


Tyler Chang
@tylerachang.bsky.social
of course, there are some scenarios where you would want to really check all the training examples, e.g. for detecting data contamination, or for rare facts, etc.
April 25, 2025 at 2:44 PM
of course, there are some scenarios where you would want to really check all the training examples, e.g. for detecting data contamination, or for rare facts, etc.
I think you could still make interesting inferences about what *types* of training examples influence the target! You'd essentially be getting a sample of the actual top-k retrievals
April 25, 2025 at 2:43 PM
I think you could still make interesting inferences about what *types* of training examples influence the target! You'd essentially be getting a sample of the actual top-k retrievals
The biggest compute cost is computing gradients for every training example (~= cost of training) -- happy to chat more, especially if you know anyone interested in putting together an open-source implementation!
April 25, 2025 at 8:57 AM
The biggest compute cost is computing gradients for every training example (~= cost of training) -- happy to chat more, especially if you know anyone interested in putting together an open-source implementation!
And we hope you enjoy our paper: arxiv.org/abs/2410.17413
This work wouldn't have been at all possible without Dheeraj Rajagopal, Tolga Bolukbasi, @iislucas.bsky.social, and @iftenney.bsky.social !
This work wouldn't have been at all possible without Dheeraj Rajagopal, Tolga Bolukbasi, @iislucas.bsky.social, and @iftenney.bsky.social !

Scalable Influence and Fact Tracing for Large Language Model Pretraining
Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantl...
arxiv.org
December 13, 2024 at 6:57 PM
And we hope you enjoy our paper: arxiv.org/abs/2410.17413
This work wouldn't have been at all possible without Dheeraj Rajagopal, Tolga Bolukbasi, @iislucas.bsky.social, and @iftenney.bsky.social !
This work wouldn't have been at all possible without Dheeraj Rajagopal, Tolga Bolukbasi, @iislucas.bsky.social, and @iftenney.bsky.social !
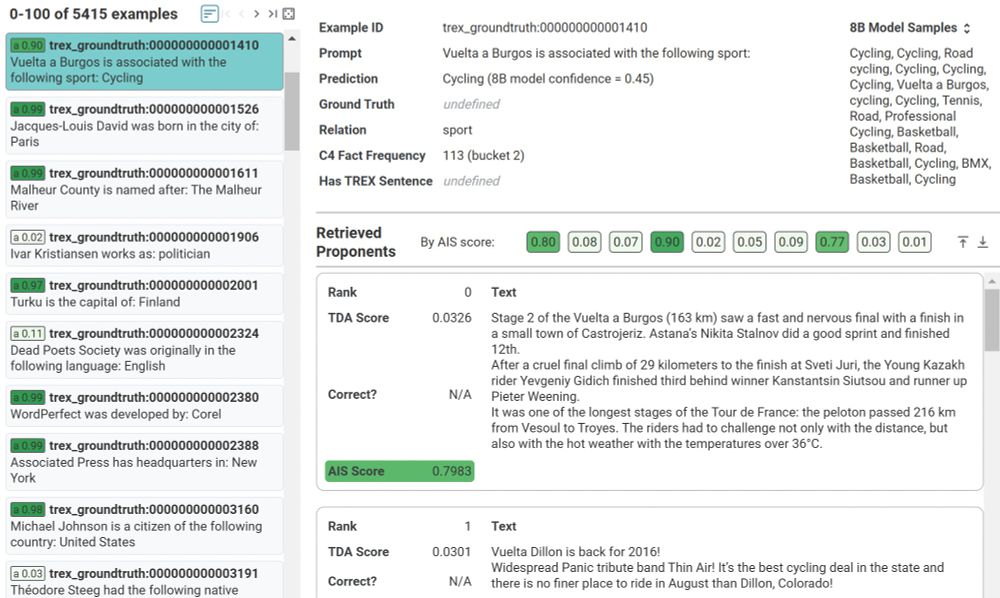
Play with it yourself: see influential pretraining examples from our method for facts, factual errors, commonsense reasoning, arithmetic, and open-ended generation: github.com/PAIR-code/pr...
December 13, 2024 at 6:57 PM
Play with it yourself: see influential pretraining examples from our method for facts, factual errors, commonsense reasoning, arithmetic, and open-ended generation: github.com/PAIR-code/pr...
As models increase in size and pretraining tokens, "influence" more closely resembles "attribution". I.e. "better" models do seem to rely more on entailing examples.
December 13, 2024 at 6:57 PM
As models increase in size and pretraining tokens, "influence" more closely resembles "attribution". I.e. "better" models do seem to rely more on entailing examples.
Many influential examples do not entail a fact, but instead appear to reflect priors on common entities for certain relation types, or guesses based on first or last names.
December 13, 2024 at 6:57 PM
Many influential examples do not entail a fact, but instead appear to reflect priors on common entities for certain relation types, or guesses based on first or last names.
In a fact tracing task, we find that classical retrieval methods (e.g. BM25) are still much better for retrieving examples that *entail* factual predictions (factual "attribution"), but TDA methods retrieve examples that have greater *influence* on model predictions.
December 13, 2024 at 6:57 PM
In a fact tracing task, we find that classical retrieval methods (e.g. BM25) are still much better for retrieving examples that *entail* factual predictions (factual "attribution"), but TDA methods retrieve examples that have greater *influence* on model predictions.
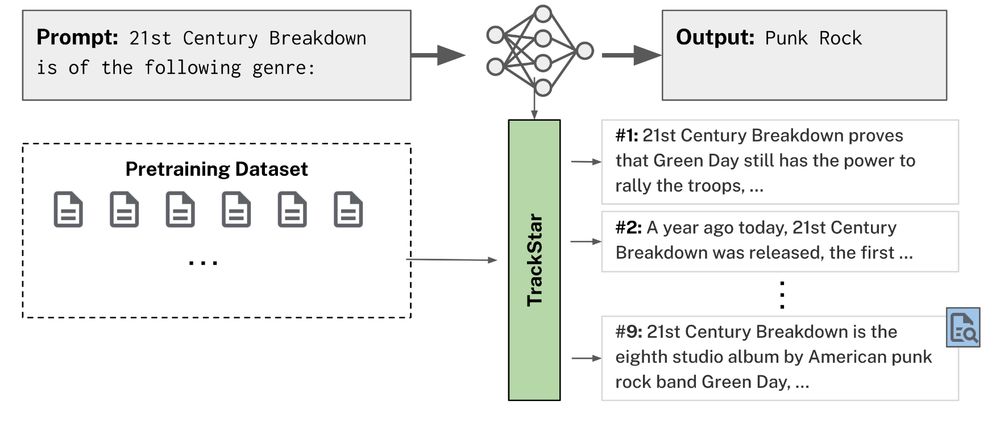
Our method, TrackStar, refines existing gradient-based approaches to scale to much larger settings: over 100x more queries and a 30x larger retrieval corpus than previous work at this model size.
December 13, 2024 at 6:57 PM
Our method, TrackStar, refines existing gradient-based approaches to scale to much larger settings: over 100x more queries and a 30x larger retrieval corpus than previous work at this model size.
Reposted by Tyler Chang

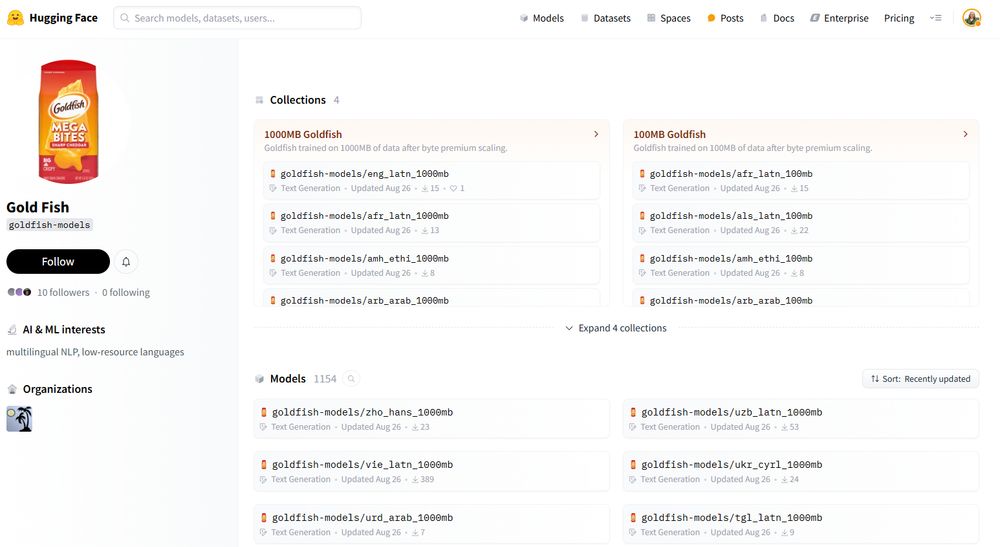
The Goldfish models were trained on byte-premium-scaled dataset sizes, such that if a language needs more bytes to encode a given amount of information, we scaled up the dataset according the byte premium. Read about how we (@tylerachang.bsky.social) trained the models: arxiv.org/pdf/2408.10441
November 22, 2024 at 3:04 PM
The Goldfish models were trained on byte-premium-scaled dataset sizes, such that if a language needs more bytes to encode a given amount of information, we scaled up the dataset according the byte premium. Read about how we (@tylerachang.bsky.social) trained the models: arxiv.org/pdf/2408.10441