




Thomas Fel
@thomasfel.bsky.social
Explainability, Computer Vision, Neuro-AI.🪴 Kempner Fellow @Harvard.
Prev. PhD @Brown, @Google, @GoPro. Crêpe lover.
📍 Boston | 🔗 thomasfel.me
Prev. PhD @Brown, @Google, @GoPro. Crêpe lover.
📍 Boston | 🔗 thomasfel.me
Pinned
Thomas Fel
@thomasfel.bsky.social
· Oct 15

🕳️🐇Into the Rabbit Hull – Part II
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
Reposted by Thomas Fel

Are you at #NeurIPS2025? Check out the #KempnerInstitute’s Day 2 presentations! 💡
#AI #NeuroAI
@cpehlevan.bsky.social @kanakarajanphd.bsky.social @thomasfel.bsky.social @andykeller.bsky.social @binxuwang.bsky.social @njw.fish @yilundu.bsky.social
#AI #NeuroAI
@cpehlevan.bsky.social @kanakarajanphd.bsky.social @thomasfel.bsky.social @andykeller.bsky.social @binxuwang.bsky.social @njw.fish @yilundu.bsky.social

December 4, 2025 at 2:02 PM
Are you at #NeurIPS2025? Check out the #KempnerInstitute’s Day 2 presentations! 💡
#AI #NeuroAI
@cpehlevan.bsky.social @kanakarajanphd.bsky.social @thomasfel.bsky.social @andykeller.bsky.social @binxuwang.bsky.social @njw.fish @yilundu.bsky.social
#AI #NeuroAI
@cpehlevan.bsky.social @kanakarajanphd.bsky.social @thomasfel.bsky.social @andykeller.bsky.social @binxuwang.bsky.social @njw.fish @yilundu.bsky.social
Reposted by Thomas Fel
🐇Into the Rabbit Hull — Part 1: A Deep Dive into DINOv2🧠
Our latest Deeper Learning blog post is an #interpretability deep dive into one of today’s leading vision foundation models: DINOv2.
📖Read now: bit.ly/4nNfq8D
Stay tuned — Part 2 coming soon.
#AI #VLMs #DINOv2
Our latest Deeper Learning blog post is an #interpretability deep dive into one of today’s leading vision foundation models: DINOv2.
📖Read now: bit.ly/4nNfq8D
Stay tuned — Part 2 coming soon.
#AI #VLMs #DINOv2

Into the Rabbit Hull – Part I - Kempner Institute
This blog post offers an interpretability deep dive, examining the most important concepts emerging in one of today’s central vision foundation models, DINOv2. This blogpost is the first of a […]
bit.ly
November 12, 2025 at 3:49 PM
🐇Into the Rabbit Hull — Part 1: A Deep Dive into DINOv2🧠
Our latest Deeper Learning blog post is an #interpretability deep dive into one of today’s leading vision foundation models: DINOv2.
📖Read now: bit.ly/4nNfq8D
Stay tuned — Part 2 coming soon.
#AI #VLMs #DINOv2
Our latest Deeper Learning blog post is an #interpretability deep dive into one of today’s leading vision foundation models: DINOv2.
📖Read now: bit.ly/4nNfq8D
Stay tuned — Part 2 coming soon.
#AI #VLMs #DINOv2
The Bau lab is on fire ! 😍
The secret life of an LM is defined by its internal data types. Inner layers transport abstractions that are more robust than words, like concepts, functions, or pointers.
In new work yesterday, @arnabsensharma.bsky.social et al identify a data type for *predicates*.
bsky.app/profile/arn...
In new work yesterday, @arnabsensharma.bsky.social et al identify a data type for *predicates*.
bsky.app/profile/arn...

Arnab Sen Sharma (@arnabsensharma.bsky.social)
How can a language model find the veggies in a menu?
New pre-print where we investigate the internal mechanisms of LLMs when filtering on a list of options.
Spoiler: turns out LLMs use strategies surprisingly similar to functional programming (think "filter" from python)! 🧵
bsky.app
November 6, 2025 at 2:13 PM
The Bau lab is on fire ! 😍
Reposted by Thomas Fel

Interested in doing a PhD at the intersection of human and machine cognition? ✨ I'm recruiting students for Fall 2026! ✨
Topics of interest include pragmatics, metacognition, reasoning, & interpretability (in humans and AI).
Check out JHU's mentoring program (due 11/15) for help with your SoP 👇
Topics of interest include pragmatics, metacognition, reasoning, & interpretability (in humans and AI).
Check out JHU's mentoring program (due 11/15) for help with your SoP 👇

The department of Cognitive Science @jhu.edu is seeking motivated students interested in joining our interdisciplinary PhD program! Applications due 1 Dec
Our PhD students also run an application mentoring program for prospective students. Mentoring requests due November 15.
tinyurl.com/2nrn4jf9
Our PhD students also run an application mentoring program for prospective students. Mentoring requests due November 15.
tinyurl.com/2nrn4jf9

November 4, 2025 at 2:44 PM
Interested in doing a PhD at the intersection of human and machine cognition? ✨ I'm recruiting students for Fall 2026! ✨
Topics of interest include pragmatics, metacognition, reasoning, & interpretability (in humans and AI).
Check out JHU's mentoring program (due 11/15) for help with your SoP 👇
Topics of interest include pragmatics, metacognition, reasoning, & interpretability (in humans and AI).
Check out JHU's mentoring program (due 11/15) for help with your SoP 👇
Reposted by Thomas Fel

Pleased to share new work with @sflippl.bsky.social @eberleoliver.bsky.social @thomasmcgee.bsky.social & undergrad interns at Institute for Pure and Applied Mathematics, UCLA.
Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models
www.arxiv.org/pdf/2510.15987
🧵1/n
Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models
www.arxiv.org/pdf/2510.15987
🧵1/n

October 27, 2025 at 6:13 PM
Pleased to share new work with @sflippl.bsky.social @eberleoliver.bsky.social @thomasmcgee.bsky.social & undergrad interns at Institute for Pure and Applied Mathematics, UCLA.
Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models
www.arxiv.org/pdf/2510.15987
🧵1/n
Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models
www.arxiv.org/pdf/2510.15987
🧵1/n
Reposted by Thomas Fel

🧠 Thrilled to share our NeuroView with Ellie Pavlick!
"From Prediction to Understanding: Will AI Foundation Models Transform Brain Science?"
AI foundation models are coming to neuroscience—if scaling laws hold, predictive power will be unprecedented.
But is that enough?
Thread 🧵👇
"From Prediction to Understanding: Will AI Foundation Models Transform Brain Science?"
AI foundation models are coming to neuroscience—if scaling laws hold, predictive power will be unprecedented.
But is that enough?
Thread 🧵👇


October 24, 2025 at 11:22 AM
🧠 Thrilled to share our NeuroView with Ellie Pavlick!
"From Prediction to Understanding: Will AI Foundation Models Transform Brain Science?"
AI foundation models are coming to neuroscience—if scaling laws hold, predictive power will be unprecedented.
But is that enough?
Thread 🧵👇
"From Prediction to Understanding: Will AI Foundation Models Transform Brain Science?"
AI foundation models are coming to neuroscience—if scaling laws hold, predictive power will be unprecedented.
But is that enough?
Thread 🧵👇
Reposted by Thomas Fel

This is so cool. When you look at representational geometry, it seems intuitive that models are combining convex regions of "concepts", but I wouldn't have expected that this is PROVABLY true for attention or that there was such a rich theory for this kind of geometry.
🕳️🐇Into the Rabbit Hull – Part II
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
October 16, 2025 at 6:33 PM
This is so cool. When you look at representational geometry, it seems intuitive that models are combining convex regions of "concepts", but I wouldn't have expected that this is PROVABLY true for attention or that there was such a rich theory for this kind of geometry.
🕳️🐇Into the Rabbit Hull – Part II
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
October 15, 2025 at 5:17 PM
🕳️🐇Into the Rabbit Hull – Part II
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
Continuing our interpretation of DINOv2, the second part of our study concerns the *geometry of concepts* and the synthesis of our findings toward a new representational *phenomenology*:
the Minkowski Representation Hypothesis
🕳️🐇 𝙄𝙣𝙩𝙤 𝙩𝙝𝙚 𝙍𝙖𝙗𝙗𝙞𝙩 𝙃𝙪𝙡𝙡 – 𝙋𝙖𝙧𝙩 𝙄 (𝑃𝑎𝑟𝑡 𝐼𝐼 𝑡𝑜𝑚𝑜𝑟𝑟𝑜𝑤)
𝗔𝗻 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗱𝗲𝗲𝗽 𝗱𝗶𝘃𝗲 𝗶𝗻𝘁𝗼 𝗗𝗜𝗡𝗢𝘃𝟮, one of vision’s most important foundation models.
And today is Part I, buckle up, we're exploring some of its most charming features. :)
𝗔𝗻 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗱𝗲𝗲𝗽 𝗱𝗶𝘃𝗲 𝗶𝗻𝘁𝗼 𝗗𝗜𝗡𝗢𝘃𝟮, one of vision’s most important foundation models.
And today is Part I, buckle up, we're exploring some of its most charming features. :)
October 14, 2025 at 9:00 PM
🕳️🐇 𝙄𝙣𝙩𝙤 𝙩𝙝𝙚 𝙍𝙖𝙗𝙗𝙞𝙩 𝙃𝙪𝙡𝙡 – 𝙋𝙖𝙧𝙩 𝙄 (𝑃𝑎𝑟𝑡 𝐼𝐼 𝑡𝑜𝑚𝑜𝑟𝑟𝑜𝑤)
𝗔𝗻 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗱𝗲𝗲𝗽 𝗱𝗶𝘃𝗲 𝗶𝗻𝘁𝗼 𝗗𝗜𝗡𝗢𝘃𝟮, one of vision’s most important foundation models.
And today is Part I, buckle up, we're exploring some of its most charming features. :)
𝗔𝗻 𝗶𝗻𝘁𝗲𝗿𝗽𝗿𝗲𝘁𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗱𝗲𝗲𝗽 𝗱𝗶𝘃𝗲 𝗶𝗻𝘁𝗼 𝗗𝗜𝗡𝗢𝘃𝟮, one of vision’s most important foundation models.
And today is Part I, buckle up, we're exploring some of its most charming features. :)
Reposted by Thomas Fel

Superposition has reshaped interpretability research. In our @unireps.bsky.social paper led by @andre-longon.bsky.social we show it also matters for measuring alignment! Two systems can represent the same features yet appear misaligned if those features are mixed differently across neurons.

Superposition disentanglement of neural representations reveals hidden alignment
The superposition hypothesis states that a single neuron within a population may participate in the representation of multiple features in order for the population to represent more features than the ...
arxiv.org
October 8, 2025 at 8:54 PM
Superposition has reshaped interpretability research. In our @unireps.bsky.social paper led by @andre-longon.bsky.social we show it also matters for measuring alignment! Two systems can represent the same features yet appear misaligned if those features are mixed differently across neurons.
Reposted by Thomas Fel

For XAI it’s often thought explanations help (boundedly rational) user “unlock” info in features for some decision. But no one says this, they say vaguer things like “supporting trust”. We lay out some implicit assumptions that become clearer when you take a formal view here arxiv.org/abs/2506.22740

Explanations are a means to an end
Modern methods for explainable machine learning are designed to describe how models map inputs to outputs--without deep consideration of how these explanations will be used in practice. This paper arg...
arxiv.org
October 8, 2025 at 11:12 PM
For XAI it’s often thought explanations help (boundedly rational) user “unlock” info in features for some decision. But no one says this, they say vaguer things like “supporting trust”. We lay out some implicit assumptions that become clearer when you take a formal view here arxiv.org/abs/2506.22740
Reposted by Thomas Fel

🚨Updated: "How far can we go with ImageNet for Text-to-Image generation?"
TL;DR: train a text2image model from scratch on ImageNet only and beat SDXL.
Paper, code, data available! Reproducible science FTW!
🧵👇
📜 arxiv.org/abs/2502.21318
💻 github.com/lucasdegeorg...
💽 huggingface.co/arijitghosh/...
TL;DR: train a text2image model from scratch on ImageNet only and beat SDXL.
Paper, code, data available! Reproducible science FTW!
🧵👇
📜 arxiv.org/abs/2502.21318
💻 github.com/lucasdegeorg...
💽 huggingface.co/arijitghosh/...


October 8, 2025 at 8:43 PM
🚨Updated: "How far can we go with ImageNet for Text-to-Image generation?"
TL;DR: train a text2image model from scratch on ImageNet only and beat SDXL.
Paper, code, data available! Reproducible science FTW!
🧵👇
📜 arxiv.org/abs/2502.21318
💻 github.com/lucasdegeorg...
💽 huggingface.co/arijitghosh/...
TL;DR: train a text2image model from scratch on ImageNet only and beat SDXL.
Paper, code, data available! Reproducible science FTW!
🧵👇
📜 arxiv.org/abs/2502.21318
💻 github.com/lucasdegeorg...
💽 huggingface.co/arijitghosh/...
Reposted by Thomas Fel

Check out @mryskina.bsky.social's talk and poster at COLM on Tuesday—we present a method to identify 'semantically consistent' brain regions (responding to concepts across modalities) and show that more semantically consistent brain regions are better predicted by LLMs.

Interested in language models, brains, and concepts? Check out our COLM 2025 🔦 Spotlight paper!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!

October 4, 2025 at 12:43 PM
Check out @mryskina.bsky.social's talk and poster at COLM on Tuesday—we present a method to identify 'semantically consistent' brain regions (responding to concepts across modalities) and show that more semantically consistent brain regions are better predicted by LLMs.
Reposted by Thomas Fel

1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability

September 25, 2025 at 2:02 PM
1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
Reposted by Thomas Fel

Employing mechanistic interpretability to study how models learn, not just where they end up
2 papers find:
There are phase transitions where features emerge and stay throughout learning
🤖📈🧠
alphaxiv.org/pdf/2509.17196
@amuuueller.bsky.social @abosselut.bsky.social
alphaxiv.org/abs/2509.05291
2 papers find:
There are phase transitions where features emerge and stay throughout learning
🤖📈🧠
alphaxiv.org/pdf/2509.17196
@amuuueller.bsky.social @abosselut.bsky.social
alphaxiv.org/abs/2509.05291

September 26, 2025 at 3:27 PM
Employing mechanistic interpretability to study how models learn, not just where they end up
2 papers find:
There are phase transitions where features emerge and stay throughout learning
🤖📈🧠
alphaxiv.org/pdf/2509.17196
@amuuueller.bsky.social @abosselut.bsky.social
alphaxiv.org/abs/2509.05291
2 papers find:
There are phase transitions where features emerge and stay throughout learning
🤖📈🧠
alphaxiv.org/pdf/2509.17196
@amuuueller.bsky.social @abosselut.bsky.social
alphaxiv.org/abs/2509.05291
Reposted by Thomas Fel

Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵

July 14, 2025 at 12:15 PM
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵
Reposted by Thomas Fel

I was part of an interesting panel discussion yesterday at an ARC event. Maybe everybody knows this already, but I was quite surprised by how "general" intelligence was conceptualized in relation to human intelligence and the ARC benchmarks.
September 28, 2025 at 10:06 AM
I was part of an interesting panel discussion yesterday at an ARC event. Maybe everybody knows this already, but I was quite surprised by how "general" intelligence was conceptualized in relation to human intelligence and the ARC benchmarks.
Phenomenology → principle → method.
From observed phenomena in representations (conditional orthogonality) we derive a natural instantiation.
And it turns out to be an old friend: Matching Pursuit!
📄 arxiv.org/abs/2506.03093
See you in San Diego,
@neuripsconf.bsky.social
🎉
#interpretability
From observed phenomena in representations (conditional orthogonality) we derive a natural instantiation.
And it turns out to be an old friend: Matching Pursuit!
📄 arxiv.org/abs/2506.03093
See you in San Diego,
@neuripsconf.bsky.social
🎉
#interpretability

From Flat to Hierarchical: Extracting Sparse Representations with Matching Pursuit
Motivated by the hypothesis that neural network representations encode abstract, interpretable features as linearly accessible, approximately orthogonal directions, sparse autoencoders (SAEs) have bec...
arxiv.org
September 28, 2025 at 2:01 PM
Phenomenology → principle → method.
From observed phenomena in representations (conditional orthogonality) we derive a natural instantiation.
And it turns out to be an old friend: Matching Pursuit!
📄 arxiv.org/abs/2506.03093
See you in San Diego,
@neuripsconf.bsky.social
🎉
#interpretability
From observed phenomena in representations (conditional orthogonality) we derive a natural instantiation.
And it turns out to be an old friend: Matching Pursuit!
📄 arxiv.org/abs/2506.03093
See you in San Diego,
@neuripsconf.bsky.social
🎉
#interpretability
Reposted by Thomas Fel

🚨Our preprint is online!🚨
www.biorxiv.org/content/10.1...
How do #dopamine neurons perform the key calculations in reinforcement #learning?
Read on to find out more! 🧵
www.biorxiv.org/content/10.1...
How do #dopamine neurons perform the key calculations in reinforcement #learning?
Read on to find out more! 🧵
September 19, 2025 at 1:05 PM
🚨Our preprint is online!🚨
www.biorxiv.org/content/10.1...
How do #dopamine neurons perform the key calculations in reinforcement #learning?
Read on to find out more! 🧵
www.biorxiv.org/content/10.1...
How do #dopamine neurons perform the key calculations in reinforcement #learning?
Read on to find out more! 🧵
Reposted by Thomas Fel

Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695

September 17, 2025 at 7:12 PM
Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
Check out our COLM 2025 (oral) 🎤
SAEs reveal that VLM embedding spaces aren’t just "image vs. text" cones.
They contain stable conceptual directions, some forming surprising bridges across modalities.
arxiv.org/abs/2504.11695
Demo 👉 vlm-concept-visualization.com
SAEs reveal that VLM embedding spaces aren’t just "image vs. text" cones.
They contain stable conceptual directions, some forming surprising bridges across modalities.
arxiv.org/abs/2504.11695
Demo 👉 vlm-concept-visualization.com

September 17, 2025 at 7:42 PM
Check out our COLM 2025 (oral) 🎤
SAEs reveal that VLM embedding spaces aren’t just "image vs. text" cones.
They contain stable conceptual directions, some forming surprising bridges across modalities.
arxiv.org/abs/2504.11695
Demo 👉 vlm-concept-visualization.com
SAEs reveal that VLM embedding spaces aren’t just "image vs. text" cones.
They contain stable conceptual directions, some forming surprising bridges across modalities.
arxiv.org/abs/2504.11695
Demo 👉 vlm-concept-visualization.com
Reposted by Thomas Fel
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
coginterp.github.io
July 16, 2025 at 1:08 PM
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Reposted by Thomas Fel

How do language models generalize from information they learn in-context vs. via finetuning? In arxiv.org/abs/2505.00661 we show that in-context learning can generalize more flexibly, illustrating key differences in the inductive biases of these modes of learning — and ways to improve finetuning. 1/
arxiv.org
May 2, 2025 at 5:02 PM
How do language models generalize from information they learn in-context vs. via finetuning? In arxiv.org/abs/2505.00661 we show that in-context learning can generalize more flexibly, illustrating key differences in the inductive biases of these modes of learning — and ways to improve finetuning. 1/
Reposted by Thomas Fel

Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
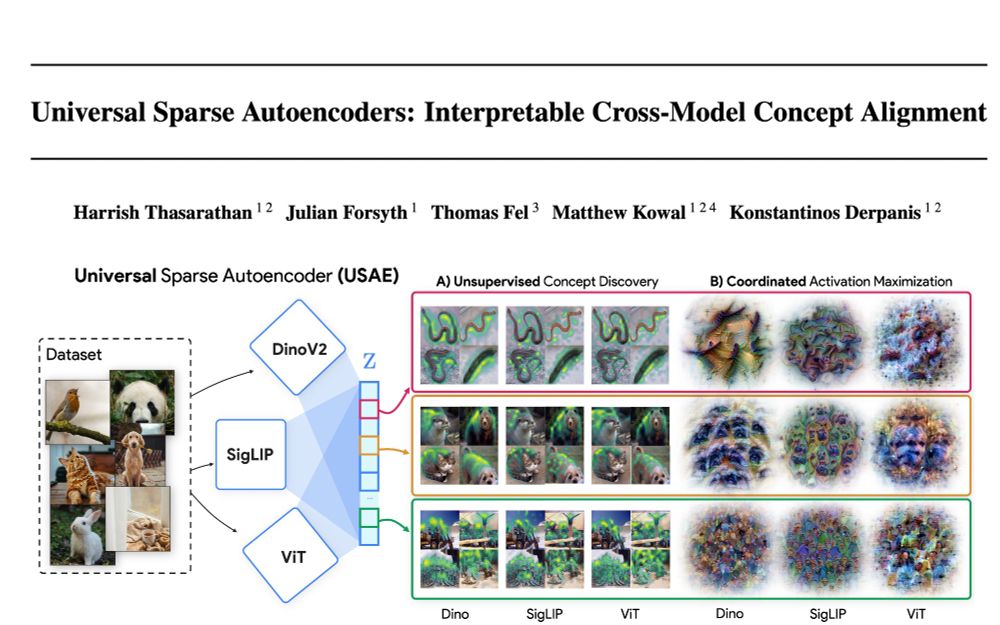
May 1, 2025 at 10:57 PM
Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
Reposted by Thomas Fel

Accepted at #ICML2025! Check out the preprint.
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
May 1, 2025 at 3:03 PM
Accepted at #ICML2025! Check out the preprint.
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social