



Gaspard Lambrechts
@gsprd.be
PhD Student doing RL in POMDP at the University of Liège - Intern at McGill - gsprd.be
At #EWRL, we presented 4 papers, which we summarize below.
- A Theoretical Justification for AsymAC Algorithms.
- Informed AsymAC: Theoretical Insights and Open Questions.
- Behind the Myth of Exploration in Policy Gradients.
- Off-Policy MaxEntRL with Future State-Action Visitation Measures.
- A Theoretical Justification for AsymAC Algorithms.
- Informed AsymAC: Theoretical Insights and Open Questions.
- Behind the Myth of Exploration in Policy Gradients.
- Off-Policy MaxEntRL with Future State-Action Visitation Measures.
October 6, 2025 at 9:50 AM
At #EWRL, we presented 4 papers, which we summarize below.
- A Theoretical Justification for AsymAC Algorithms.
- Informed AsymAC: Theoretical Insights and Open Questions.
- Behind the Myth of Exploration in Policy Gradients.
- Off-Policy MaxEntRL with Future State-Action Visitation Measures.
- A Theoretical Justification for AsymAC Algorithms.
- Informed AsymAC: Theoretical Insights and Open Questions.
- Behind the Myth of Exploration in Policy Gradients.
- Off-Policy MaxEntRL with Future State-Action Visitation Measures.
Reposted by Gaspard Lambrechts

Had an amazing time presenting my research @cohereforai.bsky.social yesterday 🎤
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...

Théo Vincent - Optimizing the Learning Trajectory of Reinforcement Learning Agents
YouTube video by Cohere
youtu.be
July 19, 2025 at 7:42 AM
Had an amazing time presenting my research @cohereforai.bsky.social yesterday 🎤
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...
In case you could not attend, feel free to check it out 👉
youtu.be/RCA22JWiiY8?...
Reposted by Gaspard Lambrechts

Such an inspiring talk by @arkrause.bsky.social at #ICML today. The role of efficient exploration in Scientific discovery is fundamental and I really like how Andreas connects the dots with RL (theory).

July 17, 2025 at 10:14 PM
Such an inspiring talk by @arkrause.bsky.social at #ICML today. The role of efficient exploration in Scientific discovery is fundamental and I really like how Andreas connects the dots with RL (theory).
At #ICML2025, we will present a theoretical justification for the benefits of « asymmetric actor-critic » algorithms (#W1008 Wednesday at 11am).
📝 Paper: hdl.handle.net/2268/326874
💻 Blog: damien-ernst.be/2025/06/10/a...
📝 Paper: hdl.handle.net/2268/326874
💻 Blog: damien-ernst.be/2025/06/10/a...

July 16, 2025 at 2:32 PM
At #ICML2025, we will present a theoretical justification for the benefits of « asymmetric actor-critic » algorithms (#W1008 Wednesday at 11am).
📝 Paper: hdl.handle.net/2268/326874
💻 Blog: damien-ernst.be/2025/06/10/a...
📝 Paper: hdl.handle.net/2268/326874
💻 Blog: damien-ernst.be/2025/06/10/a...
Reposted by Gaspard Lambrechts

🌟🌟Good news for the explorers🗺️!
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
July 8, 2025 at 2:05 PM
🌟🌟Good news for the explorers🗺️!
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
Next week we will present our paper “Enhancing Diversity in Parallel Agents: A Maximum Exploration Story” with V. De Paola, @mircomutti.bsky.social and M. Restelli at @icmlconf.bsky.social!
(1/N)
Last week, I gave an invited talk on "asymmetric reinforcement learning" at the BeNeRL workshop. I was happy to draw attention to this niche topic, which I think can be useful to any reinforcement learning researcher.
Slides: hdl.handle.net/2268/333931.
Slides: hdl.handle.net/2268/333931.

July 11, 2025 at 9:22 AM
Last week, I gave an invited talk on "asymmetric reinforcement learning" at the BeNeRL workshop. I was happy to draw attention to this niche topic, which I think can be useful to any reinforcement learning researcher.
Slides: hdl.handle.net/2268/333931.
Slides: hdl.handle.net/2268/333931.
Two months after my PhD defense on RL in POMDP, I finally uploaded the final version of my thesis :)
You can find it here: hdl.handle.net/2268/328700 (manuscript and slides).
Many thanks to my advisors and to the jury members.
You can find it here: hdl.handle.net/2268/328700 (manuscript and slides).
Many thanks to my advisors and to the jury members.

June 13, 2025 at 11:44 AM
Two months after my PhD defense on RL in POMDP, I finally uploaded the final version of my thesis :)
You can find it here: hdl.handle.net/2268/328700 (manuscript and slides).
Many thanks to my advisors and to the jury members.
You can find it here: hdl.handle.net/2268/328700 (manuscript and slides).
Many thanks to my advisors and to the jury members.
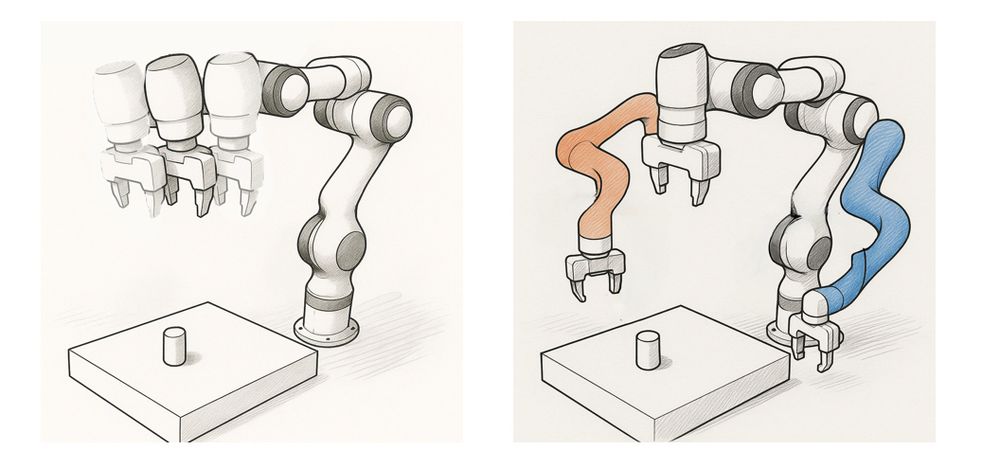
📝 Our paper "A Theoretical Justification for Asymmetric Actor-Critic Algorithms" was accepted at #ICML!
Never heard of "asymmetric actor-critic" algorithms? Yet, many successful #RL applications use them (see image).
But these algorithms are not fully understood. Below, we provide some insights.
Never heard of "asymmetric actor-critic" algorithms? Yet, many successful #RL applications use them (see image).
But these algorithms are not fully understood. Below, we provide some insights.

June 9, 2025 at 2:43 PM
Reposted by Gaspard Lambrechts

📢 Deadline extended!
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/

May 26, 2025 at 2:47 PM
📢 Deadline extended!
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Slydst, my Typst package for making simple slides, just got its 100th star on Github.
While I would not advise using Typst for papers yet, its markdown-like syntax allows to create slides in a few minutes, while supporting everything we love from LaTeX: equations.
github.com/glambrechts/...
While I would not advise using Typst for papers yet, its markdown-like syntax allows to create slides in a few minutes, while supporting everything we love from LaTeX: equations.
github.com/glambrechts/...

April 3, 2025 at 1:51 PM
Slydst, my Typst package for making simple slides, just got its 100th star on Github.
While I would not advise using Typst for papers yet, its markdown-like syntax allows to create slides in a few minutes, while supporting everything we love from LaTeX: equations.
github.com/glambrechts/...
While I would not advise using Typst for papers yet, its markdown-like syntax allows to create slides in a few minutes, while supporting everything we love from LaTeX: equations.
github.com/glambrechts/...
Reposted by Gaspard Lambrechts

📣 Hiring! I am looking for PhD/postdoc candidates to work on foundation models for science at @ULiege, with a special focus on weather and climate systems. 🌏 Three positions are open around deep learning, physics-informed FMs and inverse problems with FMs.
December 30, 2024 at 12:21 PM
📣 Hiring! I am looking for PhD/postdoc candidates to work on foundation models for science at @ULiege, with a special focus on weather and climate systems. 🌏 Three positions are open around deep learning, physics-informed FMs and inverse problems with FMs.
Reposted by Gaspard Lambrechts

Check our work on max entropy RL! We introduce an off-policy method to maximize the entropy of the future state-action visitation distribution, leading to policies that explore effectively and achieve high performance 🎯
Link 📑 arxiv.org/abs/2412.06655
#RL #MaxEntRL #Exploration
Link 📑 arxiv.org/abs/2412.06655
#RL #MaxEntRL #Exploration

Off-Policy Maximum Entropy RL with Future State and Action Visitation Measures
We introduce a new maximum entropy reinforcement learning framework based on the distribution of states and actions visited by a policy. More precisely, an intrinsic reward function is added to the re...
arxiv.org
December 13, 2024 at 9:22 AM
Check our work on max entropy RL! We introduce an off-policy method to maximize the entropy of the future state-action visitation distribution, leading to policies that explore effectively and achieve high performance 🎯
Link 📑 arxiv.org/abs/2412.06655
#RL #MaxEntRL #Exploration
Link 📑 arxiv.org/abs/2412.06655
#RL #MaxEntRL #Exploration
How come I didn't know about this BeNeRL seminar series? It focuses on practical RL and seems really great!
www.benerl.org/seminar-seri...
I would have loved to hear Benjamin Eysenbach, Chris Lu and Edward Hu... Next one is on December 19th.
www.benerl.org/seminar-seri...
I would have loved to hear Benjamin Eysenbach, Chris Lu and Edward Hu... Next one is on December 19th.
December 3, 2024 at 4:11 PM
How come I didn't know about this BeNeRL seminar series? It focuses on practical RL and seems really great!
www.benerl.org/seminar-seri...
I would have loved to hear Benjamin Eysenbach, Chris Lu and Edward Hu... Next one is on December 19th.
www.benerl.org/seminar-seri...
I would have loved to hear Benjamin Eysenbach, Chris Lu and Edward Hu... Next one is on December 19th.
Hi Bluesky! I'm a PhD student researching #RL in #POMDP.
If you're also interested in:
- sequence models,
- world models,
- representation learning,
- asymmetric learning,
- generalization,
I'd love to connect, chat, or check out your work! Feel free to reply or message me.
If you're also interested in:
- sequence models,
- world models,
- representation learning,
- asymmetric learning,
- generalization,
I'd love to connect, chat, or check out your work! Feel free to reply or message me.
November 26, 2024 at 4:30 PM