



Tyler Chang
@tylerachang.bsky.social
Pinned
Tyler Chang
@tylerachang.bsky.social
· Dec 13

We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus!
medium.com/people-ai-re...
medium.com/people-ai-re...
Very very excited that Global PIQA is out! This was an incredible effort by 300+ researchers from 65 countries. The resulting dataset is a high-quality, participatory, and culturally-specific benchmark for over 100 languages.
Introducing Global PIQA, a new multilingual benchmark for 100+ languages. This benchmark is the outcome of this year’s MRL shared task, in collaboration with 300+ researchers from 65 countries. This dataset evaluates physical commonsense reasoning in culturally relevant contexts.

October 29, 2025 at 4:08 PM
Very very excited that Global PIQA is out! This was an incredible effort by 300+ researchers from 65 countries. The resulting dataset is a high-quality, participatory, and culturally-specific benchmark for over 100 languages.
Reposted by Tyler Chang

Did you know?
❌77% of language models on @hf.co are not tagged for any language
📈For 95% of languages, most models are multilingual
🚨88% of models with tags are trained on English
In a new blog post, @tylerachang.bsky.social and I dig into these trends and why they matter! 👇
❌77% of language models on @hf.co are not tagged for any language
📈For 95% of languages, most models are multilingual
🚨88% of models with tags are trained on English
In a new blog post, @tylerachang.bsky.social and I dig into these trends and why they matter! 👇
September 19, 2025 at 2:53 PM
Did you know?
❌77% of language models on @hf.co are not tagged for any language
📈For 95% of languages, most models are multilingual
🚨88% of models with tags are trained on English
In a new blog post, @tylerachang.bsky.social and I dig into these trends and why they matter! 👇
❌77% of language models on @hf.co are not tagged for any language
📈For 95% of languages, most models are multilingual
🚨88% of models with tags are trained on English
In a new blog post, @tylerachang.bsky.social and I dig into these trends and why they matter! 👇
Reposted by Tyler Chang

We have over 200 volunteers now for 90+ languages! We are hoping to expand the diversity of our language coverage and are still looking for participants who speak these languages. Check out how to get involved below, and please help us spread the word!

August 18, 2025 at 3:53 PM
We have over 200 volunteers now for 90+ languages! We are hoping to expand the diversity of our language coverage and are still looking for participants who speak these languages. Check out how to get involved below, and please help us spread the word!
Reposted by Tyler Chang
With six weeks left before the deadline, we have had over 50 volunteers sign up to contribute for over 30 languages. If you don’t see your language represented on the map, this is your sign to get involved!

August 5, 2025 at 3:13 PM
With six weeks left before the deadline, we have had over 50 volunteers sign up to contribute for over 30 languages. If you don’t see your language represented on the map, this is your sign to get involved!
We're organizing a shared task to develop a multilingual physical commonsense reasoning evaluation dataset! Details on how to submit are at: sigtyp.github.io/st2025-mrl.h...
June 25, 2025 at 3:28 AM
We're organizing a shared task to develop a multilingual physical commonsense reasoning evaluation dataset! Details on how to submit are at: sigtyp.github.io/st2025-mrl.h...
Presenting our work on training data attribution for pretraining this morning: iclr.cc/virtual/2025... -- come stop by in Hall 2/3 #526 if you're here at ICLR!
April 24, 2025 at 11:56 PM
Presenting our work on training data attribution for pretraining this morning: iclr.cc/virtual/2025... -- come stop by in Hall 2/3 #526 if you're here at ICLR!
We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus!
medium.com/people-ai-re...
medium.com/people-ai-re...
December 13, 2024 at 6:57 PM
We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus!
medium.com/people-ai-re...
medium.com/people-ai-re...
Reposted by Tyler Chang
The Goldfish models were trained on byte-premium-scaled dataset sizes, such that if a language needs more bytes to encode a given amount of information, we scaled up the dataset according the byte premium. Read about how we (@tylerachang.bsky.social) trained the models: arxiv.org/pdf/2408.10441
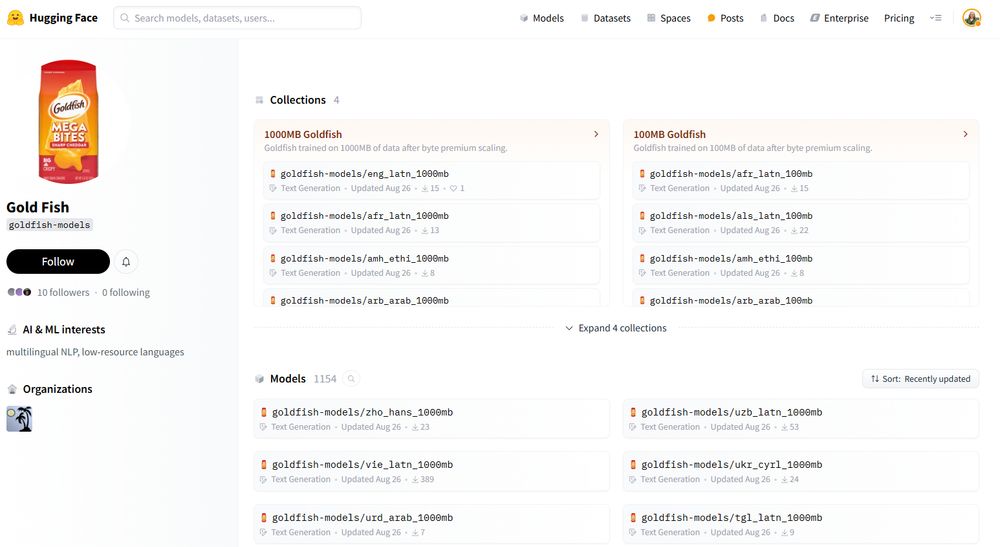
November 22, 2024 at 3:04 PM
The Goldfish models were trained on byte-premium-scaled dataset sizes, such that if a language needs more bytes to encode a given amount of information, we scaled up the dataset according the byte premium. Read about how we (@tylerachang.bsky.social) trained the models: arxiv.org/pdf/2408.10441
Reposted by Tyler Chang
Tyler Chang and my paper got awarded outstanding paper at #EMNLP2024! Thanks to the award committee for the recognition!

November 15, 2024 at 2:23 AM
Tyler Chang and my paper got awarded outstanding paper at #EMNLP2024! Thanks to the award committee for the recognition!