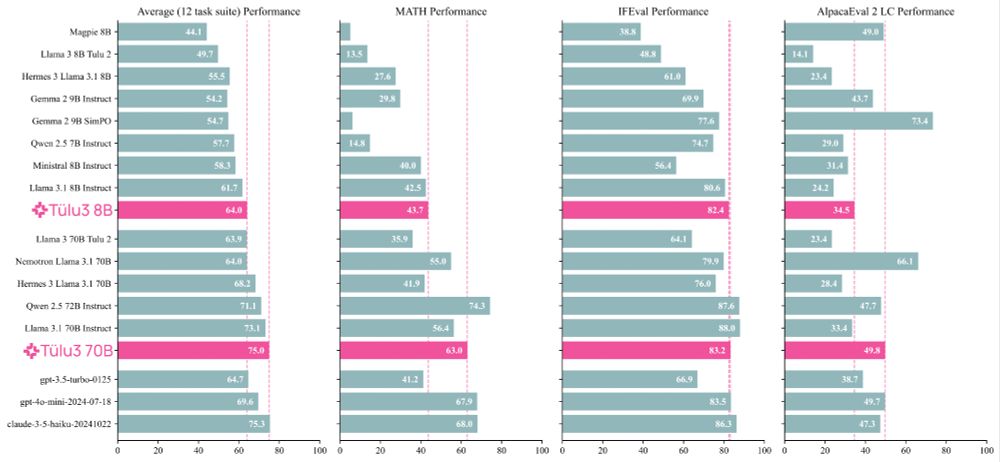
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
November 21, 2024 at 5:15 PM
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
Reposted by Anubrata Das @ NAACL 2025

“Explainable to whom?” is the elephant in the room for every Explainable AI (XAI) system.
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n

November 20, 2024 at 11:26 PM
“Explainable to whom?” is the elephant in the room for every Explainable AI (XAI) system.
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n
“Explainable to whom?” is the elephant in the room for every Explainable AI (XAI) system.
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n
Turns out, your AI background defines how you see explanations--and it's risker than you think.
Our #CHI2024 paper on "The Who in XAI" explains why & how.
Findings at a glance ⤵️
#academicSky
🧵1/n
November 21, 2024 at 12:29 AM
Reposted by Anubrata Das @ NAACL 2025

November 14, 2024 at 5:16 PM
Reposted by Anubrata Das @ NAACL 2025

Simulating human behavior with AI agents promises a testbed for policy and the social sciences. We interviewed 1,000 people for two hours each to create generative agents of them. These agents replicate their source individuals’ attitudes and behaviors. 🧵
arxiv.org/abs/2411.10109
arxiv.org/abs/2411.10109

November 18, 2024 at 5:22 PM
Simulating human behavior with AI agents promises a testbed for policy and the social sciences. We interviewed 1,000 people for two hours each to create generative agents of them. These agents replicate their source individuals’ attitudes and behaviors. 🧵
arxiv.org/abs/2411.10109
arxiv.org/abs/2411.10109
Reposted by Anubrata Das @ NAACL 2025

I'm sharing materials from my academic job search last year! Includes research, teaching, and diversity statements, plus my UMD cover letter and job talk slides. I applied for a mix of iSchool, data sci, CS, and linguistics positions). Feel free to share!
juliamendelsohn.github.io/resources/
juliamendelsohn.github.io/resources/
resources | Julia Mendelsohn
Materials that some people might find helpful
juliamendelsohn.github.io
November 18, 2024 at 4:00 PM
I'm sharing materials from my academic job search last year! Includes research, teaching, and diversity statements, plus my UMD cover letter and job talk slides. I applied for a mix of iSchool, data sci, CS, and linguistics positions). Feel free to share!
juliamendelsohn.github.io/resources/
juliamendelsohn.github.io/resources/
Reposted by Anubrata Das @ NAACL 2025

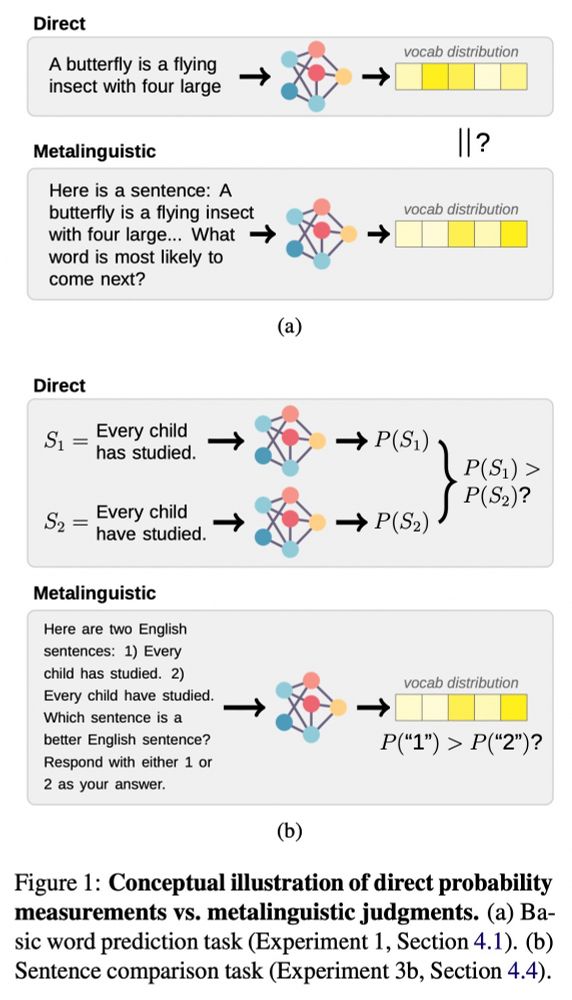
To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
October 24, 2023 at 3:03 PM
To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...