




Kuzman Ganchev
@ganchev.bsky.social
Research Scientist at GoogleDeepMind (formerly at Google Research). UPenn graduate.
Reposted by Kuzman Ganchev

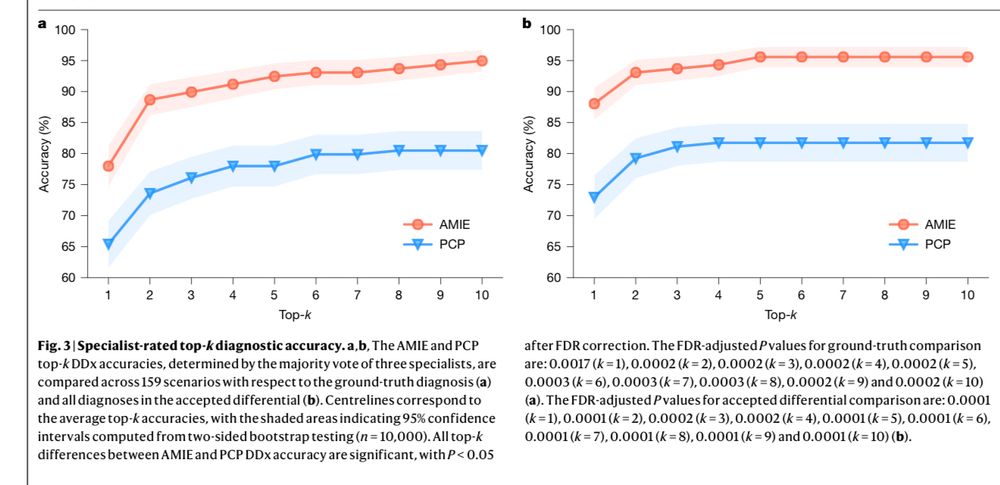
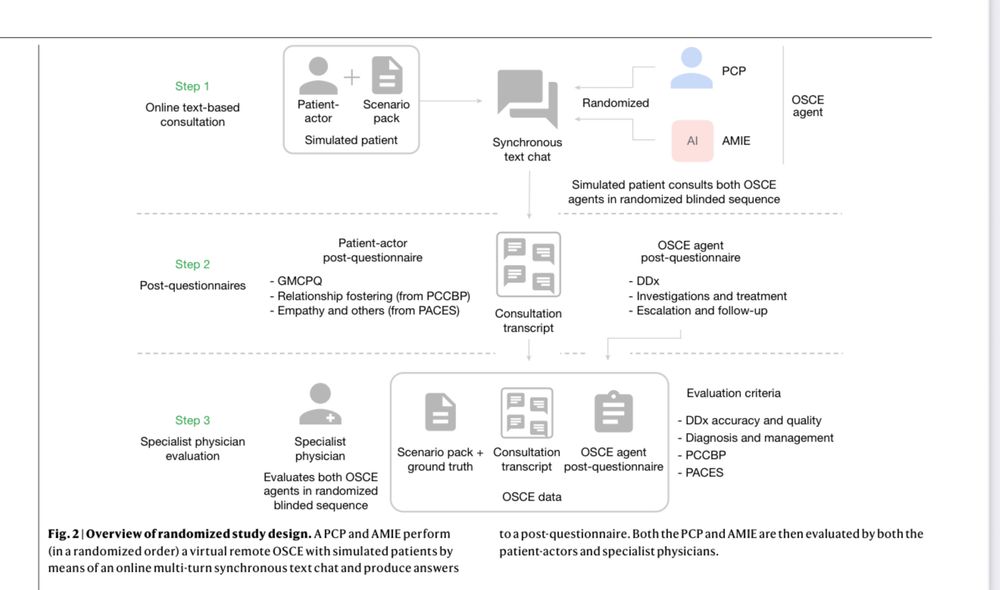
Study in Nature: “Across 30 out of 32 evaluation axes from the specialist physician perspective & 25 out of 26 evaluation axes from the patient-actor perspective, AMIE [Google Medical LLM] was rated superior to PCPs [primary care docs] while being non-inferior on the rest.”
(& AIME is an older LLM)
(& AIME is an older LLM)

May 4, 2025 at 1:27 PM
Study in Nature: “Across 30 out of 32 evaluation axes from the specialist physician perspective & 25 out of 26 evaluation axes from the patient-actor perspective, AMIE [Google Medical LLM] was rated superior to PCPs [primary care docs] while being non-inferior on the rest.”
(& AIME is an older LLM)
(& AIME is an older LLM)
Reposted by Kuzman Ganchev

Gemma 3 explained: Longer context, image support, and a new 1B model. → goo.gle/4lV8iaw
Other key enhancements:
🔸 Best model that fits in a single consumer GPU or TPU host
🔸 KV-cache memory reduction with 5-to-1 interleaved attention
🔸 And more!
Read the blog for the full details on Gemma 3.
Other key enhancements:
🔸 Best model that fits in a single consumer GPU or TPU host
🔸 KV-cache memory reduction with 5-to-1 interleaved attention
🔸 And more!
Read the blog for the full details on Gemma 3.
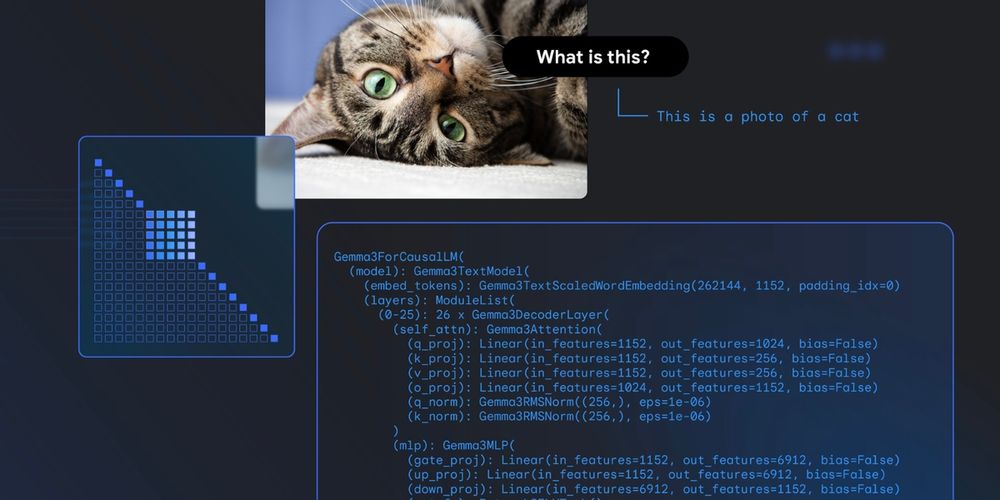
Gemma explained: What’s new in Gemma 3- Google Developers Blog
Google's Gemma 3 model includes vision-language support and architectural changes for resource-friendly multimodal language models.
goo.gle
April 30, 2025 at 9:46 PM
Gemma 3 explained: Longer context, image support, and a new 1B model. → goo.gle/4lV8iaw
Other key enhancements:
🔸 Best model that fits in a single consumer GPU or TPU host
🔸 KV-cache memory reduction with 5-to-1 interleaved attention
🔸 And more!
Read the blog for the full details on Gemma 3.
Other key enhancements:
🔸 Best model that fits in a single consumer GPU or TPU host
🔸 KV-cache memory reduction with 5-to-1 interleaved attention
🔸 And more!
Read the blog for the full details on Gemma 3.
There's a link to a really nice interactive viewer for a sample of the data (will only make sense after you read the post). There's some examples that I would have expected (where something is implied but not directly stated) but also a surprising number of kind of topical things.

We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus!
medium.com/people-ai-re...
medium.com/people-ai-re...

December 17, 2024 at 4:12 PM
There's a link to a really nice interactive viewer for a sample of the data (will only make sense after you read the post). There's some examples that I would have expected (where something is implied but not directly stated) but also a surprising number of kind of topical things.
Reposted by Kuzman Ganchev

Want to get started using PaliGemma 2?
🎤 developers.googleblog.com/en/introduci...
🤗 huggingface.co/blog/paligem...
💾 kaggle.com/models/googl...
🔧 github.com/google-resea...
7/7
🎤 developers.googleblog.com/en/introduci...
🤗 huggingface.co/blog/paligem...
💾 kaggle.com/models/googl...
🔧 github.com/google-resea...
7/7
December 5, 2024 at 6:19 PM
Want to get started using PaliGemma 2?
🎤 developers.googleblog.com/en/introduci...
🤗 huggingface.co/blog/paligem...
💾 kaggle.com/models/googl...
🔧 github.com/google-resea...
7/7
🎤 developers.googleblog.com/en/introduci...
🤗 huggingface.co/blog/paligem...
💾 kaggle.com/models/googl...
🔧 github.com/google-resea...
7/7
Wanted to share that Varun Godbole recently released a prompting playbook. The title says prompt tuning, but this is text prompts, not soft prompts.
github.com/varungodbole...
github.com/varungodbole...

GitHub - varungodbole/prompt-tuning-playbook: A playbook for effectively prompting post-trained LLMs
A playbook for effectively prompting post-trained LLMs - varungodbole/prompt-tuning-playbook
github.com
November 11, 2024 at 3:51 PM
Wanted to share that Varun Godbole recently released a prompting playbook. The title says prompt tuning, but this is text prompts, not soft prompts.
github.com/varungodbole...
github.com/varungodbole...
Reposted by Kuzman Ganchev

I’m pretty excited about this one!
ALTA is A Language for Transformer Analysis.
Because ALTA programs can be compiled to transformer weights, it provides constructive proofs of transformer expressivity. It also offers new analytic tools for *learnability*.
arxiv.org/abs/2410.18077
ALTA is A Language for Transformer Analysis.
Because ALTA programs can be compiled to transformer weights, it provides constructive proofs of transformer expressivity. It also offers new analytic tools for *learnability*.
arxiv.org/abs/2410.18077

ALTA: Compiler-Based Analysis of Transformers
We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lin...
arxiv.org
October 24, 2024 at 3:31 AM
I’m pretty excited about this one!
ALTA is A Language for Transformer Analysis.
Because ALTA programs can be compiled to transformer weights, it provides constructive proofs of transformer expressivity. It also offers new analytic tools for *learnability*.
arxiv.org/abs/2410.18077
ALTA is A Language for Transformer Analysis.
Because ALTA programs can be compiled to transformer weights, it provides constructive proofs of transformer expressivity. It also offers new analytic tools for *learnability*.
arxiv.org/abs/2410.18077
Not news, but I recently saw the zed.dev demo and it looks amazing. Has anyone used it or something similar?

Zed - The editor for what's next
Zed is a high-performance, multiplayer code editor from the creators of Atom and Tree-sitter.
zed.dev
October 25, 2024 at 2:43 PM
Not news, but I recently saw the zed.dev demo and it looks amazing. Has anyone used it or something similar?