



Reposted

Releasing Jupyter Agents - LLMs running data analysis directly in a notebook!
The agent can load data, execute code, plot results and following your guidance and ideas!
A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!
The agent can load data, execute code, plot results and following your guidance and ideas!
A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!
December 19, 2024 at 6:56 PM
Releasing Jupyter Agents - LLMs running data analysis directly in a notebook!
The agent can load data, execute code, plot results and following your guidance and ideas!
A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!
The agent can load data, execute code, plot results and following your guidance and ideas!
A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!
Reposted

Want to grasp test time compute, the secret sauce behind recent AI breakthroughs? We've open-sourced the method - perfect holiday reading to understand what's powering the next wave of AI model development. 🧠✨
huggingface.co/spaces/Huggi...
huggingface.co/spaces/Huggi...
Scaling test-time compute - a Hugging Face Space by HuggingFaceH4
Discover amazing ML apps made by the community
huggingface.co
December 21, 2024 at 1:26 PM
Want to grasp test time compute, the secret sauce behind recent AI breakthroughs? We've open-sourced the method - perfect holiday reading to understand what's powering the next wave of AI model development. 🧠✨
huggingface.co/spaces/Huggi...
huggingface.co/spaces/Huggi...
Reposted

what was this thing btw?
"Moreover, ARC-AGI-1 is now saturating – besides o3's new score, the fact is that a large ensemble of low-compute Kaggle solutions can now score 81% on the private eval"
big ensemble of heuristics?
"Moreover, ARC-AGI-1 is now saturating – besides o3's new score, the fact is that a large ensemble of low-compute Kaggle solutions can now score 81% on the private eval"
big ensemble of heuristics?
December 21, 2024 at 5:04 PM
what was this thing btw?
"Moreover, ARC-AGI-1 is now saturating – besides o3's new score, the fact is that a large ensemble of low-compute Kaggle solutions can now score 81% on the private eval"
big ensemble of heuristics?
"Moreover, ARC-AGI-1 is now saturating – besides o3's new score, the fact is that a large ensemble of low-compute Kaggle solutions can now score 81% on the private eval"
big ensemble of heuristics?


Reposted
With the new OpenAI O3 moving performance from 5% up to 25% on FrontierMath it’s time to push open-source models upwards!
We're super happy to release FineMath, the best open math dataset yet. A strong baseline to start training your own models
Find it in the trending section of HuggingFace ;)
We're super happy to release FineMath, the best open math dataset yet. A strong baseline to start training your own models
Find it in the trending section of HuggingFace ;)

December 23, 2024 at 1:20 PM
With the new OpenAI O3 moving performance from 5% up to 25% on FrontierMath it’s time to push open-source models upwards!
We're super happy to release FineMath, the best open math dataset yet. A strong baseline to start training your own models
Find it in the trending section of HuggingFace ;)
We're super happy to release FineMath, the best open math dataset yet. A strong baseline to start training your own models
Find it in the trending section of HuggingFace ;)
Reposted

- a dataset that represents your use case or language, without costly data collection of annotation teams.
- an evaluation set so you can compare models and APIs. Unlocking performance, latency, and cost improvements.
- Improve existing datasets by filtering down to the highest quality samples.
- an evaluation set so you can compare models and APIs. Unlocking performance, latency, and cost improvements.
- Improve existing datasets by filtering down to the highest quality samples.
GitHub - huggingface/smol-course: A course on aligning smol models.
A course on aligning smol models. Contribute to huggingface/smol-course development by creating an account on GitHub.
buff.ly
December 23, 2024 at 4:00 PM
- a dataset that represents your use case or language, without costly data collection of annotation teams.
- an evaluation set so you can compare models and APIs. Unlocking performance, latency, and cost improvements.
- Improve existing datasets by filtering down to the highest quality samples.
- an evaluation set so you can compare models and APIs. Unlocking performance, latency, and cost improvements.
- Improve existing datasets by filtering down to the highest quality samples.
Reposted

Hugging Face shows how test-time scaling helps small language models punch above their weight https://venturebeat.com/ai/hugging-face-shows-how-test-time-scaling-helps-small-language-models-punch-above-their-weight/ #AI #SmallLanguageModels

Hugging Face shows how test-time scaling helps small language models punch above their weight
Given enough time to "think," small language models can beat LLMs at math and coding tasks by generating and verifying multiple answers.
venturebeat.com
December 23, 2024 at 5:33 PM
Hugging Face shows how test-time scaling helps small language models punch above their weight https://venturebeat.com/ai/hugging-face-shows-how-test-time-scaling-helps-small-language-models-punch-above-their-weight/ #AI #SmallLanguageModels
Reposted

A synthetic reasoning dataset designed to provide logical reasoning, analysis, and consistent thought processes.
Created with the Synthetic Data Generator!
"Made by Fluently Team using distilabel with love 🥰"
Dataset: https://buff.ly/3DwSKrZ
Space: https://buff.ly/3Y1S99z
Created with the Synthetic Data Generator!
"Made by Fluently Team using distilabel with love 🥰"
Dataset: https://buff.ly/3DwSKrZ
Space: https://buff.ly/3Y1S99z

fluently-sets/reasoning-1-1k · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
buff.ly
December 24, 2024 at 7:12 AM
A synthetic reasoning dataset designed to provide logical reasoning, analysis, and consistent thought processes.
Created with the Synthetic Data Generator!
"Made by Fluently Team using distilabel with love 🥰"
Dataset: https://buff.ly/3DwSKrZ
Space: https://buff.ly/3Y1S99z
Created with the Synthetic Data Generator!
"Made by Fluently Team using distilabel with love 🥰"
Dataset: https://buff.ly/3DwSKrZ
Space: https://buff.ly/3Y1S99z
Reposted

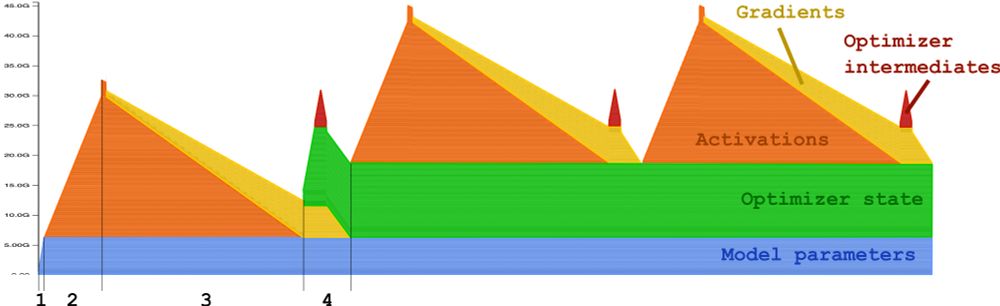
🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
December 24, 2024 at 11:04 AM
🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
Reposted

Reposted
Smol-course module drop!
Synthetic data is generated data that mimics real-world usage. It helps with data limitations and it is being used for pre- and post-training.
Learn how to create datasets for instruction and preference tuning!
GitHub: https://buff.ly/3BRwiZW
Synthetic data is generated data that mimics real-world usage. It helps with data limitations and it is being used for pre- and post-training.
Learn how to create datasets for instruction and preference tuning!
GitHub: https://buff.ly/3BRwiZW

December 24, 2024 at 1:00 PM
Smol-course module drop!
Synthetic data is generated data that mimics real-world usage. It helps with data limitations and it is being used for pre- and post-training.
Learn how to create datasets for instruction and preference tuning!
GitHub: https://buff.ly/3BRwiZW
Synthetic data is generated data that mimics real-world usage. It helps with data limitations and it is being used for pre- and post-training.
Learn how to create datasets for instruction and preference tuning!
GitHub: https://buff.ly/3BRwiZW
Reposted

Qwen released QvQ 72B OpenAI o1 like reasoning model on Hugging Face with Vision capabilities - beating GPT4o, Claude Sonnet 3.5 🔥

December 24, 2024 at 5:25 PM
Qwen released QvQ 72B OpenAI o1 like reasoning model on Hugging Face with Vision capabilities - beating GPT4o, Claude Sonnet 3.5 🔥
Reposted
Ollama + Gradio + distilabel => Free data for anyone!
Build datasets using natural language with the synthetic data generator.
GitHub: https://buff.ly/49IDSmd
Build datasets using natural language with the synthetic data generator.
GitHub: https://buff.ly/49IDSmd
December 26, 2024 at 1:00 PM
Ollama + Gradio + distilabel => Free data for anyone!
Build datasets using natural language with the synthetic data generator.
GitHub: https://buff.ly/49IDSmd
Build datasets using natural language with the synthetic data generator.
GitHub: https://buff.ly/49IDSmd