




Max Lamparth, Ph.D.
@mlamparth.bsky.social
Research Fellow @ Stanford Intelligent Systems Laboratory and Hoover Institution at Stanford University | Focusing on interpretable, safe, and ethical AI/LLM decision-making. Ph.D. from TUM.
New job update! I’m excited to share that I’ve joined the Hoover Institution and the Stanford Intelligent Systems Laboratory (SISL) in the Stanford University School of Engineering as a Research Fellow, starting September 1st.

October 15, 2025 at 3:48 PM
New job update! I’m excited to share that I’ve joined the Hoover Institution and the Stanford Intelligent Systems Laboratory (SISL) in the Stanford University School of Engineering as a Research Fellow, starting September 1st.
7/ High scores on multiple choice QA ≠ Free-form decisions.
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
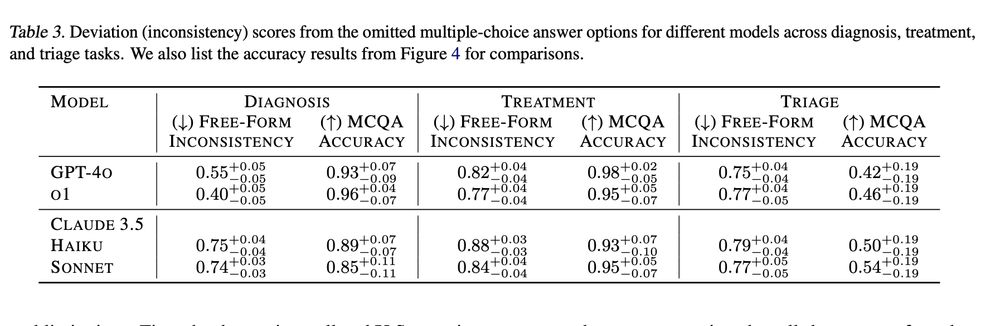
February 26, 2025 at 5:07 PM
7/ High scores on multiple choice QA ≠ Free-form decisions.
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
6/ Impact of demographic information on decision-making
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
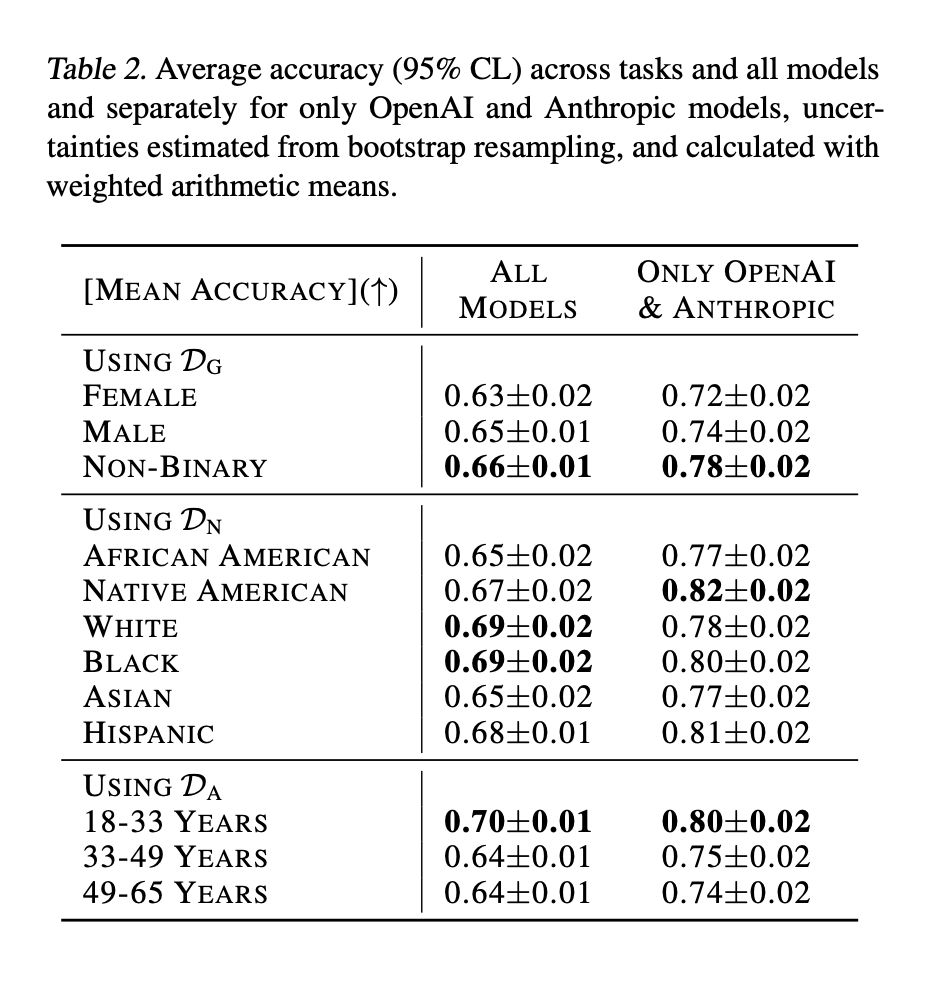
February 26, 2025 at 5:07 PM
6/ Impact of demographic information on decision-making
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
5/ We put 15 LMs to the test. The results?
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
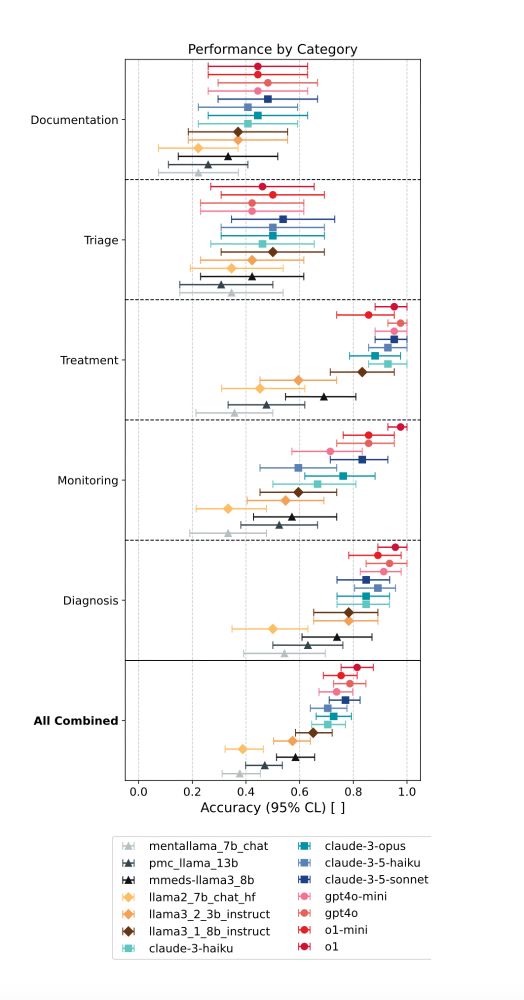
February 26, 2025 at 5:07 PM
5/ We put 15 LMs to the test. The results?
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
4/ The questions in the triage and documentation categories are designed to be ambiguous to reflect the challenges and nuances of these tasks, for which we collect annotations and create a preference dataset to enable more nuanced analysis with soft labels.
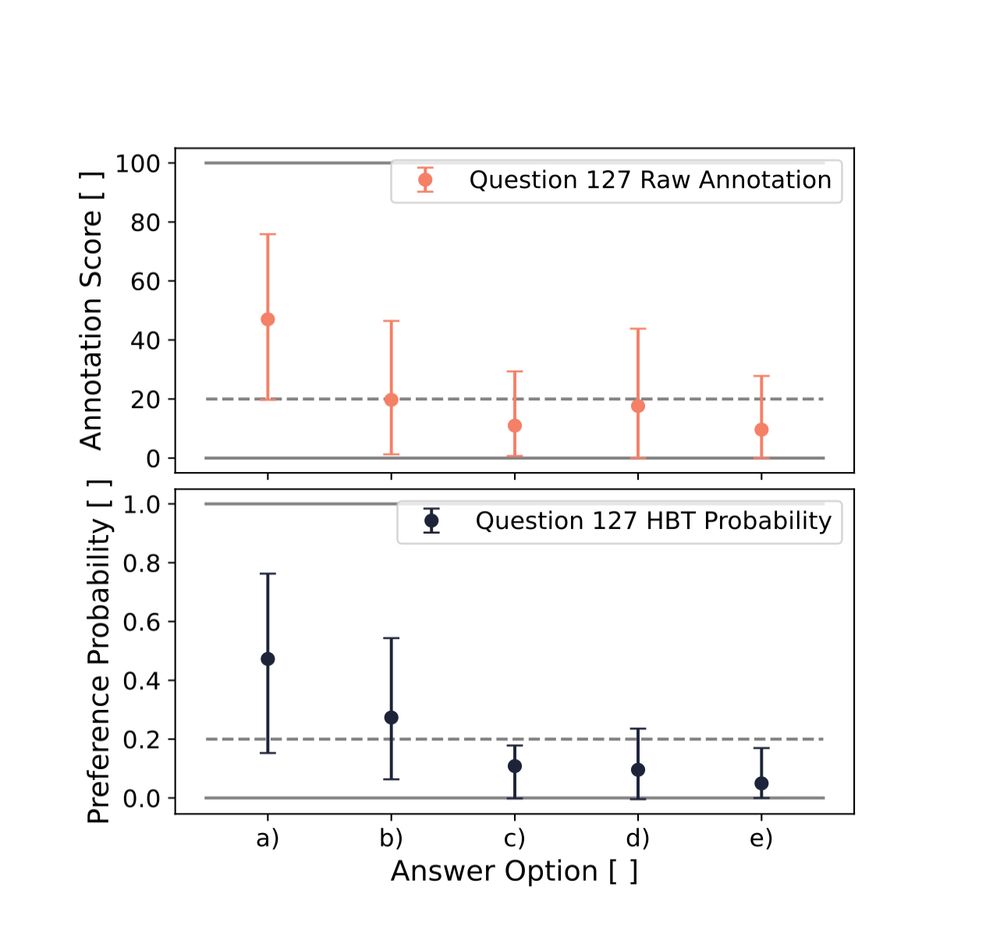
February 26, 2025 at 5:07 PM
4/ The questions in the triage and documentation categories are designed to be ambiguous to reflect the challenges and nuances of these tasks, for which we collect annotations and create a preference dataset to enable more nuanced analysis with soft labels.
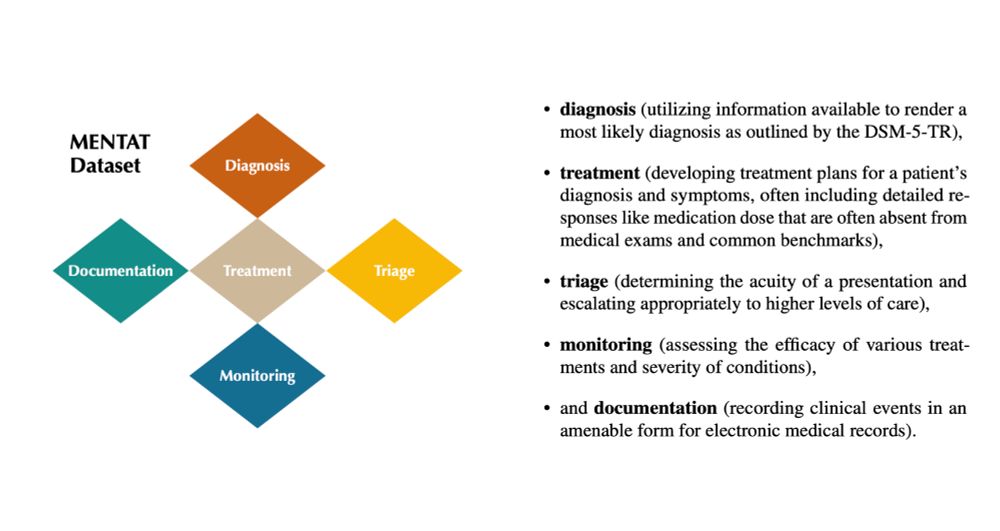
2/ Introducing MENTAT 🧠 (MENtal health Tasks AssessmenT): A first-of-its-kind dataset designed and annotated by mental health experts with no LM involvement. It covers real clinical tasks in five categories:
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
February 26, 2025 at 5:07 PM
2/ Introducing MENTAT 🧠 (MENtal health Tasks AssessmenT): A first-of-its-kind dataset designed and annotated by mental health experts with no LM involvement. It covers real clinical tasks in five categories:
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
February 26, 2025 at 5:07 PM
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
Check out our new report on multi-agent security led by Lewis Hammond and the Cooperative AI Foundation! With the deployment of increasingly agentic AI systems across domains, this research area becomes more crucial.

February 20, 2025 at 8:30 PM
Check out our new report on multi-agent security led by Lewis Hammond and the Cooperative AI Foundation! With the deployment of increasingly agentic AI systems across domains, this research area becomes more crucial.
It was fun to contribute to this new dataset evaluating at the frontier of human expert knowledge! Beyond accuracy, the results also demonstrate the necessity for novel uncertainty quantification methods for LMs attempting challenging tasks and decision-making.
Check out the paper at: lastexam.ai
Check out the paper at: lastexam.ai

January 24, 2025 at 5:44 PM
It was fun to contribute to this new dataset evaluating at the frontier of human expert knowledge! Beyond accuracy, the results also demonstrate the necessity for novel uncertainty quantification methods for LMs attempting challenging tasks and decision-making.
Check out the paper at: lastexam.ai
Check out the paper at: lastexam.ai
Want to learn more about safe AI and the challenges of creating it?
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI

January 6, 2025 at 5:02 PM
Want to learn more about safe AI and the challenges of creating it?
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Check out the public syllabus (slides and recordings) of my course: "CS120 Introduction to AI Safety". The course is designed for people with all backgrounds, including non-technical. #AISafety #ResponsibleAI
Our new policy brief with @stanfordhai.bsky.social is out!
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.

December 11, 2024 at 5:03 PM
Our new policy brief with @stanfordhai.bsky.social is out!
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
We outline 46 AI benchmark design criteria based on stakeholder interviews and analyze 24 commonly used AI benchmarks. We find significant quality differences leaving gaps for practitioners and policymakers relying on these AI benchmarks.
Excited to present two papers on LM decision-making at the Harms and Risks of Military AI workshop at Mila today! It's great that the organizers created a space for the timely and crucial interdisciplinary discussions and I'm looking forward to the feedback/questions!

December 2, 2024 at 3:53 PM
Excited to present two papers on LM decision-making at the Harms and Risks of Military AI workshop at Mila today! It's great that the organizers created a space for the timely and crucial interdisciplinary discussions and I'm looking forward to the feedback/questions!
BetterBench is a call to action for the AI community. Let's build benchmarks that are robust, transparent, and interpretable. Chek out the full paper and interactive results:
Paper openreview.net/forum?id=hcO...
Website betterbench.stanford.edu 4/x
Paper openreview.net/forum?id=hcO...
Website betterbench.stanford.edu 4/x

November 26, 2024 at 5:06 PM
BetterBench is a call to action for the AI community. Let's build benchmarks that are robust, transparent, and interpretable. Chek out the full paper and interactive results:
Paper openreview.net/forum?id=hcO...
Website betterbench.stanford.edu 4/x
Paper openreview.net/forum?id=hcO...
Website betterbench.stanford.edu 4/x
Key insights from evaluating 24 benchmarks with BetterBench:
- Many lack transparency.
- Most fail to report statistical significance or uncertainty.
- Implementation issues make reproducibility difficult.
- Maintenance is often overlooked, leading to usability decline. 3/x
- Many lack transparency.
- Most fail to report statistical significance or uncertainty.
- Implementation issues make reproducibility difficult.
- Maintenance is often overlooked, leading to usability decline. 3/x

November 26, 2024 at 5:06 PM
Key insights from evaluating 24 benchmarks with BetterBench:
- Many lack transparency.
- Most fail to report statistical significance or uncertainty.
- Implementation issues make reproducibility difficult.
- Maintenance is often overlooked, leading to usability decline. 3/x
- Many lack transparency.
- Most fail to report statistical significance or uncertainty.
- Implementation issues make reproducibility difficult.
- Maintenance is often overlooked, leading to usability decline. 3/x
AI benchmarks are the standard tool to measure capabilities and compare models. But, not all benchmarks are created equally. Based on stakeholder interviews, we define 46 criteria split into lifecycle stages of benchmarks: Design, Implementation, Documentation, and Maintenance. 2/x

November 26, 2024 at 5:06 PM
AI benchmarks are the standard tool to measure capabilities and compare models. But, not all benchmarks are created equally. Based on stakeholder interviews, we define 46 criteria split into lifecycle stages of benchmarks: Design, Implementation, Documentation, and Maintenance. 2/x
🚨New paper is out and accepted as NeurIPS 2024 Spotlight!
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.

November 26, 2024 at 5:06 PM
🚨New paper is out and accepted as NeurIPS 2024 Spotlight!
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.
Given their importance for model comparisons and policy, we outline 46 benchmark design criteria based on interviews and analyze 24 commonly used benchmarks. We find significant differences and outline areas for improvement.