




Anka Reuel ➡️ NeurIPS
@ankareuel.bsky.social
Computer Science PhD Student @ Stanford | Geopolitics & Technology Fellow @ Harvard Kennedy School/Belfer | Vice Chair EU AI Code of Practice | Views are my own
Reposted by Anka Reuel ➡️ NeurIPS

🚨New paper:
Current reports on AI audits/evals often omit crucial details, and there are huge disparities between the thoroughness of different reports. Even technically rigorous evals can offer little useful insight if reported selectively or obscurely.
Audit cards can help.
Current reports on AI audits/evals often omit crucial details, and there are huge disparities between the thoroughness of different reports. Even technically rigorous evals can offer little useful insight if reported selectively or obscurely.
Audit cards can help.

April 21, 2025 at 5:11 PM
🚨New paper:
Current reports on AI audits/evals often omit crucial details, and there are huge disparities between the thoroughness of different reports. Even technically rigorous evals can offer little useful insight if reported selectively or obscurely.
Audit cards can help.
Current reports on AI audits/evals often omit crucial details, and there are huge disparities between the thoroughness of different reports. Even technically rigorous evals can offer little useful insight if reported selectively or obscurely.
Audit cards can help.
Reposted by Anka Reuel ➡️ NeurIPS

A recent Stanford paper reveals that many popular AI benchmarks are fundamentally flawed: They can be outdated, easily gamed, or inaccurate. Stanford HAI Graduate Fellow
@ankareuel.bsky.social talks about how researchers are rethinking AI benchmarks: www.emergingtechbrew.com/stories/2025...
@ankareuel.bsky.social talks about how researchers are rethinking AI benchmarks: www.emergingtechbrew.com/stories/2025...
Some researchers are rethinking how to measure AI intelligence
Current popular benchmarks are often inadequate or too easy to game, experts say.
www.emergingtechbrew.com
March 25, 2025 at 9:26 PM
A recent Stanford paper reveals that many popular AI benchmarks are fundamentally flawed: They can be outdated, easily gamed, or inaccurate. Stanford HAI Graduate Fellow
@ankareuel.bsky.social talks about how researchers are rethinking AI benchmarks: www.emergingtechbrew.com/stories/2025...
@ankareuel.bsky.social talks about how researchers are rethinking AI benchmarks: www.emergingtechbrew.com/stories/2025...
Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
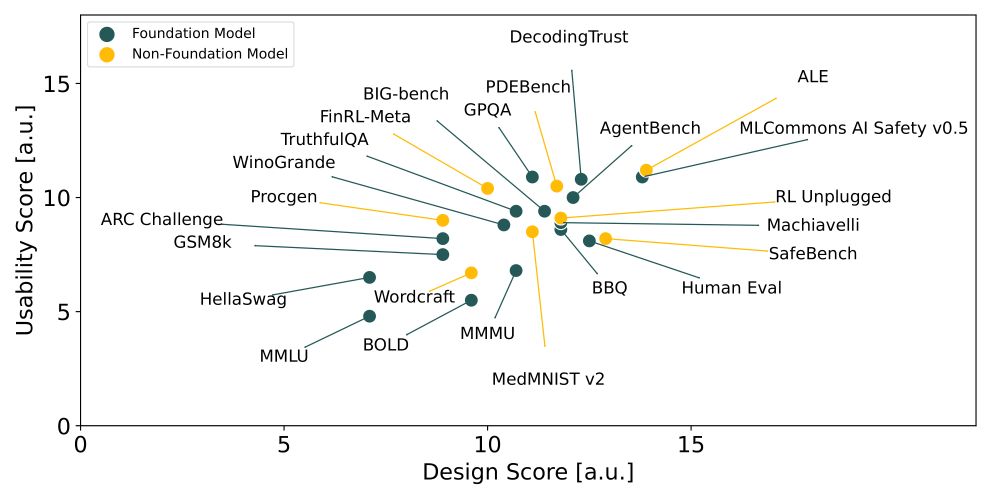
January 27, 2025 at 10:02 PM
Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
📢 Excited to share: I'm again leading the efforts for the Responsible AI chapter for Stanford's 2025 AI Index, curated by @stanfordhai.bsky.social. As last year, we're asking you to submit your favorite papers on the topic for consideration (including your own!) 🧵 1/
January 5, 2025 at 5:42 PM
📢 Excited to share: I'm again leading the efforts for the Responsible AI chapter for Stanford's 2025 AI Index, curated by @stanfordhai.bsky.social. As last year, we're asking you to submit your favorite papers on the topic for consideration (including your own!) 🧵 1/
I‘m teaching my first own course starting next week (Intro to AI Governance at Stanford). Super proud but also nervous 🥹 Any advice from more seasoned instructors? 😬 #AcademicTwitter #AcademicChatter #TeachingTips #AcademicAdvice
January 4, 2025 at 3:14 AM
I‘m teaching my first own course starting next week (Intro to AI Governance at Stanford). Super proud but also nervous 🥹 Any advice from more seasoned instructors? 😬 #AcademicTwitter #AcademicChatter #TeachingTips #AcademicAdvice
Reposted by Anka Reuel ➡️ NeurIPS

The regular reminder of my starter packs full of amazing folks / accounts to follow. I am trying to keep them up to date but let me know if I missed you.
I have updated my starter packs with lots of follow-worthy accounts since I last shared them. Take a look and follow generously! #PrivacySky #ResponsibleAI
Privacy and security part 1: go.bsky.app/6ApBSmA
Privacy and security part 1: go.bsky.app/6ApBSmA
December 24, 2024 at 8:28 AM
The regular reminder of my starter packs full of amazing folks / accounts to follow. I am trying to keep them up to date but let me know if I missed you.
As one of the vice chairs of the EU GPAI Code of Practice process, I co-wrote the second draft which just went online – feedback is open until mid-January, please let me know your thoughts, especially on the internal governance section!
digital-strategy.ec.europa.eu/en/library/s...
digital-strategy.ec.europa.eu/en/library/s...
Second Draft of the General-Purpose AI Code of Practice published, written by independent experts
Independent experts present the second draft of the General-Purpose AI Code of Practice, based on the feedback received on the first draft, published on 14 November 2024.
digital-strategy.ec.europa.eu
December 19, 2024 at 4:59 PM
As one of the vice chairs of the EU GPAI Code of Practice process, I co-wrote the second draft which just went online – feedback is open until mid-January, please let me know your thoughts, especially on the internal governance section!
digital-strategy.ec.europa.eu/en/library/s...
digital-strategy.ec.europa.eu/en/library/s...
Reposted by Anka Reuel ➡️ NeurIPS
In our latest brief, Stanford scholars present a novel assessment framework for evaluating the quality of AI benchmarks and share best practices for minimum quality assurance. @ankareuel.bsky.social @chansmi.bsky.social @mlamparth.bsky.social hai.stanford.edu/what-makes-g...

December 11, 2024 at 6:08 PM
In our latest brief, Stanford scholars present a novel assessment framework for evaluating the quality of AI benchmarks and share best practices for minimum quality assurance. @ankareuel.bsky.social @chansmi.bsky.social @mlamparth.bsky.social hai.stanford.edu/what-makes-g...
Come join us! 😊

Interested in how LLMs are really used?
We are starting a research project to find out! In collaboration w/ @sarahooker.bsky.social @ankareuel.bsky.social and others.
We are looking for two junior researchers to join us. Apply by Dec 15th!
forms.gle/H2o3cNCPdG8e...
We are starting a research project to find out! In collaboration w/ @sarahooker.bsky.social @ankareuel.bsky.social and others.
We are looking for two junior researchers to join us. Apply by Dec 15th!
forms.gle/H2o3cNCPdG8e...
Google Forms: Sign-in
Access Google Forms with a personal Google account or Google Workspace account (for business use).
forms.gle
December 5, 2024 at 3:49 PM
Come join us! 😊
You know it’s been a busy day when you realize, when taking out the trash, that that was literally the first time today you’ve stepped outside your house and away from your laptop🥲 (I love my work but time for a little unfiltered sunshine would’ve been great ☀️)
December 5, 2024 at 5:57 AM
You know it’s been a busy day when you realize, when taking out the trash, that that was literally the first time today you’ve stepped outside your house and away from your laptop🥲 (I love my work but time for a little unfiltered sunshine would’ve been great ☀️)
Reposted by Anka Reuel ➡️ NeurIPS
I’ll be at @neuripsconf.bsky.social in Vancouver from Dec 9 to Dec 15. Hit me up if you want to talk (non-)technical AI governance, science of evals, BetterBench, or just grab a coffee ☕️ #neurips2024
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
December 1, 2024 at 2:32 AM
I’ll be at @neuripsconf.bsky.social in Vancouver from Dec 9 to Dec 15. Hit me up if you want to talk (non-)technical AI governance, science of evals, BetterBench, or just grab a coffee ☕️ #neurips2024
I’ll be at @neuripsconf.bsky.social in Vancouver from Dec 9 to Dec 15. Hit me up if you want to talk (non-)technical AI governance, science of evals, BetterBench, or just grab a coffee ☕️ #neurips2024
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
December 1, 2024 at 2:32 AM
I’ll be at @neuripsconf.bsky.social in Vancouver from Dec 9 to Dec 15. Hit me up if you want to talk (non-)technical AI governance, science of evals, BetterBench, or just grab a coffee ☕️ #neurips2024
Reposted by Anka Reuel ➡️ NeurIPS

Stellar work by some of the most promising young scholars I know of. Must read (and watch at Neurips).
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
November 25, 2024 at 8:48 PM
Stellar work by some of the most promising young scholars I know of. Must read (and watch at Neurips).
Does anyone know of any empirical studies of the actual impact of AI or AI-generated (mis-)information on elections? (Doesn’t have to be US-focused, any election would be great). Thanks!
November 30, 2024 at 1:14 AM
Does anyone know of any empirical studies of the actual impact of AI or AI-generated (mis-)information on elections? (Doesn’t have to be US-focused, any election would be great). Thanks!
Reposted by Anka Reuel ➡️ NeurIPS

NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
November 27, 2024 at 5:32 PM
NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Reposted by Anka Reuel ➡️ NeurIPS

New MIT Tech Review article about our recent NeurIPS spotlight paper on how to measure and improve benchmark quality aspects! Great collaboration with
@ankareuel.bsky.social, Amelia Hardy,
@chansmi.bsky.social, Malcolm Hardy, and
Mykel Kochenderfer.
www.technologyreview.com/2024/11/26/1...
@ankareuel.bsky.social, Amelia Hardy,
@chansmi.bsky.social, Malcolm Hardy, and
Mykel Kochenderfer.
www.technologyreview.com/2024/11/26/1...

The way we measure progress in AI is terrible
Many of the most popular benchmarks for AI models are outdated or poorly designed.
www.technologyreview.com
November 26, 2024 at 7:55 PM
New MIT Tech Review article about our recent NeurIPS spotlight paper on how to measure and improve benchmark quality aspects! Great collaboration with
@ankareuel.bsky.social, Amelia Hardy,
@chansmi.bsky.social, Malcolm Hardy, and
Mykel Kochenderfer.
www.technologyreview.com/2024/11/26/1...
@ankareuel.bsky.social, Amelia Hardy,
@chansmi.bsky.social, Malcolm Hardy, and
Mykel Kochenderfer.
www.technologyreview.com/2024/11/26/1...
Thrilled our NeurIPS Spotlight paper BetterBench is featured by MIT @technologyreview.com! 🎉
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️

Many of the most popular benchmarks for AI models are outdated or poorly designed.

The way we measure progress in AI is terrible
Many of the most popular benchmarks for AI models are outdated or poorly designed.
www.technologyreview.com
November 26, 2024 at 5:12 PM
Thrilled our NeurIPS Spotlight paper BetterBench is featured by MIT @technologyreview.com! 🎉
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️
Article: bit.ly/3Zo1rgw
Paper: bit.ly/4eMSZfw
Website & Scores: betterbench.stanford.edu
Please share widely & join us in setting new standards for better AI benchmarking! ❤️
Okay, I’m convinced, 🦋 is better. Just need to find all my favorite AI governance people here now. Can you tag yourself or accounts worth following on everything AI governance? Thanks ❤️
November 26, 2024 at 4:46 AM
Okay, I’m convinced, 🦋 is better. Just need to find all my favorite AI governance people here now. Can you tag yourself or accounts worth following on everything AI governance? Thanks ❤️
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
November 25, 2024 at 7:02 PM
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x