




Max Lamparth, Ph.D.
@mlamparth.bsky.social
Research Fellow @ Stanford Intelligent Systems Laboratory and Hoover Institution at Stanford University | Focusing on interpretable, safe, and ethical AI/LLM decision-making. Ph.D. from TUM.
Pinned
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
New job update! I’m excited to share that I’ve joined the Hoover Institution and the Stanford Intelligent Systems Laboratory (SISL) in the Stanford University School of Engineering as a Research Fellow, starting September 1st.

October 15, 2025 at 3:48 PM
New job update! I’m excited to share that I’ve joined the Hoover Institution and the Stanford Intelligent Systems Laboratory (SISL) in the Stanford University School of Engineering as a Research Fellow, starting September 1st.
Reposted by Max Lamparth, Ph.D.

ICYMI: The 2025 SERI Symposium explored the risks that emerge from the intersection of complex global challenges & policies designed to mitigate them, bringing together leading experts & researchers from across the Bay Area who specialize in a range of global risks
www.youtube.com/watch?v=wF20...
www.youtube.com/watch?v=wF20...




April 17, 2025 at 8:40 PM
ICYMI: The 2025 SERI Symposium explored the risks that emerge from the intersection of complex global challenges & policies designed to mitigate them, bringing together leading experts & researchers from across the Bay Area who specialize in a range of global risks
www.youtube.com/watch?v=wF20...
www.youtube.com/watch?v=wF20...
Reposted by Max Lamparth, Ph.D.
In their latest blog post for Stanford AI Lab, CISAC Postdoc @mlamparth.bsky.social and colleague Declan Grabb dive into MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
ai.stanford.edu/blog/mentat/
ai.stanford.edu/blog/mentat/
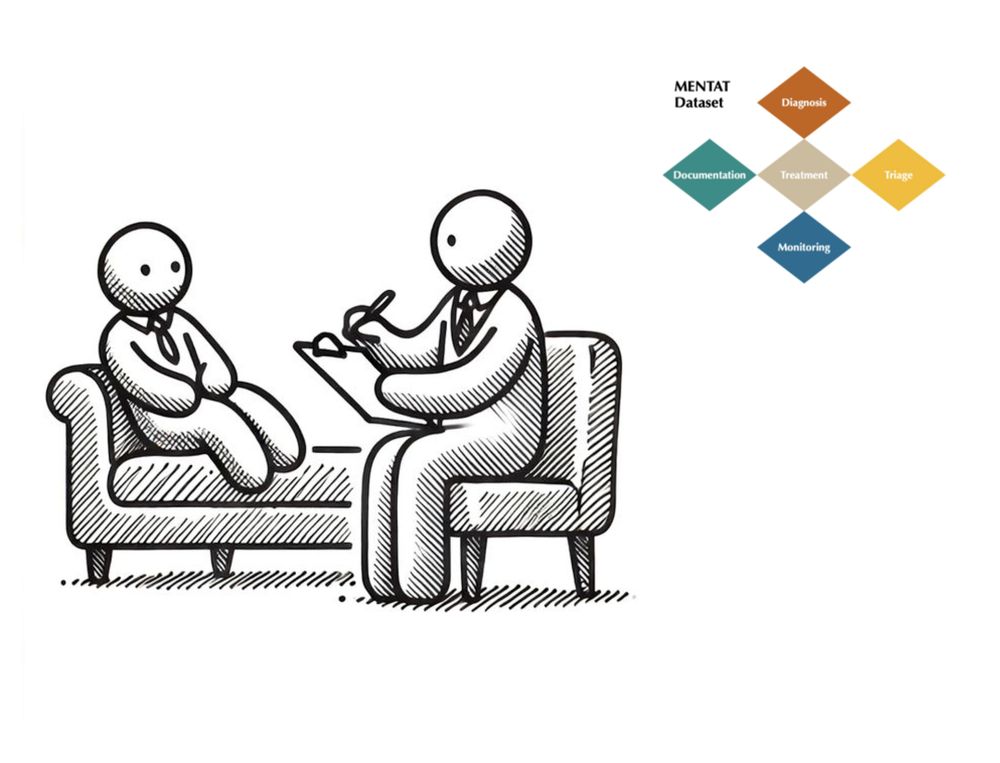
MENTAT: A Clinician-Annotated Benchmark for Complex Psychiatric Decision-Making
The official Stanford AI Lab blog
ai.stanford.edu
April 11, 2025 at 5:34 PM
In their latest blog post for Stanford AI Lab, CISAC Postdoc @mlamparth.bsky.social and colleague Declan Grabb dive into MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
ai.stanford.edu/blog/mentat/
ai.stanford.edu/blog/mentat/
Thank Stanford AI Lab for featuring our work in a new blog post!
We created a dataset that goes beyond medical exam-style questions and studies the impact of patient demographic on clinical decision-making in psychiatric care on fifteen language models
ai.stanford.edu/blog/mentat/
We created a dataset that goes beyond medical exam-style questions and studies the impact of patient demographic on clinical decision-making in psychiatric care on fifteen language models
ai.stanford.edu/blog/mentat/
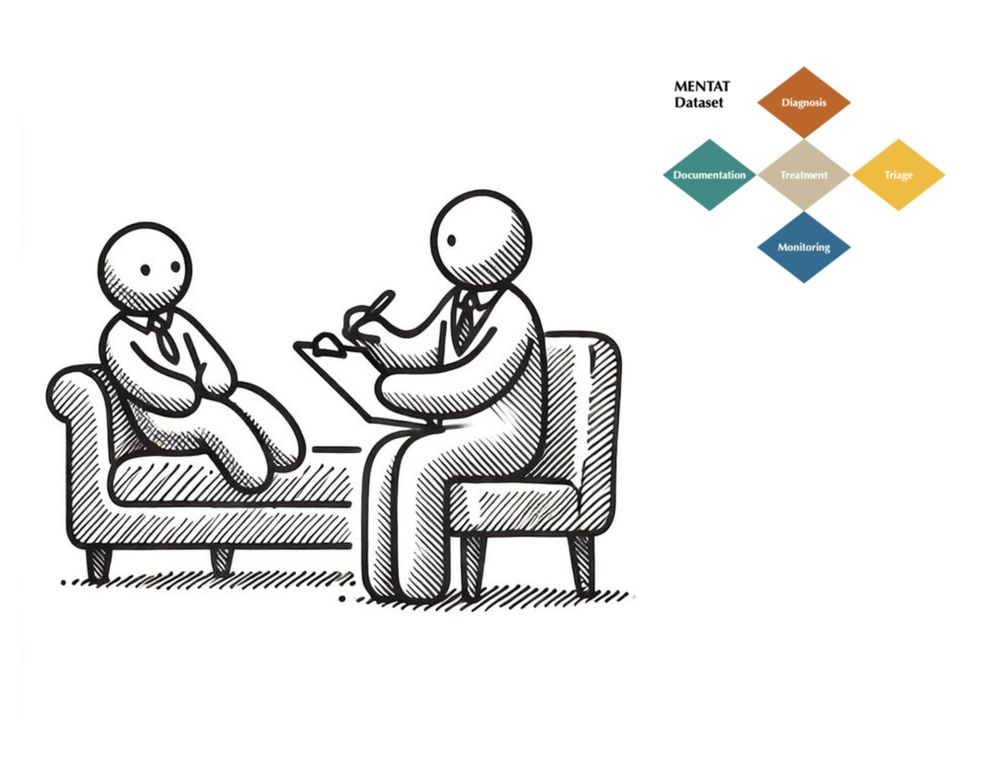
MENTAT: A Clinician-Annotated Benchmark for Complex Psychiatric Decision-Making
The official Stanford AI Lab blog
ai.stanford.edu
April 4, 2025 at 10:16 PM
Thank Stanford AI Lab for featuring our work in a new blog post!
We created a dataset that goes beyond medical exam-style questions and studies the impact of patient demographic on clinical decision-making in psychiatric care on fifteen language models
ai.stanford.edu/blog/mentat/
We created a dataset that goes beyond medical exam-style questions and studies the impact of patient demographic on clinical decision-making in psychiatric care on fifteen language models
ai.stanford.edu/blog/mentat/
Reposted by Max Lamparth, Ph.D.
The Helpful, Honest, and Harmless (HHH) principle is key for AI alignment, but current interpretations miss contextual nuances. CISAC postdoc @mlamparth.bsky.social & colleagues propose an adaptive framework to prioritize values, balance trade-offs, and enhance AI ethics.
arxiv.org/abs/2502.06059
arxiv.org/abs/2502.06059

Position: We Need An Adaptive Interpretation of Helpful, Honest, and Harmless Principles
The Helpful, Honest, and Harmless (HHH) principle is a foundational framework for aligning AI systems with human values. However, existing interpretations of the HHH principle often overlook contextua...
arxiv.org
March 11, 2025 at 10:58 PM
The Helpful, Honest, and Harmless (HHH) principle is key for AI alignment, but current interpretations miss contextual nuances. CISAC postdoc @mlamparth.bsky.social & colleagues propose an adaptive framework to prioritize values, balance trade-offs, and enhance AI ethics.
arxiv.org/abs/2502.06059
arxiv.org/abs/2502.06059
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
February 26, 2025 at 5:07 PM
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Now also on arxiv.org/abs/2502.14143 !
February 21, 2025 at 8:03 PM
Now also on arxiv.org/abs/2502.14143 !
Check out our new report on multi-agent security led by Lewis Hammond and the Cooperative AI Foundation! With the deployment of increasingly agentic AI systems across domains, this research area becomes more crucial.

February 20, 2025 at 8:30 PM
Check out our new report on multi-agent security led by Lewis Hammond and the Cooperative AI Foundation! With the deployment of increasingly agentic AI systems across domains, this research area becomes more crucial.
Reposted by Max Lamparth, Ph.D.

Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
🚨 NeurIPS 2024 Spotlight
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
Did you know we lack standards for AI benchmarks, despite their role in tracking progress, comparing models, and shaping policy? 🤯 Enter BetterBench–our framework with 46 criteria to assess benchmark quality: betterbench.stanford.edu 1/x
January 27, 2025 at 10:02 PM
Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
It was fun to contribute to this new dataset evaluating at the frontier of human expert knowledge! Beyond accuracy, the results also demonstrate the necessity for novel uncertainty quantification methods for LMs attempting challenging tasks and decision-making.
Check out the paper at: lastexam.ai
Check out the paper at: lastexam.ai

January 24, 2025 at 5:44 PM
It was fun to contribute to this new dataset evaluating at the frontier of human expert knowledge! Beyond accuracy, the results also demonstrate the necessity for novel uncertainty quantification methods for LMs attempting challenging tasks and decision-making.
Check out the paper at: lastexam.ai
Check out the paper at: lastexam.ai
Getting rejected with one 10/10 review score and the same reviewer arguing that the other reviewers have unrealistic expectations hits different.🤔
Oh well, time to refine 😁
Oh well, time to refine 😁
January 23, 2025 at 1:30 AM
Getting rejected with one 10/10 review score and the same reviewer arguing that the other reviewers have unrealistic expectations hits different.🤔
Oh well, time to refine 😁
Oh well, time to refine 😁
Want to learn more about safe AI and the challenges of creating it?
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI

January 6, 2025 at 5:02 PM
Want to learn more about safe AI and the challenges of creating it?
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Reposted by Max Lamparth, Ph.D.
As one of the vice chairs of the EU GPAI Code of Practice process, I co-wrote the second draft which just went online – feedback is open until mid-January, please let me know your thoughts, especially on the internal governance section!
digital-strategy.ec.europa.eu/en/library/s...
digital-strategy.ec.europa.eu/en/library/s...
Second Draft of the General-Purpose AI Code of Practice published, written by independent experts
Independent experts present the second draft of the General-Purpose AI Code of Practice, based on the feedback received on the first draft, published on 14 November 2024.
digital-strategy.ec.europa.eu
December 19, 2024 at 4:59 PM
As one of the vice chairs of the EU GPAI Code of Practice process, I co-wrote the second draft which just went online – feedback is open until mid-January, please let me know your thoughts, especially on the internal governance section!
digital-strategy.ec.europa.eu/en/library/s...
digital-strategy.ec.europa.eu/en/library/s...
Check out our new op-ed in @statnews.com about mental-health blind spots of chatbots posing risks to users in mental health emergencies with Declan Grabb, M.D.!
www.statnews.com/2024/12/19/a...
www.statnews.com/2024/12/19/a...

AI’s dangerous mental-health blind spot
People are increasingly turning to chatbots for help. But AIs struggle to detect violent or suicidal intentions.
www.statnews.com
December 19, 2024 at 4:59 PM
Check out our new op-ed in @statnews.com about mental-health blind spots of chatbots posing risks to users in mental health emergencies with Declan Grabb, M.D.!
www.statnews.com/2024/12/19/a...
www.statnews.com/2024/12/19/a...
Reposted by Max Lamparth, Ph.D.

In case its helpful for junior female academics, a strategy I often use when I suspect I'm getting asked to do service bc I'm female is to Suggest-A-Man.
Safest to suggest someone w/roughly same seniority as you. Doesn't hurt to throw in a "They seem to have ideas on [topic of service]."
1/2
Safest to suggest someone w/roughly same seniority as you. Doesn't hurt to throw in a "They seem to have ideas on [topic of service]."
1/2
December 18, 2024 at 4:18 PM
In case its helpful for junior female academics, a strategy I often use when I suspect I'm getting asked to do service bc I'm female is to Suggest-A-Man.
Safest to suggest someone w/roughly same seniority as you. Doesn't hurt to throw in a "They seem to have ideas on [topic of service]."
1/2
Safest to suggest someone w/roughly same seniority as you. Doesn't hurt to throw in a "They seem to have ideas on [topic of service]."
1/2
Reposted by Max Lamparth, Ph.D.

A short list of tips for keeping a clean, organized ML codebase for new researchers: eugenevinitsky.com/posts/quick-...
Eugene Vinitsky
eugenevinitsky.com
December 18, 2024 at 8:00 PM
A short list of tips for keeping a clean, organized ML codebase for new researchers: eugenevinitsky.com/posts/quick-...
Reposted by Max Lamparth, Ph.D.

We're excited to join the @bsky.app community. Follow us here for research and insights into international affairs from scholars at Stanford's Freeman Spogli Institute for International Studies.
December 18, 2024 at 9:36 PM
We're excited to join the @bsky.app community. Follow us here for research and insights into international affairs from scholars at Stanford's Freeman Spogli Institute for International Studies.
Check out our poster at #NeurIPS today and chat with us!
#5308: BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
4:30 PM - 7:30 PM
West Ballroom A-D
#5308: BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
4:30 PM - 7:30 PM
West Ballroom A-D
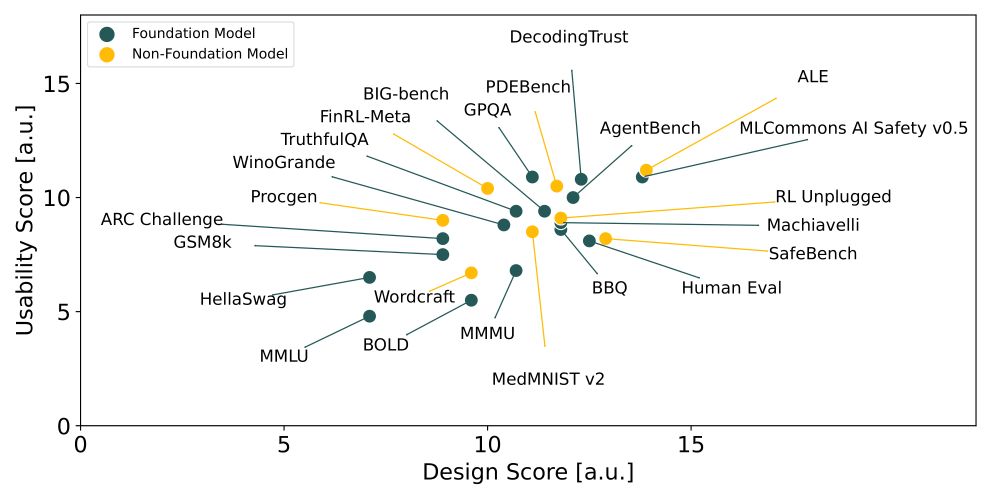
🚨New paper is out and accepted as NeurIPS 2024 Spotlight!
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.

December 12, 2024 at 6:21 PM
Check out our poster at #NeurIPS today and chat with us!
#5308: BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
4:30 PM - 7:30 PM
West Ballroom A-D
#5308: BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
4:30 PM - 7:30 PM
West Ballroom A-D
Reposted by Max Lamparth, Ph.D.

In our latest brief, Stanford scholars present a novel assessment framework for evaluating the quality of AI benchmarks and share best practices for minimum quality assurance. @ankareuel.bsky.social @chansmi.bsky.social @mlamparth.bsky.social hai.stanford.edu/what-makes-g...

December 11, 2024 at 6:08 PM
In our latest brief, Stanford scholars present a novel assessment framework for evaluating the quality of AI benchmarks and share best practices for minimum quality assurance. @ankareuel.bsky.social @chansmi.bsky.social @mlamparth.bsky.social hai.stanford.edu/what-makes-g...
Reposted by Max Lamparth, Ph.D.
I'm seeking a postdoc to work with me and @kenholstein.bsky.social on evaluating AI/ML decision support for human experts:
statmodeling.stat.columbia.edu/2024/12/10/p...
P.S. I'll be at NeurIPS Thurs-Mon. Happy to talk about this position or related mutual interests!
Please repost 🙏
statmodeling.stat.columbia.edu/2024/12/10/p...
P.S. I'll be at NeurIPS Thurs-Mon. Happy to talk about this position or related mutual interests!
Please repost 🙏
Postdoc position at Northwestern on evaluating AI/ML decision support | Statistical Modeling, Causal Inference, and Social Science
statmodeling.stat.columbia.edu
December 10, 2024 at 6:18 PM
I'm seeking a postdoc to work with me and @kenholstein.bsky.social on evaluating AI/ML decision support for human experts:
statmodeling.stat.columbia.edu/2024/12/10/p...
P.S. I'll be at NeurIPS Thurs-Mon. Happy to talk about this position or related mutual interests!
Please repost 🙏
statmodeling.stat.columbia.edu/2024/12/10/p...
P.S. I'll be at NeurIPS Thurs-Mon. Happy to talk about this position or related mutual interests!
Please repost 🙏
Our new policy brief with @stanfordhai.bsky.social is out!
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.

December 11, 2024 at 5:03 PM
Our new policy brief with @stanfordhai.bsky.social is out!
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
I’m at #NeurIPS2024 @neuripsconf.bsky.social in Vancouver this week! Hit me up if you’d like to chat about LM decision making, Interpretability, robustness, UQ, or AI safety in general 😁☕️
December 10, 2024 at 6:19 PM
I’m at #NeurIPS2024 @neuripsconf.bsky.social in Vancouver this week! Hit me up if you’d like to chat about LM decision making, Interpretability, robustness, UQ, or AI safety in general 😁☕️
Reposted by Max Lamparth, Ph.D.
Wait, are the AnthropicAI people seriously claiming to “unlock a rich theoretical landscape” for AI evaluation by proposing the use of…. error bars? And this secret trove of deep statistical insight starts with “use the Central Limit Theorem”?
Befuddling
Befuddling

November 27, 2024 at 10:09 PM
Wait, are the AnthropicAI people seriously claiming to “unlock a rich theoretical landscape” for AI evaluation by proposing the use of…. error bars? And this secret trove of deep statistical insight starts with “use the Central Limit Theorem”?
Befuddling
Befuddling
Reposted by Max Lamparth, Ph.D.
I'm teaching a grad seminar this winter on Prediction for Decision-making. We'll look at what it means to make good predictions for decision-making from various angles, with a focus on decisions for & about people.
Reading list: statmodeling.stat.columbia.edu/2024/12/06/n...
Suggestions welcome!
Reading list: statmodeling.stat.columbia.edu/2024/12/06/n...
Suggestions welcome!
New Course: Prediction for (Individualized) Decision-making | Statistical Modeling, Causal Inference, and Social Science
statmodeling.stat.columbia.edu
December 6, 2024 at 4:45 PM
I'm teaching a grad seminar this winter on Prediction for Decision-making. We'll look at what it means to make good predictions for decision-making from various angles, with a focus on decisions for & about people.
Reading list: statmodeling.stat.columbia.edu/2024/12/06/n...
Suggestions welcome!
Reading list: statmodeling.stat.columbia.edu/2024/12/06/n...
Suggestions welcome!