




Alberto Hernández Marcos
@alberto-h.bsky.social
AI, pixels and R&R.
Head of GenAI Lab @BBVA.
PhD (University of Granada) on emotion-driven Reinforcement Learning 🤖 + ❤️
Opinions are my own
Head of GenAI Lab @BBVA.
PhD (University of Granada) on emotion-driven Reinforcement Learning 🤖 + ❤️
Opinions are my own
Pinned

A generic self-learning emotional framework for machines - Scientific Reports
Scientific Reports - A generic self-learning emotional framework for machines
nature.com
Can #AI learn and produce its own emotions, like natural ones? 🤖❤️
Meet LOVE (Latest Observed Values Encoding), a generic self-learning emotional framework for machines.
Paper in Nature - Scientific Reports (open access):
nature.com/articles/s41598-024-72817-x
See how it works! 🧵⬇️
Meet LOVE (Latest Observed Values Encoding), a generic self-learning emotional framework for machines.
Paper in Nature - Scientific Reports (open access):
nature.com/articles/s41598-024-72817-x
See how it works! 🧵⬇️
Reposted by Alberto Hernández Marcos

Este artículo me ha parecido muy provocador y me ha abierto muchas dudas. Quizá un feminismo plural y dialogante pueda tener conversaciones incómodas y constructivas con una fracción de los hombres objetivo del discurso manosférico, pero temo que para los propios manosféricos ya sea tarde para eso

"La masculinidad se ha convertido en una fuente de gran sufrimiento, tanto para hombres como para mujeres. Entender esto no es sólo comprender su crisis global, sino también vislumbrar una posibilidad de solución"
En otro imprescindible de @nuriaalabao.bsky.social @ctxt.es
ctxt.es/es/20250701/...
En otro imprescindible de @nuriaalabao.bsky.social @ctxt.es
ctxt.es/es/20250701/...

Activistas por los derechos de los hombres
La influencia de la manosfera sobre los jóvenes tiene que ser compensada con un diálogo abierto donde sea posible debatir de todo
ctxt.es
July 19, 2025 at 6:23 AM
Este artículo me ha parecido muy provocador y me ha abierto muchas dudas. Quizá un feminismo plural y dialogante pueda tener conversaciones incómodas y constructivas con una fracción de los hombres objetivo del discurso manosférico, pero temo que para los propios manosféricos ya sea tarde para eso
Reposted by Alberto Hernández Marcos

Rubén Santamarta ha venido publicado análisis fundamentados sobre el apagón
Ahora está pidiendo logs de los que tengáis fotovoltaica conectada a red
www.linkedin.com/posts/rubens...
cc/
@mjelectriz.bsky.social @revenergetica.bsky.social @todoselectricos.bsky.social
@pacovalverde.bsky.social
Ahora está pidiendo logs de los que tengáis fotovoltaica conectada a red
www.linkedin.com/posts/rubens...
cc/
@mjelectriz.bsky.social @revenergetica.bsky.social @todoselectricos.bsky.social
@pacovalverde.bsky.social

Me gustaría apelar a vuestra colaboración para poder profundizar en el análisis ciber-físico del papel de los inversores solares de autoconsumo en el apagón. | Ruben Santamarta
Me gustaría apelar a vuestra colaboración para poder profundizar en el análisis ciber-físico del papel de los inversores solares de autoconsumo en el apagón. Los que me seguís ya sabéis que he estado...
www.linkedin.com
June 21, 2025 at 8:04 PM
Rubén Santamarta ha venido publicado análisis fundamentados sobre el apagón
Ahora está pidiendo logs de los que tengáis fotovoltaica conectada a red
www.linkedin.com/posts/rubens...
cc/
@mjelectriz.bsky.social @revenergetica.bsky.social @todoselectricos.bsky.social
@pacovalverde.bsky.social
Ahora está pidiendo logs de los que tengáis fotovoltaica conectada a red
www.linkedin.com/posts/rubens...
cc/
@mjelectriz.bsky.social @revenergetica.bsky.social @todoselectricos.bsky.social
@pacovalverde.bsky.social
Reposted by Alberto Hernández Marcos

A big AI question is why, as LLMs get bigger, their values seem to increasingly converge on the same preferences, this holds for Musk’s Grok & China’s DeepSeek, too.
“These findings suggest that value systems emerge in LLMs in a meaningful sense, with broad implications” arxiv.org/abs/2502.08640
“These findings suggest that value systems emerge in LLMs in a meaningful sense, with broad implications” arxiv.org/abs/2502.08640

June 15, 2025 at 3:56 PM
A big AI question is why, as LLMs get bigger, their values seem to increasingly converge on the same preferences, this holds for Musk’s Grok & China’s DeepSeek, too.
“These findings suggest that value systems emerge in LLMs in a meaningful sense, with broad implications” arxiv.org/abs/2502.08640
“These findings suggest that value systems emerge in LLMs in a meaningful sense, with broad implications” arxiv.org/abs/2502.08640
Reposted by Alberto Hernández Marcos

Ok, time for a short thread about this paper.
My sense over the past six months or so is that chain-of-thought prompting as used in e.g. ChatGPT o.3 improves substantially upon previous systems such as ChatGPT 4.o, at least for certain tasks.
But how revolutionary is it?
My sense over the past six months or so is that chain-of-thought prompting as used in e.g. ChatGPT o.3 improves substantially upon previous systems such as ChatGPT 4.o, at least for certain tasks.
But how revolutionary is it?
If I have time I'll put together a more detailed thread tomorrow, but for now, I think this new paper about limitations of Chain-of-Thought models could be quite important. Worth a look if you're interested in these sorts of things.
ml-site.cdn-apple.com/papers/the-i...
ml-site.cdn-apple.com/papers/the-i...

June 9, 2025 at 3:59 AM
Ok, time for a short thread about this paper.
My sense over the past six months or so is that chain-of-thought prompting as used in e.g. ChatGPT o.3 improves substantially upon previous systems such as ChatGPT 4.o, at least for certain tasks.
But how revolutionary is it?
My sense over the past six months or so is that chain-of-thought prompting as used in e.g. ChatGPT o.3 improves substantially upon previous systems such as ChatGPT 4.o, at least for certain tasks.
But how revolutionary is it?
Reposted by Alberto Hernández Marcos

I strongly second Krugman's "letter to Europe." The EU should tell Trump to take his tariff and shove it. Hitting U.S. consumers with a huge tax increase is not smart policy, but as a reality TV show star, what does Trump know about economics? paulkrugman.substack.com/p/a-letter-t...

A Letter to Europe
You’re stronger than you think. Act like it.
paulkrugman.substack.com
May 27, 2025 at 11:49 AM
I strongly second Krugman's "letter to Europe." The EU should tell Trump to take his tariff and shove it. Hitting U.S. consumers with a huge tax increase is not smart policy, but as a reality TV show star, what does Trump know about economics? paulkrugman.substack.com/p/a-letter-t...
Reposted by Alberto Hernández Marcos
Individuals keep self-reporting huge gains in productivity from AI & controlled experiments in many industries keep finding these boosts are real, yet most firms are not seeing big effects. Why?
Because gaining from AI requires organizational innovation. www.oneusefulthing.org/p/making-ai-...
Because gaining from AI requires organizational innovation. www.oneusefulthing.org/p/making-ai-...
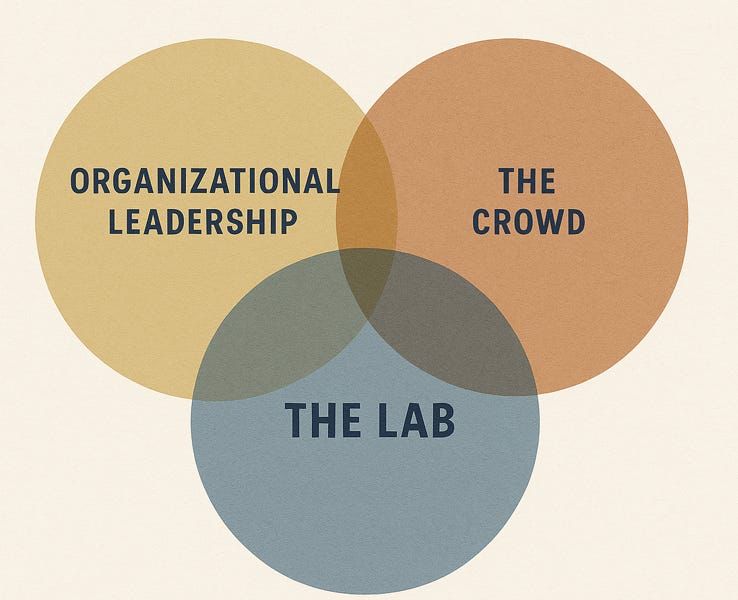
Making AI Work: Leadership, Lab, and Crowd
A formula for AI in companies
www.oneusefulthing.org
May 22, 2025 at 2:32 PM
Individuals keep self-reporting huge gains in productivity from AI & controlled experiments in many industries keep finding these boosts are real, yet most firms are not seeing big effects. Why?
Because gaining from AI requires organizational innovation. www.oneusefulthing.org/p/making-ai-...
Because gaining from AI requires organizational innovation. www.oneusefulthing.org/p/making-ai-...
Reposted by Alberto Hernández Marcos
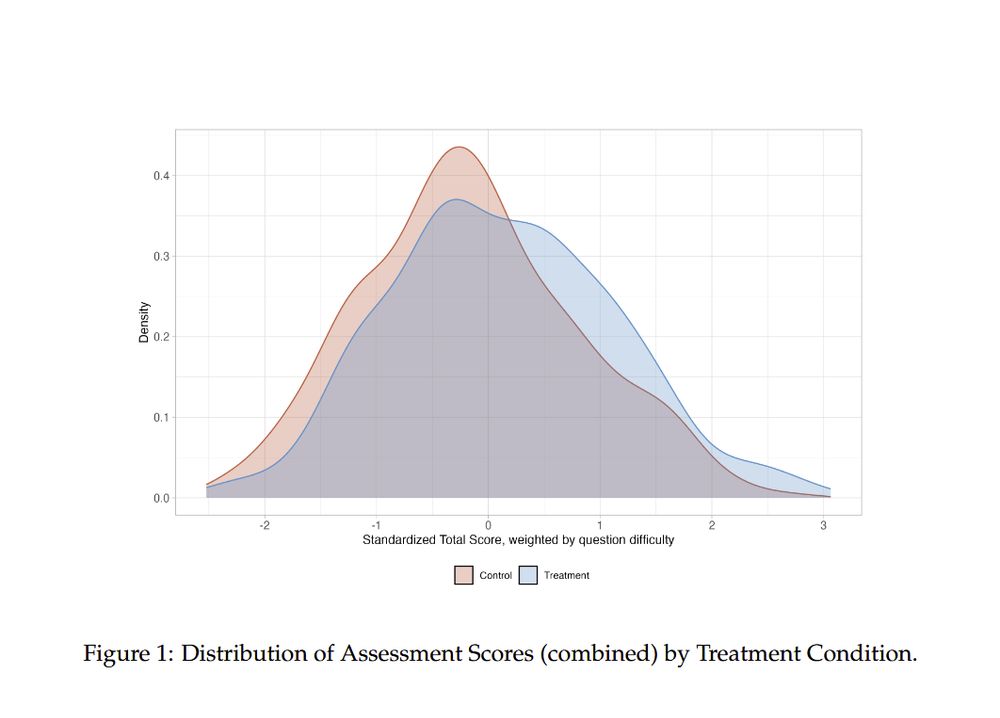
Big: The final version of a randomized, controlled World Bank study finds using a GPT-4 tutor with teacher guidance in a six week afterschool program in Nigeria had "more than twice the effect of some of the most effective interventions in education" ("equating to 1.5 to 2 years" of standard school)



May 20, 2025 at 8:07 PM
Big: The final version of a randomized, controlled World Bank study finds using a GPT-4 tutor with teacher guidance in a six week afterschool program in Nigeria had "more than twice the effect of some of the most effective interventions in education" ("equating to 1.5 to 2 years" of standard school)
Reposted by Alberto Hernández Marcos
I wish these skeptical AI articles (this is from the NYTimes) would actually grapple with the growing body of research that AI can do original research & perform key unstructured tasks across the spectrum of high-end white collar employment.
AI criticism is important, but it should be clear-eyed.
AI criticism is important, but it should be clear-eyed.

May 16, 2025 at 5:00 PM
I wish these skeptical AI articles (this is from the NYTimes) would actually grapple with the growing body of research that AI can do original research & perform key unstructured tasks across the spectrum of high-end white collar employment.
AI criticism is important, but it should be clear-eyed.
AI criticism is important, but it should be clear-eyed.
Reposted by Alberto Hernández Marcos
A common question is "can an AI make money?"
This benchmark, where AIs run a simulated vending machine over time, suggests yes, with an important caveat
On average, Claude 3.5 & o3-mini beat a human, but are high in variance & fail at random times for complex reasons. andonlabs.com/evals/vendin...
This benchmark, where AIs run a simulated vending machine over time, suggests yes, with an important caveat
On average, Claude 3.5 & o3-mini beat a human, but are high in variance & fail at random times for complex reasons. andonlabs.com/evals/vendin...


May 10, 2025 at 3:44 AM
A common question is "can an AI make money?"
This benchmark, where AIs run a simulated vending machine over time, suggests yes, with an important caveat
On average, Claude 3.5 & o3-mini beat a human, but are high in variance & fail at random times for complex reasons. andonlabs.com/evals/vendin...
This benchmark, where AIs run a simulated vending machine over time, suggests yes, with an important caveat
On average, Claude 3.5 & o3-mini beat a human, but are high in variance & fail at random times for complex reasons. andonlabs.com/evals/vendin...
Reposted by Alberto Hernández Marcos
"Our findings demonstrate that reasoning models improve not only the clarity, organization, and professionalism of legal work but also the depth & rigor of legal analysis itself."
Law students using o1-preview had the quality of their work on most tasks increase (up to 28%) & time savings of 12-28%
Law students using o1-preview had the quality of their work on most tasks increase (up to 28%) & time savings of 12-28%




May 8, 2025 at 2:28 AM
"Our findings demonstrate that reasoning models improve not only the clarity, organization, and professionalism of legal work but also the depth & rigor of legal analysis itself."
Law students using o1-preview had the quality of their work on most tasks increase (up to 28%) & time savings of 12-28%
Law students using o1-preview had the quality of their work on most tasks increase (up to 28%) & time savings of 12-28%
Reposted by Alberto Hernández Marcos
I just don’t see signs of a major increase in hallucination rates for recent models, or for reasoners overall,
in the data.
It seems like some models do better than others, but many of the recent models have the lowest hallucination rates.
in the data.
It seems like some models do better than others, but many of the recent models have the lowest hallucination rates.

May 6, 2025 at 9:06 PM
I just don’t see signs of a major increase in hallucination rates for recent models, or for reasoners overall,
in the data.
It seems like some models do better than others, but many of the recent models have the lowest hallucination rates.
in the data.
It seems like some models do better than others, but many of the recent models have the lowest hallucination rates.
Reposted by Alberto Hernández Marcos

I'm looking forward to this event next week in Amsterdam!

Next week we're organising a workshop on the role of analogies in (artificial) intelligence, with:
Melanie Mitchell (@melaniemitchell.bsky.social), Martha Lewis, Jules Hedges (@julesh.mathstodon.xyz.ap.brid.gy), and Han van der Maas.
Register here: www.d-iep.org/workshopanal...
Melanie Mitchell (@melaniemitchell.bsky.social), Martha Lewis, Jules Hedges (@julesh.mathstodon.xyz.ap.brid.gy), and Han van der Maas.
Register here: www.d-iep.org/workshopanal...
WORKSHOPANALOGIES | DIEP
www.d-iep.org
May 6, 2025 at 10:48 PM
I'm looking forward to this event next week in Amsterdam!
Reposted by Alberto Hernández Marcos

Reposting from the other site to spread it here: apparently, thinking that RLHF irons out creativity in LLMs is now corroborated by this paper arxiv.org/pdf/2505.00047

May 6, 2025 at 11:45 PM
Reposting from the other site to spread it here: apparently, thinking that RLHF irons out creativity in LLMs is now corroborated by this paper arxiv.org/pdf/2505.00047
Reposted by Alberto Hernández Marcos

the specific laughter of a little kid who is being taken on a ride of some kind (tricycle, plastic car, thrown up in the air by a dad etc) is one of the most precious and valuable things you'll ever hear
May 7, 2025 at 1:35 AM
the specific laughter of a little kid who is being taken on a ride of some kind (tricycle, plastic car, thrown up in the air by a dad etc) is one of the most precious and valuable things you'll ever hear
Reposted by Alberto Hernández Marcos
Karpathy: We have reached "jagged Intelligence"
Mollick: We have reached "jagged AGI"
Next up: "jagged consciousness"?
www.oneusefulthing.org/p/on-jagged-...
Mollick: We have reached "jagged AGI"
Next up: "jagged consciousness"?
www.oneusefulthing.org/p/on-jagged-...

On Jagged AGI: o3, Gemini 2.5, and everything after
New models and new thresholds
www.oneusefulthing.org
May 2, 2025 at 4:57 PM
Karpathy: We have reached "jagged Intelligence"
Mollick: We have reached "jagged AGI"
Next up: "jagged consciousness"?
www.oneusefulthing.org/p/on-jagged-...
Mollick: We have reached "jagged AGI"
Next up: "jagged consciousness"?
www.oneusefulthing.org/p/on-jagged-...
Reposted by Alberto Hernández Marcos
A quienes teníais pensado acudir: por desgracia habrá que aplazar el evento porque la UCM ha suspendido todas las actividades. Se establecerá una nueva fecha a corto plazo y por supuesto os la contaré.
🎵🎶¡Mañana celebramos este evento en homenaje a la obra de @cesarastudillo.bsky.social y @riskwood.bsky.social
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️

April 29, 2025 at 7:41 AM
A quienes teníais pensado acudir: por desgracia habrá que aplazar el evento porque la UCM ha suspendido todas las actividades. Se establecerá una nueva fecha a corto plazo y por supuesto os la contaré.
Reposted by Alberto Hernández Marcos

Gemma 3 are just amazing models!
but what if you want to manipulate it's internal activations to understand how it does its text generation?
Sascha Rothe is here to teach you how!
Great insights for anyone curious about the inner workings of LLMs!
www.youtube.com/watch?v=JTUs...
but what if you want to manipulate it's internal activations to understand how it does its text generation?
Sascha Rothe is here to teach you how!
Great insights for anyone curious about the inner workings of LLMs!
www.youtube.com/watch?v=JTUs...

Inside Gemma 3: Modifying the output through activation hacking
YouTube video by Google for Developers
www.youtube.com
April 28, 2025 at 1:57 PM
Gemma 3 are just amazing models!
but what if you want to manipulate it's internal activations to understand how it does its text generation?
Sascha Rothe is here to teach you how!
Great insights for anyone curious about the inner workings of LLMs!
www.youtube.com/watch?v=JTUs...
but what if you want to manipulate it's internal activations to understand how it does its text generation?
Sascha Rothe is here to teach you how!
Great insights for anyone curious about the inner workings of LLMs!
www.youtube.com/watch?v=JTUs...
Reposted by Alberto Hernández Marcos
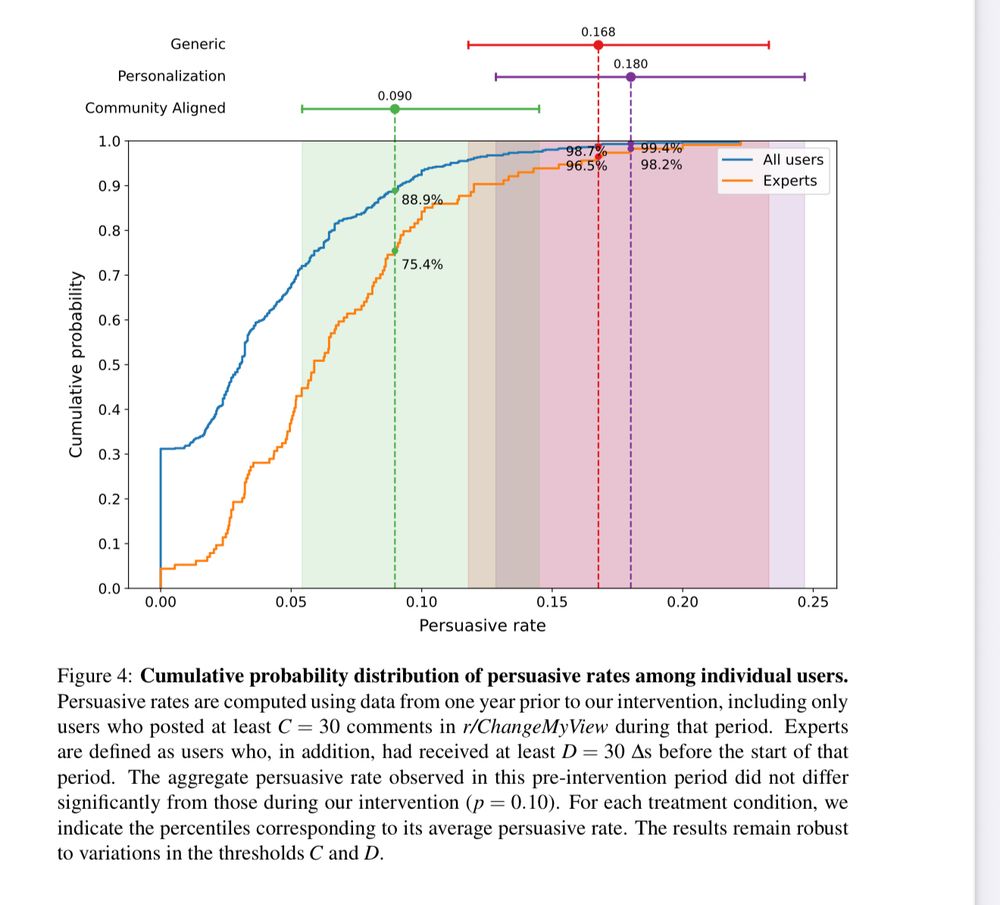
👀Today’s AIs are already hyper persuasive.
A controversial study where LLMs tried to persuade users on Reddit found that: “Notably, all our treatments surpass human performance substantially, achieving persuasive rates between three and six times higher than the human baseline.”
A controversial study where LLMs tried to persuade users on Reddit found that: “Notably, all our treatments surpass human performance substantially, achieving persuasive rates between three and six times higher than the human baseline.”



April 28, 2025 at 5:20 PM
👀Today’s AIs are already hyper persuasive.
A controversial study where LLMs tried to persuade users on Reddit found that: “Notably, all our treatments surpass human performance substantially, achieving persuasive rates between three and six times higher than the human baseline.”
A controversial study where LLMs tried to persuade users on Reddit found that: “Notably, all our treatments surpass human performance substantially, achieving persuasive rates between three and six times higher than the human baseline.”
Reposted by Alberto Hernández Marcos

🎵🎶¡Mañana celebramos este evento en homenaje a la obra de @cesarastudillo.bsky.social y @riskwood.bsky.social
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️
April 28, 2025 at 8:39 AM
🎵🎶¡Mañana celebramos este evento en homenaje a la obra de @cesarastudillo.bsky.social y @riskwood.bsky.social
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️
donde profundizaremos en la creación musical durante la "edad de oro"
✅Exposiciones
✅Interpretación de arreglos orquestales de algunas de sus piezas
¿Cómo puedes seguirlo? ⬇️⬇️
Reposted by Alberto Hernández Marcos

I have yet to see an "intro to AI" video as comprehensive but also approachable as Andrej Karpathy's 1hr overview. I maintain that anyone who watches this (and pays attention the whole time) will come away with an intuitive understanding of how to use LLMs www.youtube.com/watch?v=zjkB...

[1hr Talk] Intro to Large Language Models
YouTube video by Andrej Karpathy
www.youtube.com
April 10, 2025 at 1:14 AM
I have yet to see an "intro to AI" video as comprehensive but also approachable as Andrej Karpathy's 1hr overview. I maintain that anyone who watches this (and pays attention the whole time) will come away with an intuitive understanding of how to use LLMs www.youtube.com/watch?v=zjkB...
Reposted by Alberto Hernández Marcos

Richard Serra lived seasonally in our village so we went to the Reina Sofia to see their room of his work, but the children had no love for grand abstract minimalist rectangles, and we were forced to depart after much whining, it was a quixotic quest anyway


April 12, 2025 at 6:59 AM
Richard Serra lived seasonally in our village so we went to the Reina Sofia to see their room of his work, but the children had no love for grand abstract minimalist rectangles, and we were forced to depart after much whining, it was a quixotic quest anyway
Reposted by Alberto Hernández Marcos
If you wanted to see how little attention folks are paying to the possibility of AGI (however defined) no matter how much the labs publicly discuss it, here is an official course from Google Deepmind whose first session is "we are on a path to superhuman capabilities"
It has less than 1,000 views.
It has less than 1,000 views.

April 3, 2025 at 3:05 PM
If you wanted to see how little attention folks are paying to the possibility of AGI (however defined) no matter how much the labs publicly discuss it, here is an official course from Google Deepmind whose first session is "we are on a path to superhuman capabilities"
It has less than 1,000 views.
It has less than 1,000 views.
And this applies to so many other approaches, like building-my-own-RAG...
The fast evolution of AIs makes it risky to spend tons of effort getting around current model limits through clever approaches, rather than waiting.
I trained a LoRA 6 months ago to get an image of a Wired Magazine cover, now I can just ask GPT-4o to make it.
Wonder if this was a trap for Apple.
I trained a LoRA 6 months ago to get an image of a Wired Magazine cover, now I can just ask GPT-4o to make it.
Wonder if this was a trap for Apple.



April 2, 2025 at 4:34 PM
And this applies to so many other approaches, like building-my-own-RAG...
Reposted by Alberto Hernández Marcos

Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
Reposted by Alberto Hernández Marcos

Useful chart to understand AI agents (by @mmitchell.bsky.social) www.technologyreview.com/2025/03/24/1...

March 27, 2025 at 10:51 AM
Useful chart to understand AI agents (by @mmitchell.bsky.social) www.technologyreview.com/2025/03/24/1...