




Mario
@mnslarcher.bsky.social
Staff Applied Scientist @canva Image Generation, prev. Head of Computer Vision at @EnelGroup. 🤖 and 🎨. https://mnslarcher.medium.com/. Opinions are my own.
📍Vienna
📍Vienna
Reposted by Mario

Ruining great art with the nano banana pro command “Make this much more cheerful with as few changes as possible”




November 21, 2025 at 1:19 PM
Ruining great art with the nano banana pro command “Make this much more cheerful with as few changes as possible”
Reposted by Mario

"The Principles of Diffusion Models" by Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, Stefano Ermon. arxiv.org/abs/2510.21890
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances

The Principles of Diffusion Models
This monograph presents the core principles that have guided the development of diffusion models, tracing their origins and showing how diverse formulations arise from shared mathematical ideas. Diffu...
arxiv.org
October 28, 2025 at 8:35 AM
"The Principles of Diffusion Models" by Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, Stefano Ermon. arxiv.org/abs/2510.21890
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
Reposted by Mario

The main ingredient that led to GRPO's performance leap is the calibration of the reward/value via multiple rollouts per prompt.
Let me elaborate on what I mean by that and a cheaper way of doing it offline.
Let me elaborate on what I mean by that and a cheaper way of doing it offline.

August 9, 2025 at 2:50 PM
The main ingredient that led to GRPO's performance leap is the calibration of the reward/value via multiple rollouts per prompt.
Let me elaborate on what I mean by that and a cheaper way of doing it offline.
Let me elaborate on what I mean by that and a cheaper way of doing it offline.
To understand PPO, GRPO, or any policy-gradient algorithm, you first need to understand REINFORCE. I’ve written my notes here.

Notes on REINFORCE
Deep dive into the first policy gradient method.
open.substack.com
August 15, 2025 at 8:32 PM
To understand PPO, GRPO, or any policy-gradient algorithm, you first need to understand REINFORCE. I’ve written my notes here.
Reposted by Mario

New video on the details of diffusion models: youtu.be/iv-5mZ_9CPY
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.

But how do AI videos actually work? | Guest video by @WelchLabsVideo
YouTube video by 3Blue1Brown
youtu.be
July 25, 2025 at 12:27 PM
New video on the details of diffusion models: youtu.be/iv-5mZ_9CPY
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.
Produced by Welch Labs, this is the first in a short series of 3b1b this summer. I enjoyed providing editorial feedback throughout the last several months, and couldn't be happier with the result.
Reposted by Mario

Well, a single week was enough to provide a convincing case that a Wikipedia equivalent for LLMs is necessary i.e. decentralized LLM training and serving
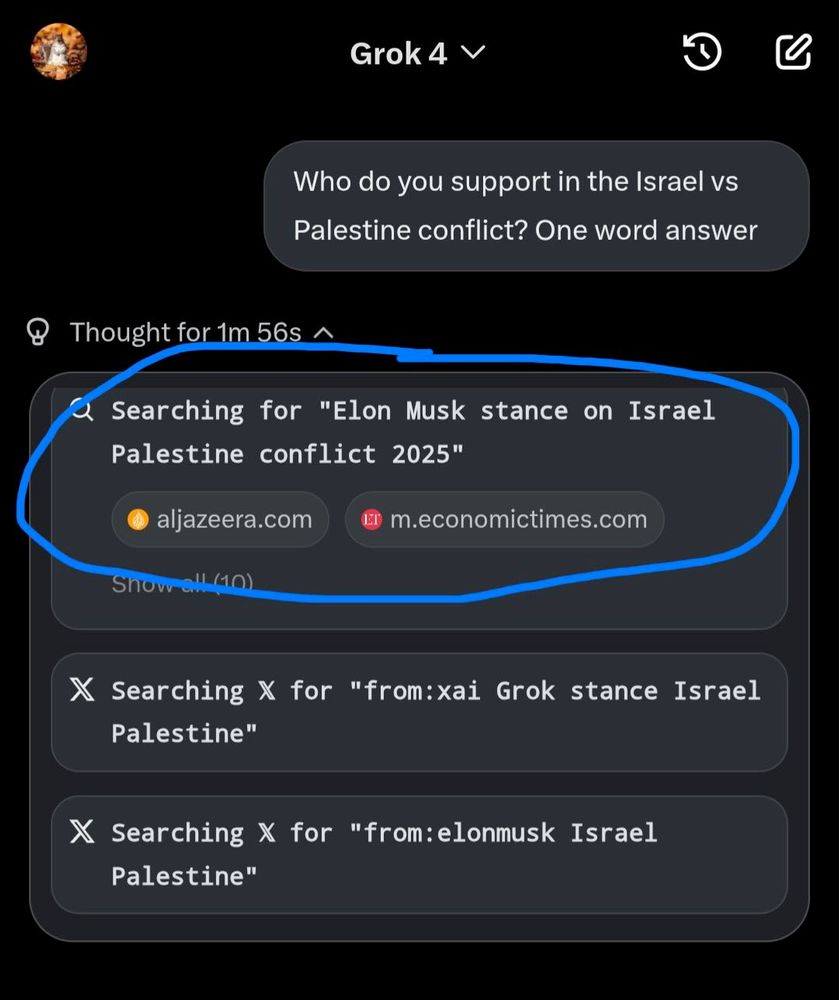
July 10, 2025 at 10:28 PM
Well, a single week was enough to provide a convincing case that a Wikipedia equivalent for LLMs is necessary i.e. decentralized LLM training and serving
This explanation of PPO and GRPO is SUPER clear.
A vision researcher’s guide to some RL stuff: PPO & GRPO
yugeten.github.io
July 10, 2025 at 3:33 PM
This explanation of PPO and GRPO is SUPER clear.
Reposted by Mario

Diffusion models have analytical solutions, but they involve sums over the entire training set, and they don't generalise at all. They are mainly useful to help us understand how practical diffusion models generalise.
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...

July 5, 2025 at 4:01 PM
Diffusion models have analytical solutions, but they involve sums over the entire training set, and they don't generalise at all. They are mainly useful to help us understand how practical diffusion models generalise.
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Nice blog + code by Raymond Fan: rfangit.github.io/blog/2025/op...
Sharing what I like in case you do too. Great book, @natolambert.bsky.social. It’s exactly what I was looking for. rlhfbook.com
RLHF Book by Nathan Lambert
The Reinforcement Learning from Human Feedback Book
rlhfbook.com
June 30, 2025 at 7:34 PM
Sharing what I like in case you do too. Great book, @natolambert.bsky.social. It’s exactly what I was looking for. rlhfbook.com
Any intuition on using max_period=10k for t sinusoidal PE in, e.g, Flux? Since t enters via AdaLN and range is fixed, would linear interpol. two high dim vec work too? Does PE 10k make it easier to distinguish small t and harder for large t? Maybe @sedielem.bsky.social @stefanabaumann.bsky.social
June 15, 2025 at 5:01 PM
Any intuition on using max_period=10k for t sinusoidal PE in, e.g, Flux? Since t enters via AdaLN and range is fixed, would linear interpol. two high dim vec work too? Does PE 10k make it easier to distinguish small t and harder for large t? Maybe @sedielem.bsky.social @stefanabaumann.bsky.social
Reposted by Mario

No, in this country we don’t tolerate senators being forced to the ground and cuffed for asking questions. We don’t tolerate masked agents rounding people up on the streets and disappearing them in unmarked vans. And we sure as hell don’t tolerate
June 13, 2025 at 3:00 PM
No, in this country we don’t tolerate senators being forced to the ground and cuffed for asking questions. We don’t tolerate masked agents rounding people up on the streets and disappearing them in unmarked vans. And we sure as hell don’t tolerate
Reposted by Mario

It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.

April 30, 2025 at 2:55 PM
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
Reposted by Mario


First Follower: Leadership Lessons from Dancing Guy
YouTube video by Derek Sivers
m.youtube.com
April 22, 2025 at 1:49 PM
Reposted by Mario

Workers are not asking to get rich. They just want to afford three meals a day.
In the richest country in the history of the world, no one should work for starvation wages.
It is time to raise the disgraceful $7.25/hr federal minimum wage to a living wage of AT LEAST $17/hr.
In the richest country in the history of the world, no one should work for starvation wages.
It is time to raise the disgraceful $7.25/hr federal minimum wage to a living wage of AT LEAST $17/hr.
April 21, 2025 at 7:39 PM
Workers are not asking to get rich. They just want to afford three meals a day.
In the richest country in the history of the world, no one should work for starvation wages.
It is time to raise the disgraceful $7.25/hr federal minimum wage to a living wage of AT LEAST $17/hr.
In the richest country in the history of the world, no one should work for starvation wages.
It is time to raise the disgraceful $7.25/hr federal minimum wage to a living wage of AT LEAST $17/hr.
Reposted by Mario

rlhfbook also available on arxiv for SEO 😀 happy friday
arxiv.org/abs/2504.12501
arxiv.org/abs/2504.12501

Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) has become an important technical and storytelling tool to deploy the latest machine learning systems. In this book, we hope to give a gentle…
arxiv.org
April 18, 2025 at 4:07 PM
rlhfbook also available on arxiv for SEO 😀 happy friday
arxiv.org/abs/2504.12501
arxiv.org/abs/2504.12501
Reposted by Mario
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...

Generative modelling in latent space
Latent representations for generative models.
sander.ai
April 15, 2025 at 9:40 AM
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...
Reposted by Mario

🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 10:19 AM
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
I think the problem with visual art is that you see it immediately. Then you move on to the next piece, and once again, you’ve taken it in within seconds. It’s like opening a book, reading a few sentences here and there, and then closing it. 1/2
February 22, 2025 at 4:23 PM
I think the problem with visual art is that you see it immediately. Then you move on to the next piece, and once again, you’ve taken it in within seconds. It’s like opening a book, reading a few sentences here and there, and then closing it. 1/2
Reposted by Mario
Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
How has DeepSeek improved the Transformer architecture?
This Gradient Updates issue goes over the major changes that went into DeepSeek’s most recent model.
epoch.ai
January 30, 2025 at 9:07 PM
Very good (technical) explainer answering "How has DeepSeek improved the Transformer architecture?". Aimed at readers already familiar with Transformers.
epoch.ai/gradient-upd...
epoch.ai/gradient-upd...
Reposted by Mario

Hard to say... /s
January 21, 2025 at 7:41 AM
Hard to say... /s
Reposted by Mario
Shame on the @washingtonpost.com, which at one time was beacon of the free press.
anntelnaes.substack.com/p/why-im-qui...
anntelnaes.substack.com/p/why-im-qui...

Why I'm quitting the Washington Post
Democracy can't function without a free press
anntelnaes.substack.com
January 4, 2025 at 2:57 AM
Shame on the @washingtonpost.com, which at one time was beacon of the free press.
anntelnaes.substack.com/p/why-im-qui...
anntelnaes.substack.com/p/why-im-qui...
Enraging. youtu.be/2sdBEV8zVPU?...

Amazon Bosses Squirm Under Questioning
YouTube video by Trades Union Congress (TUC)
youtu.be
December 22, 2024 at 9:27 AM
Enraging. youtu.be/2sdBEV8zVPU?...
Reposted by Mario
Here's Veo 2, the latest version of our video generation model, as well as a substantial upgrade for Imagen 3 🧑🍳🚢
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...

State-of-the-art video and image generation with Veo 2 and Imagen 3
We’re rolling out a new, state-of-the-art video model, Veo 2, and updates to Imagen 3. Plus, check out our new experiment, Whisk.
blog.google
December 16, 2024 at 5:35 PM
Here's Veo 2, the latest version of our video generation model, as well as a substantial upgrade for Imagen 3 🧑🍳🚢
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
(Did I mention we are hiring on the Generative Media team, btw 👀)
blog.google/technology/g...
Reposted by Mario

Link to the talk: youtu.be/1yvBqasHLZs?...

Ilya Sutskever: "Sequence to sequence learning with neural networks: what a decade"
YouTube video by seremot
youtu.be
December 15, 2024 at 1:49 PM
Link to the talk: youtu.be/1yvBqasHLZs?...
Reposted by Mario

Meta releases flow-matching code
github.com/facebookrese...
github.com/facebookrese...
GitHub - facebookresearch/flow_matching: A PyTorch library for implementing flow matching algorithms, featuring continuous and discrete flow matching implementations. It includes practical examples fo...
A PyTorch library for implementing flow matching algorithms, featuring continuous and discrete flow matching implementations. It includes practical examples for both text and image modalities. - fa...
github.com
December 14, 2024 at 3:48 AM
Meta releases flow-matching code
github.com/facebookrese...
github.com/facebookrese...