



Andrew Severin
@andrewseverin.bsky.social
Andrew Severin manages the Genome Informatics Facility at Iowa State University. When he is not navigating the world of data and software, Andrew explores his passion for fantasy writing, hiking, ChatGPT and water polo.
Problem solving is by far the best part of being a manager of a bioinformatics core. I’ll be at PAG33 in San Diego this January. If you have an experiment you want to run by me or a tricky analysis you’re stuck on, let's meet up! 🧬 🖥️ hashtag#PAG33. Send me an gifhelp@iastate.edu!
December 18, 2025 at 4:44 PM
Problem solving is by far the best part of being a manager of a bioinformatics core. I’ll be at PAG33 in San Diego this January. If you have an experiment you want to run by me or a tricky analysis you’re stuck on, let's meet up! 🧬 🖥️ hashtag#PAG33. Send me an gifhelp@iastate.edu!
Genome annotation is an unsolved problem. All the current tools struggle predicting gene models due to the limitations of short reads. With long read data, annotation will improve but still limited to RNA expression under many conditions. Functional Annotation is similarly challenging 🧬 🖥️ #PAG33
December 17, 2025 at 3:55 PM
Genome annotation is an unsolved problem. All the current tools struggle predicting gene models due to the limitations of short reads. With long read data, annotation will improve but still limited to RNA expression under many conditions. Functional Annotation is similarly challenging 🧬 🖥️ #PAG33
Data analysis/discovery is the fun part but documentation is super important if not more important in bioinformatics. We use Github as our version controlled, searchable and sharable lab notebook to keep track of each project. The key to good project management adoption is a low barrier to entry.
December 16, 2025 at 3:46 PM
Data analysis/discovery is the fun part but documentation is super important if not more important in bioinformatics. We use Github as our version controlled, searchable and sharable lab notebook to keep track of each project. The key to good project management adoption is a low barrier to entry.
Bioinformatics rests on three pillars of knowledge: Biology, Sequencing Technology and Software. Not understanding the assumptions and limitations of these pillars as they relate to your project will reduce your ability to explore your data. 🧬 🖥️ #PAG33
December 15, 2025 at 3:06 PM
Bioinformatics rests on three pillars of knowledge: Biology, Sequencing Technology and Software. Not understanding the assumptions and limitations of these pillars as they relate to your project will reduce your ability to explore your data. 🧬 🖥️ #PAG33
When I first started learning Unix commands, learning how to explore file contents was very important. Now that I teach bioinformatics, I came up with a fun way to remember these commands: A `cat` has a `head` and a `tail`, `more` or `less`. 🧬 🖥️ #PAG33
December 12, 2025 at 7:36 PM
When I first started learning Unix commands, learning how to explore file contents was very important. Now that I teach bioinformatics, I came up with a fun way to remember these commands: A `cat` has a `head` and a `tail`, `more` or `less`. 🧬 🖥️ #PAG33
Reposted by Andrew Severin

🖥️🧬♀️I overheard a conversation guilty of youth and arrogance, saying there were not many women in bioinformatics besides Margaret Dayhoff (PAM). That is not only stupid but also wrong. Since my foundation years bioinformatics was always very female:
#WomenInBioinformatics #WomenInStem
#WomenInBioinformatics #WomenInStem

June 4, 2025 at 8:40 PM
🖥️🧬♀️I overheard a conversation guilty of youth and arrogance, saying there were not many women in bioinformatics besides Margaret Dayhoff (PAM). That is not only stupid but also wrong. Since my foundation years bioinformatics was always very female:
#WomenInBioinformatics #WomenInStem
#WomenInBioinformatics #WomenInStem
Reposted by Andrew Severin

From #OUP 's @bioinfoadv.bsky.social journal | Mars: simplifying #bioinformatics #workflows through a containerized approach to tool integration and management | #OpenScience #Singularity #Container 🧬 🖥️ 🧪 🔓
⬇️
academic.oup.com/bioinformati...
⬇️
academic.oup.com/bioinformati...

Mars: simplifying bioinformatics workflows through a containerized approach to tool integration and management
AbstractSummary. Bioinformatics is a rapidly evolving field with numerous specialized tools developed for essential genomic analysis tasks, such as read si
academic.oup.com
May 24, 2025 at 9:32 PM
From #OUP 's @bioinfoadv.bsky.social journal | Mars: simplifying #bioinformatics #workflows through a containerized approach to tool integration and management | #OpenScience #Singularity #Container 🧬 🖥️ 🧪 🔓
⬇️
academic.oup.com/bioinformati...
⬇️
academic.oup.com/bioinformati...
Reposted by Andrew Severin

A study from the Earlham Institute and @ox.ac.uk has generated ultra #longread @nanoporetech.com reads, to reveal the majority of the human #genome is replicated from dispersed initiation sites, with around 80% of the sites never reported before. 🖥️🧬
@conradn.bsky.social @drkarimgharbi.bsky.social
@conradn.bsky.social @drkarimgharbi.bsky.social

Starting point of DNA replication mystery solved
The question of where DNA replication starts in the human genome has finally been addressed, with the conclusion it is largely random.
buff.ly
May 12, 2025 at 10:40 AM
A study from the Earlham Institute and @ox.ac.uk has generated ultra #longread @nanoporetech.com reads, to reveal the majority of the human #genome is replicated from dispersed initiation sites, with around 80% of the sites never reported before. 🖥️🧬
@conradn.bsky.social @drkarimgharbi.bsky.social
@conradn.bsky.social @drkarimgharbi.bsky.social
Reposted by Andrew Severin

Whoa iqtree is finally up to version 3. It's setup in a separate github repo so if you rely on automated setup scripts (like I do) you'll have to make minor changes.
Time to run some tests to see if recent results remain consistent 💻🧬
github.com/iqtree/iqtree3
Time to run some tests to see if recent results remain consistent 💻🧬
github.com/iqtree/iqtree3

GitHub - iqtree/iqtree3: IQ-TREE version 3: software for phylogenetics
IQ-TREE version 3: software for phylogenetics. Contribute to iqtree/iqtree3 development by creating an account on GitHub.
github.com
May 9, 2025 at 10:52 PM
Whoa iqtree is finally up to version 3. It's setup in a separate github repo so if you rely on automated setup scripts (like I do) you'll have to make minor changes.
Time to run some tests to see if recent results remain consistent 💻🧬
github.com/iqtree/iqtree3
Time to run some tests to see if recent results remain consistent 💻🧬
github.com/iqtree/iqtree3
Reposted by Andrew Severin

Are you looking for something cool to read? 😎 What about using AI to improve protein sequencing? It's an exciting one! 🧪🧬🖥️ plentyofroom.beehiiv.com/p/ai-protein...

AI Protein Sequencing Breakthrough: Decoding Peptides Faster!
AI-powered protein sequencing: Instanovo uses advanced machine learning to decipher peptide structures, revolutionizing proteomics and biomedical research.
plentyofroom.beehiiv.com
May 6, 2025 at 1:28 PM
Are you looking for something cool to read? 😎 What about using AI to improve protein sequencing? It's an exciting one! 🧪🧬🖥️ plentyofroom.beehiiv.com/p/ai-protein...
Reposted by Andrew Severin

The tutorial for how to assemble organellar genomes from nuclear-targeted long reads is ready to be used. Please check it out
bioinformaticsworkbook.org/dataAnalysis...
#Genome #genomics #assembly #bioinformatics #chloroplast #mitochondria
bioinformaticsworkbook.org/dataAnalysis...
#Genome #genomics #assembly #bioinformatics #chloroplast #mitochondria

Extracting and Assembling a Mitochondrial and Chloroplast Genome from Nuclear-targeted Nanopore Reads
A workbook to help scientists working on bioinformatics projects
bioinformaticsworkbook.org
April 30, 2025 at 9:57 PM
The tutorial for how to assemble organellar genomes from nuclear-targeted long reads is ready to be used. Please check it out
bioinformaticsworkbook.org/dataAnalysis...
#Genome #genomics #assembly #bioinformatics #chloroplast #mitochondria
bioinformaticsworkbook.org/dataAnalysis...
#Genome #genomics #assembly #bioinformatics #chloroplast #mitochondria
Reposted by Andrew Severin

Wow. This is sooo good. Echoing @urbanevol.bsky.social this user’s manual for Ne should be required reading for popgen and conservation genetics folks. onlinelibrary.wiley.com/doi/10.1111/...

The Idiot's Guide to Effective Population Size
This is a reference manual for the elegant, yet hideously complex concept of effective population size (Ne), inspired by a classic, self-published manual of automotive repair ‘for the compleat idiot’...
onlinelibrary.wiley.com
February 17, 2025 at 6:26 PM
Wow. This is sooo good. Echoing @urbanevol.bsky.social this user’s manual for Ne should be required reading for popgen and conservation genetics folks. onlinelibrary.wiley.com/doi/10.1111/...
Reposted by Andrew Severin

Complete Genome of the iconic Pacific Banana Slug 🧬🧬
✅ A total of 2.3 Gb (Human Genome is 3.4 Gb)
✅ As part of California Conservation #Genomics Project (CCGP), this project will inform conservation policies
#genome #biodiversity #climatechange
✅ A total of 2.3 Gb (Human Genome is 3.4 Gb)
✅ As part of California Conservation #Genomics Project (CCGP), this project will inform conservation policies
#genome #biodiversity #climatechange

Scientists produce first complete genome of a banana slug
Scientists at UC Santa Cruz have completed the first end-to-end genome of the iconic Pacific banana slug, a species synonymous with California's coastal redwood forests and the university's beloved ma...
phys.org
February 8, 2025 at 1:34 PM
Complete Genome of the iconic Pacific Banana Slug 🧬🧬
✅ A total of 2.3 Gb (Human Genome is 3.4 Gb)
✅ As part of California Conservation #Genomics Project (CCGP), this project will inform conservation policies
#genome #biodiversity #climatechange
✅ A total of 2.3 Gb (Human Genome is 3.4 Gb)
✅ As part of California Conservation #Genomics Project (CCGP), this project will inform conservation policies
#genome #biodiversity #climatechange
Reposted by Andrew Severin

Unveiling the Yadong trout (Salmo trutta) genome! 🐟 A near-complete 2.49 Gb assembly with 96.87% anchored to 40 chromosomes. Key insights await! #Genomics PMID:39814780, Sci Data 2025, @ScientificData doi.org/10.1038/s415...

Near complete genome assembly of Yadong trout (Salmo trutta) - Scientific Data
Scientific Data - Near complete genome assembly of Yadong trout (Salmo trutta)
doi.org
January 18, 2025 at 9:02 PM
Unveiling the Yadong trout (Salmo trutta) genome! 🐟 A near-complete 2.49 Gb assembly with 96.87% anchored to 40 chromosomes. Key insights await! #Genomics PMID:39814780, Sci Data 2025, @ScientificData doi.org/10.1038/s415...
Reposted by Andrew Severin


Whoa! When a large language of life model generates a protein equivalent to ~500 million years of evolution.
@science.org
science.org/doi/10.1126/...
@science.org
science.org/doi/10.1126/...

Simulating 500 million years of evolution with a language model
More than three billion years of evolution have produced an image of biology encoded into the space of natural proteins. Here we show that language models trained at scale on evolutionary data can gen...
science.org
January 16, 2025 at 9:50 PM
Reposted by Andrew Severin


Should you learn R or Python first?
YouTube video by OMGenomics
youtu.be
January 10, 2025 at 7:01 PM
Reposted by Andrew Severin

Hornwort Genomes Provide Clues On How Plants Moved From Water To Land On Earth
astrobiology.com/2025/01/horn... #astrobiology #genomics #evolution
astrobiology.com/2025/01/horn... #astrobiology #genomics #evolution

Hornwort Genomes Provide Clues On How Plants Moved From Water To Land On Earth - Astrobiology
Over 450 million years ago, plants began the epic transition from water to dry land. Among the first pioneers were the ancestors of humble hornworts
astrobiology.com
January 7, 2025 at 5:53 PM
Hornwort Genomes Provide Clues On How Plants Moved From Water To Land On Earth
astrobiology.com/2025/01/horn... #astrobiology #genomics #evolution
astrobiology.com/2025/01/horn... #astrobiology #genomics #evolution
I have been working on a new project for teaching bioinformatics to beginners that involves an integrated holistic and project based approach to learning. As a bioinformatician with over 15 years of experience, I am humbled by how fast this field evolves as I go back to the basics! #bioinformatics
January 7, 2025 at 2:55 PM
I have been working on a new project for teaching bioinformatics to beginners that involves an integrated holistic and project based approach to learning. As a bioinformatician with over 15 years of experience, I am humbled by how fast this field evolves as I go back to the basics! #bioinformatics
Reposted by Andrew Severin

kMetaShot: a fast and reliable taxonomy classifier for metagenome-assembled genomes https://academic.oup.com/bib/article/26/1/bbae680/7941744 🧬🖥️🧪 https://github.com/gdefazio/kMetaShot


January 3, 2025 at 4:30 PM
kMetaShot: a fast and reliable taxonomy classifier for metagenome-assembled genomes https://academic.oup.com/bib/article/26/1/bbae680/7941744 🧬🖥️🧪 https://github.com/gdefazio/kMetaShot
Reposted by Andrew Severin

Two resources to learn bioinformatics yourself:
1. Path to a free self-taught education in Bioinformatics! github.com/ossu/bioinf...
#bioinformatics
1. Path to a free self-taught education in Bioinformatics! github.com/ossu/bioinf...
#bioinformatics

GitHub - ossu/bioinformatics: :microscope: Path to a free self-taught education in Bioinformatics!
:microscope: Path to a free self-taught education in Bioinformatics! - ossu/bioinformatics
github.com
January 4, 2025 at 3:15 PM
Two resources to learn bioinformatics yourself:
1. Path to a free self-taught education in Bioinformatics! github.com/ossu/bioinf...
#bioinformatics
1. Path to a free self-taught education in Bioinformatics! github.com/ossu/bioinf...
#bioinformatics
Reposted by Andrew Severin
Simply Statistics: Biologists, stop putting UMAP plots in your papers https://simplystatistics.org/posts/2024-12-23-biologists-stop-including-umap-plots-in-your-papers/ from @rafalab.bsky.social 🧬🖥️🧪




December 31, 2024 at 9:00 PM
Simply Statistics: Biologists, stop putting UMAP plots in your papers https://simplystatistics.org/posts/2024-12-23-biologists-stop-including-umap-plots-in-your-papers/ from @rafalab.bsky.social 🧬🖥️🧪
Reposted by Andrew Severin

🧬🖥️
Version 0.3.0 of nail is out. nail (github.com/TravisWheele...) is a tool for protein sequence annotation. It bridges most of the sensitivity gap between the two excellent tools MMSeqs2 (fast) and HMMER3 (very sensitive), and is >20x faster than HMMER3. Search with profile HMMs or single sequences.
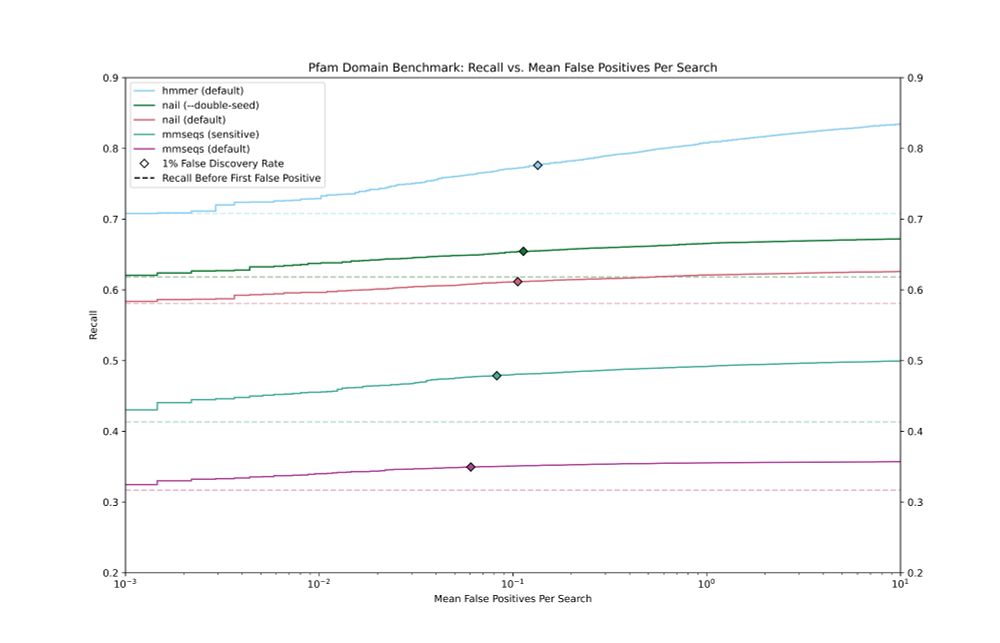
December 27, 2024 at 7:25 PM
🧬🖥️
Reposted by Andrew Severin
Genetic ancestry and population structure in the All of Us Research Program cohort https://www.biorxiv.org/content/10.1101/2024.12.21.629909v1 🧬🖥️🧪




December 24, 2024 at 4:30 PM
Genetic ancestry and population structure in the All of Us Research Program cohort https://www.biorxiv.org/content/10.1101/2024.12.21.629909v1 🧬🖥️🧪
Reposted by Andrew Severin
An Emirati pangenome incorporating a diploid telomere-to-telomere reference https://www.biorxiv.org/content/10.1101/2024.12.16.628631v1 🧬🖥️🧪




December 20, 2024 at 4:30 PM
An Emirati pangenome incorporating a diploid telomere-to-telomere reference https://www.biorxiv.org/content/10.1101/2024.12.16.628631v1 🧬🖥️🧪