



Pinned
Anton
@anton-l.bsky.social
· Dec 19
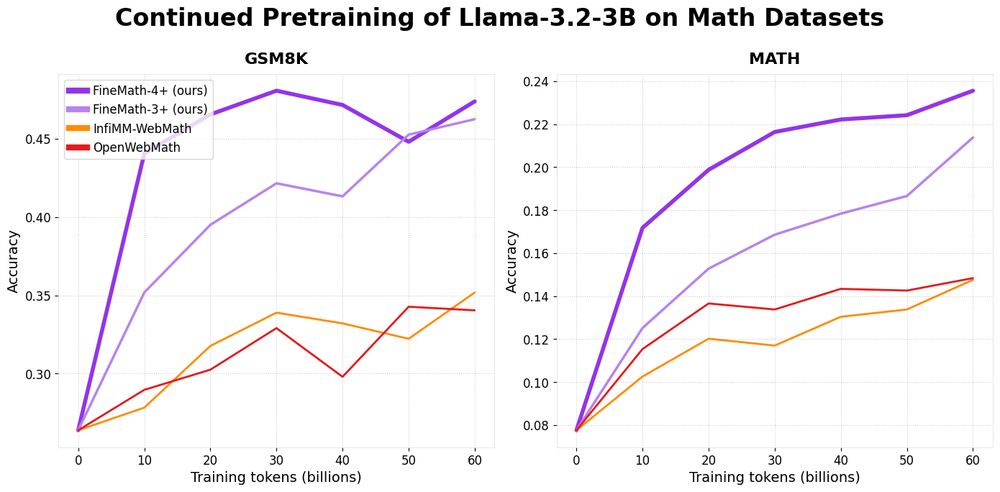
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
LLM Reasoning labs will be eating good today🍔
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
February 12, 2025 at 2:36 PM
LLM Reasoning labs will be eating good today🍔
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
Reposted by Anton
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
December 19, 2024 at 3:55 PM
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
December 19, 2024 at 3:55 PM
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Reposted by Anton

The Open LLM Leaderboard got a new front page for Christmas
Check it out at huggingface.co/spaces/open-...
Check it out at huggingface.co/spaces/open-...

December 11, 2024 at 8:16 AM
The Open LLM Leaderboard got a new front page for Christmas
Check it out at huggingface.co/spaces/open-...
Check it out at huggingface.co/spaces/open-...
Reposted by Anton

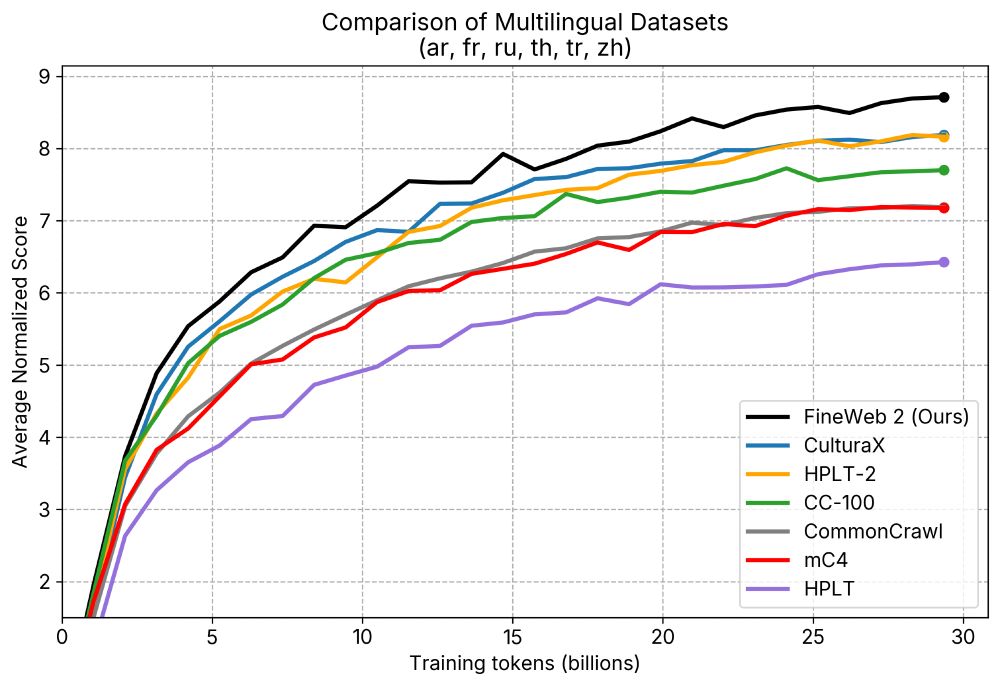
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
December 8, 2024 at 9:19 AM
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
Reposted by Anton

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Reposted by Anton

Small yet mighty! 💫
We are releasing SmolVLM: a new 2B small vision language made for on-device use, fine-tunable on consumer GPU, immensely memory efficient 🤠
We release three checkpoints under Apache 2.0: SmolVLM-Instruct, SmolVLM-Synthetic and SmolVLM-Base huggingface.co/collections/...
We are releasing SmolVLM: a new 2B small vision language made for on-device use, fine-tunable on consumer GPU, immensely memory efficient 🤠
We release three checkpoints under Apache 2.0: SmolVLM-Instruct, SmolVLM-Synthetic and SmolVLM-Base huggingface.co/collections/...

November 26, 2024 at 4:04 PM
Small yet mighty! 💫
We are releasing SmolVLM: a new 2B small vision language made for on-device use, fine-tunable on consumer GPU, immensely memory efficient 🤠
We release three checkpoints under Apache 2.0: SmolVLM-Instruct, SmolVLM-Synthetic and SmolVLM-Base huggingface.co/collections/...
We are releasing SmolVLM: a new 2B small vision language made for on-device use, fine-tunable on consumer GPU, immensely memory efficient 🤠
We release three checkpoints under Apache 2.0: SmolVLM-Instruct, SmolVLM-Synthetic and SmolVLM-Base huggingface.co/collections/...
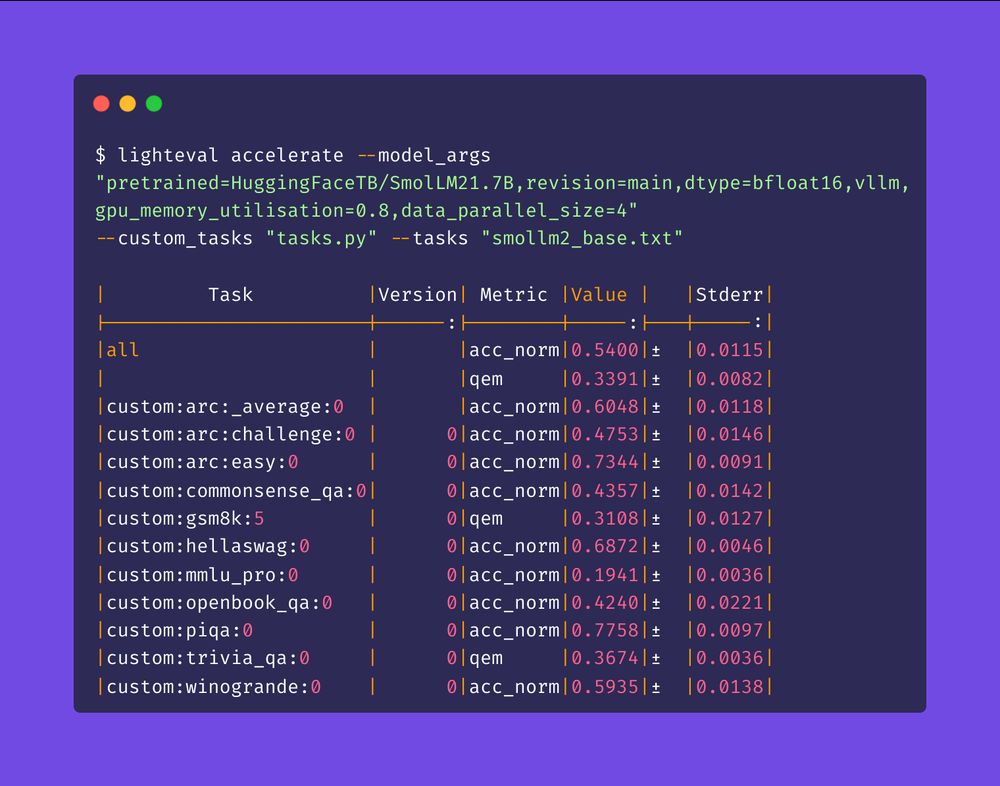
Check out how easy it is to do LLM evals with LightEval!
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
November 25, 2024 at 5:24 PM
Check out how easy it is to do LLM evals with LightEval!
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
Reposted by Anton

Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
Everything about the SmolLM & SmolLM2 family of models - GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
github.com
November 24, 2024 at 7:16 AM
Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Reposted by Anton

Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...

HuggingFaceTB/smoltalk · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 21, 2024 at 3:22 PM
Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
10x followers in the past week, I guess it's happening!
November 15, 2024 at 2:54 PM
10x followers in the past week, I guess it's happening!