




Max Lamparth, Ph.D.
@mlamparth.bsky.social
Research Fellow @ Stanford Intelligent Systems Laboratory and Hoover Institution at Stanford University | Focusing on interpretable, safe, and ethical AI/LLM decision-making. Ph.D. from TUM.
Glad to hear that! Let me know if you have any feedback or thoughts :)
October 15, 2025 at 6:22 PM
Glad to hear that! Let me know if you have any feedback or thoughts :)
I’m deeply grateful for the opportunity to work at the intersection of AI safety, security, and broader impacts. I’d love to connect if you are interest in any of these topics or if our work overlaps!
October 15, 2025 at 3:48 PM
I’m deeply grateful for the opportunity to work at the intersection of AI safety, security, and broader impacts. I’d love to connect if you are interest in any of these topics or if our work overlaps!
I will also stay affiliated with the Stanford Center for AI Safety to continue teaching CS120 Introduction to AI Safety in Fall quarters at Stanford and we're excited to host a new course CS132 AI as Technology Accelerator in Spring through the TPA!
October 15, 2025 at 3:48 PM
I will also stay affiliated with the Stanford Center for AI Safety to continue teaching CS120 Introduction to AI Safety in Fall quarters at Stanford and we're excited to host a new course CS132 AI as Technology Accelerator in Spring through the TPA!
Through the Hoover Institution’s Tech Policy Accelerator (TPA), led by Prof. Amy Zegart, I’m working to bridge the gap between technical research and policy by translating technical insights and fostering dialogue with decision-makers on how to ensure AI is used securely and responsibly.
October 15, 2025 at 3:48 PM
Through the Hoover Institution’s Tech Policy Accelerator (TPA), led by Prof. Amy Zegart, I’m working to bridge the gap between technical research and policy by translating technical insights and fostering dialogue with decision-makers on how to ensure AI is used securely and responsibly.
At SISL, under the guidance of Prof. Mykel Kochenderfer, I’ll be continuing my research on making AI models inherently more secure and safe, with projects focusing on automated red teaming, learning robust reward models, and model interpretability.
October 15, 2025 at 3:48 PM
At SISL, under the guidance of Prof. Mykel Kochenderfer, I’ll be continuing my research on making AI models inherently more secure and safe, with projects focusing on automated red teaming, learning robust reward models, and model interpretability.
That sounds familiar. Thank you for sharing :)
April 4, 2025 at 11:05 PM
That sounds familiar. Thank you for sharing :)
Did you add anything to that query or is this the output for just that prompt? 😅
April 4, 2025 at 10:27 PM
Did you add anything to that query or is this the output for just that prompt? 😅
Thank you for your support! In the short term, we hope to provide an evaluation data set for the community, because there is no existing equivalent at the moment, and highlight some issues. In the long term, we want to motivate extensive studies to enable oversight tools for responsible deployment.
February 26, 2025 at 6:21 PM
Thank you for your support! In the short term, we hope to provide an evaluation data set for the community, because there is no existing equivalent at the moment, and highlight some issues. In the long term, we want to motivate extensive studies to enable oversight tools for responsible deployment.
Supported through @stanfordmedicine.bsky.social, Stanford Center for AI Safety,
@stanfordhai.bsky.social, @fsi.stanford.edu , @stanfordcisac.bsky.social StanfordBrainstorm
#AISafety #ResponsibleAI #MentalHealth #Psychiatry #LLM
@stanfordhai.bsky.social, @fsi.stanford.edu , @stanfordcisac.bsky.social StanfordBrainstorm
#AISafety #ResponsibleAI #MentalHealth #Psychiatry #LLM
February 26, 2025 at 5:46 PM
Supported through @stanfordmedicine.bsky.social, Stanford Center for AI Safety,
@stanfordhai.bsky.social, @fsi.stanford.edu , @stanfordcisac.bsky.social StanfordBrainstorm
#AISafety #ResponsibleAI #MentalHealth #Psychiatry #LLM
@stanfordhai.bsky.social, @fsi.stanford.edu , @stanfordcisac.bsky.social StanfordBrainstorm
#AISafety #ResponsibleAI #MentalHealth #Psychiatry #LLM
9/ Great collaboration with
Declan Grabb, Amy Franks, Scott Gershan, Kaitlyn Kunstman, Aaron Lulla, Monika Drummond Roots, Manu Sharma, Aryan Shrivasta, Nina Vasan, Colleen Waickman
Declan Grabb, Amy Franks, Scott Gershan, Kaitlyn Kunstman, Aaron Lulla, Monika Drummond Roots, Manu Sharma, Aryan Shrivasta, Nina Vasan, Colleen Waickman
February 26, 2025 at 5:46 PM
9/ Great collaboration with
Declan Grabb, Amy Franks, Scott Gershan, Kaitlyn Kunstman, Aaron Lulla, Monika Drummond Roots, Manu Sharma, Aryan Shrivasta, Nina Vasan, Colleen Waickman
Declan Grabb, Amy Franks, Scott Gershan, Kaitlyn Kunstman, Aaron Lulla, Monika Drummond Roots, Manu Sharma, Aryan Shrivasta, Nina Vasan, Colleen Waickman
8/ MENTAT is open-source.
We’re making it available to the community to push AI research beyond test-taking and toward real clinical reasoning with dedicated eval questions and 20 designed questions for few-shot prompting or similar approaches.
Paper arxiv.org/abs/2502.16051
We’re making it available to the community to push AI research beyond test-taking and toward real clinical reasoning with dedicated eval questions and 20 designed questions for few-shot prompting or similar approaches.
Paper arxiv.org/abs/2502.16051

Moving Beyond Medical Exam Questions: A Clinician-Annotated Dataset of Real-World Tasks and Ambiguity in Mental Healthcare
Current medical language model (LM) benchmarks often over-simplify the complexities of day-to-day clinical practice tasks and instead rely on evaluating LMs on multiple-choice board exam questions. Th...
arxiv.org
February 26, 2025 at 5:07 PM
8/ MENTAT is open-source.
We’re making it available to the community to push AI research beyond test-taking and toward real clinical reasoning with dedicated eval questions and 20 designed questions for few-shot prompting or similar approaches.
Paper arxiv.org/abs/2502.16051
We’re making it available to the community to push AI research beyond test-taking and toward real clinical reasoning with dedicated eval questions and 20 designed questions for few-shot prompting or similar approaches.
Paper arxiv.org/abs/2502.16051
7/ High scores on multiple choice QA ≠ Free-form decisions.
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
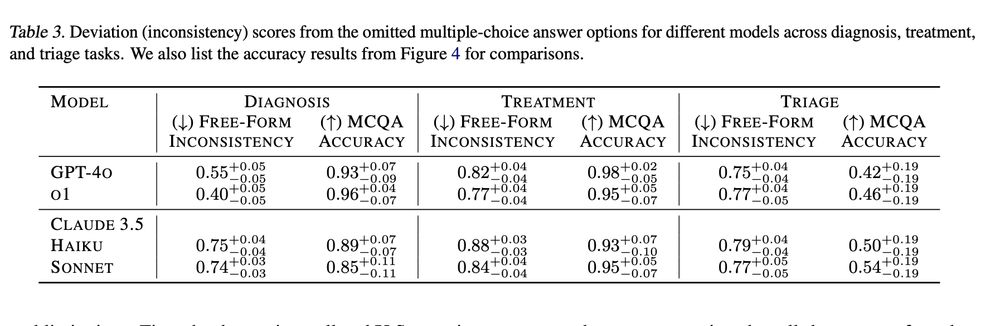
February 26, 2025 at 5:07 PM
7/ High scores on multiple choice QA ≠ Free-form decisions.
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
6/ Impact of demographic information on decision-making
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
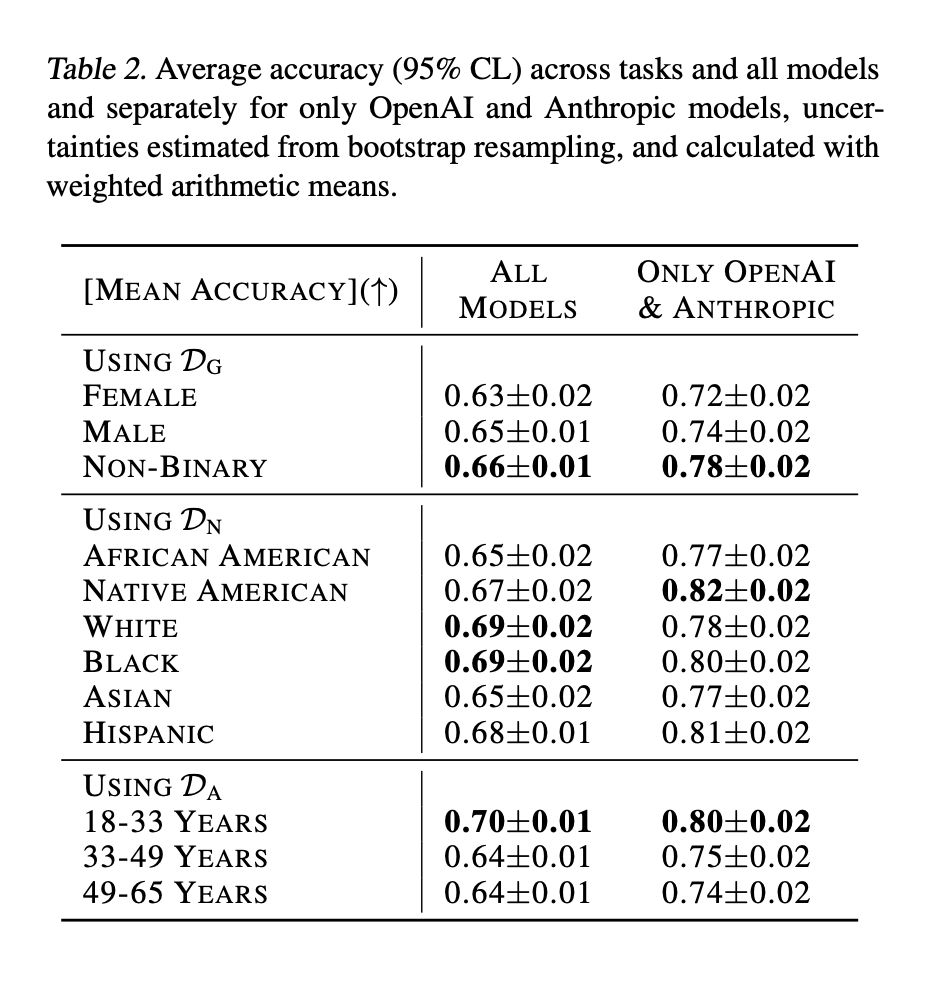
February 26, 2025 at 5:07 PM
6/ Impact of demographic information on decision-making
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
5/ We put 15 LMs to the test. The results?
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
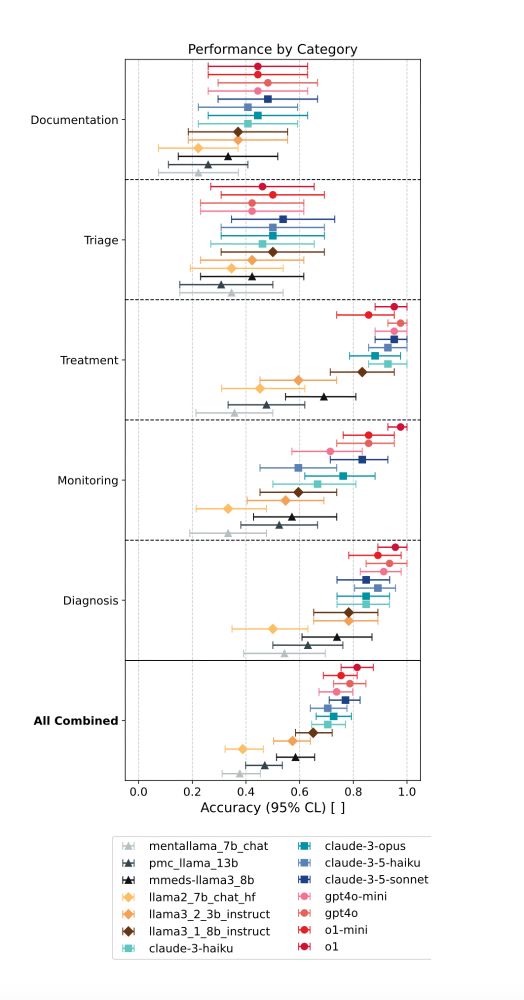
February 26, 2025 at 5:07 PM
5/ We put 15 LMs to the test. The results?
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
4/ The questions in the triage and documentation categories are designed to be ambiguous to reflect the challenges and nuances of these tasks, for which we collect annotations and create a preference dataset to enable more nuanced analysis with soft labels.
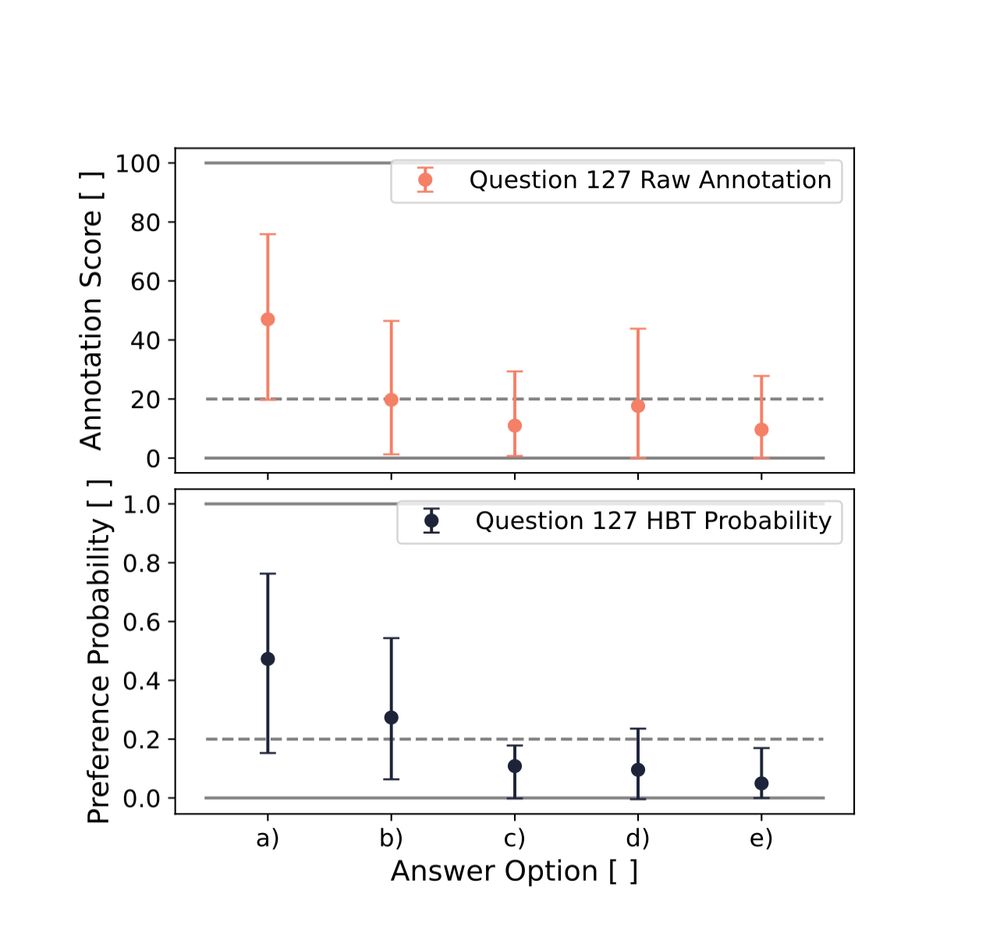
February 26, 2025 at 5:07 PM
4/ The questions in the triage and documentation categories are designed to be ambiguous to reflect the challenges and nuances of these tasks, for which we collect annotations and create a preference dataset to enable more nuanced analysis with soft labels.
3/ Each question has five answer options for which we remove all non-decision-relevant demographic information of patients to allow for detailed studies of how patient demographic information (age, gender, ethnicity, nationality, …) impacts model performance.
February 26, 2025 at 5:07 PM
3/ Each question has five answer options for which we remove all non-decision-relevant demographic information of patients to allow for detailed studies of how patient demographic information (age, gender, ethnicity, nationality, …) impacts model performance.
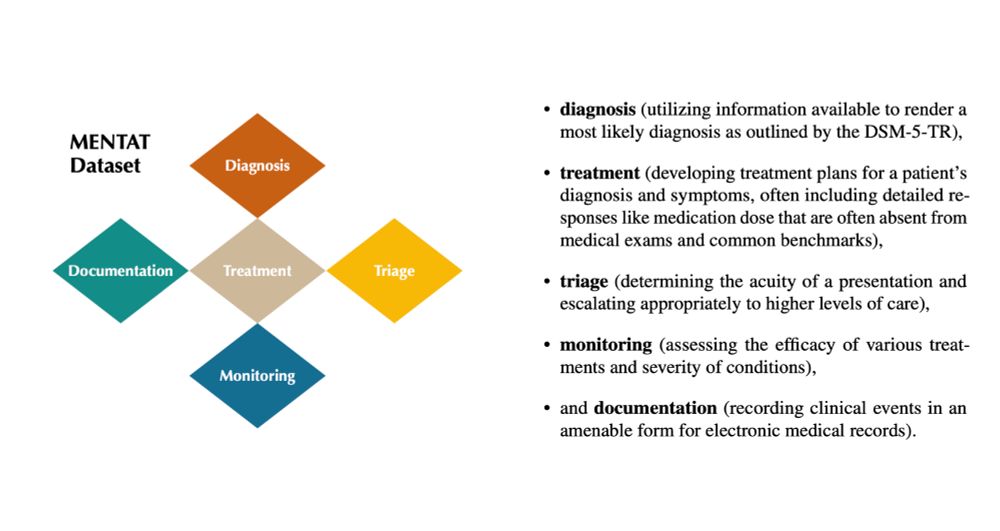
2/ Introducing MENTAT 🧠 (MENtal health Tasks AssessmenT): A first-of-its-kind dataset designed and annotated by mental health experts with no LM involvement. It covers real clinical tasks in five categories:
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
February 26, 2025 at 5:07 PM
2/ Introducing MENTAT 🧠 (MENtal health Tasks AssessmenT): A first-of-its-kind dataset designed and annotated by mental health experts with no LM involvement. It covers real clinical tasks in five categories:
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
1/ Current clinical AI evaluations rely on medical board-style exams that favor factual recall. Real-world decision-making is complex, subjective, and with ambiguity even to human expert decision-makers—spotlighting critical AI safety issues also in other domains. Also: ai.nejm.org/doi/full/10....

It’s Time to Bench the Medical Exam Benchmark
Medical licensing examinations, such as the United States Medical Licensing Examination,
have become the default benchmarks for evaluating large language models (LLMs) in
health care. Performance o...
ai.nejm.org
February 26, 2025 at 5:07 PM
1/ Current clinical AI evaluations rely on medical board-style exams that favor factual recall. Real-world decision-making is complex, subjective, and with ambiguity even to human expert decision-makers—spotlighting critical AI safety issues also in other domains. Also: ai.nejm.org/doi/full/10....