



Amy Lu
@amyxlu.bsky.social
AI for drug discovery at Isomorphic Labs. Prev: PhD @ UC Berkeley | 🇨🇦
Reposted by Amy Lu

My time in @martinsteinegger.bsky.social's group is ending, but I’m staying in Korea to build a lab at Sungkyunkwan University School of Medicine. If you or someone you know is interested in molecular machine learning and open-source bioinformatics, please reach out. I am hiring!
mirdita.org
mirdita.org

Mirdita Lab - Laboratory for Computational Biology & Molecular Machine Learning
Mirdita Lab builds scalable bioinformatics methods.
mirdita.org
January 20, 2026 at 11:07 AM
My time in @martinsteinegger.bsky.social's group is ending, but I’m staying in Korea to build a lab at Sungkyunkwan University School of Medicine. If you or someone you know is interested in molecular machine learning and open-source bioinformatics, please reach out. I am hiring!
mirdita.org
mirdita.org
Reposted by Amy Lu

Just coincidentally found GenBank Release 84.0 from 1994 in the neighboring lab. Anyone out there with an even older version?


January 26, 2025 at 2:28 AM
Just coincidentally found GenBank Release 84.0 from 1994 in the neighboring lab. Anyone out there with an even older version?
In case you missed our ML for proteins seminar on CHEAP compression for protein embeddings back in October, here it is -- thanks @megthescientist.bsky.social for doing so much for the MLxProteins community 🫶
&& superstar @amyxlu.bsky.social (and prev. Co-organizer of @ml4proteins.bsky.social) CHEAP talk online now!
youtu.be/7XnROkjo5Vg?...
youtu.be/7XnROkjo5Vg?...

Tokenized and Continuous Embedding Compressions of Protein Sequence and Structure (CHEAP)
YouTube video by ML for protein engineering seminar series
youtu.be
December 28, 2024 at 3:00 AM
In case you missed our ML for proteins seminar on CHEAP compression for protein embeddings back in October, here it is -- thanks @megthescientist.bsky.social for doing so much for the MLxProteins community 🫶
Reposted by Amy Lu

•introduced “zero shot prediction” as a question of guessing a bioassay’s outcome by likelihoods of pLMs
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)

December 16, 2024 at 6:29 AM
•introduced “zero shot prediction” as a question of guessing a bioassay’s outcome by likelihoods of pLMs
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
•commented on biases in evolutionary signals from Tree of life used to train pLMs (a favorite paper I read in 2024: shorturl.at/fbC7g)
December 15, 2024 at 10:27 PM
Reposted by Amy Lu

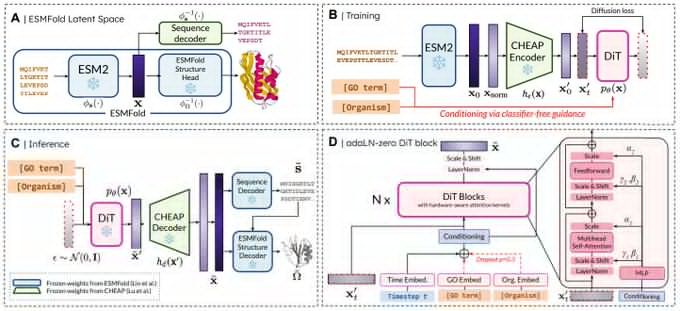
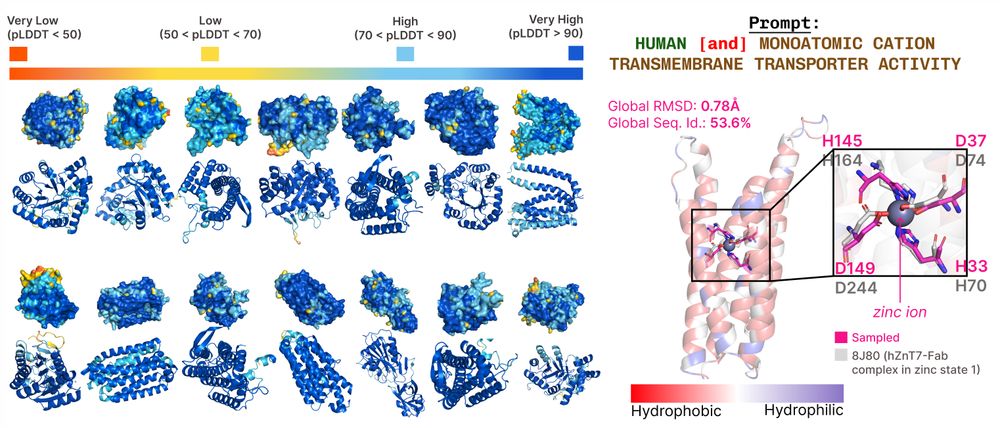
We trained a model to co-generate protein sequence and structure by working in the ESMFold latent space, which encodes both. PLAID only requires sequences for training but generates all-atom structures!
Really proud of @amyxlu.bsky.social 's effort leading this project end-to-end!
Really proud of @amyxlu.bsky.social 's effort leading this project end-to-end!


December 9, 2024 at 2:58 PM
We trained a model to co-generate protein sequence and structure by working in the ESMFold latent space, which encodes both. PLAID only requires sequences for training but generates all-atom structures!
Really proud of @amyxlu.bsky.social 's effort leading this project end-to-end!
Really proud of @amyxlu.bsky.social 's effort leading this project end-to-end!
1/🧬 Excited to share PLAID, our new approach for co-generating sequence and all-atom protein structures by sampling from the latent space of ESMFold. This requires only sequences during training, which unlocks more data and annotations:
bit.ly/plaid-proteins
🧵
bit.ly/plaid-proteins
🧵
December 6, 2024 at 5:44 PM
1/🧬 Excited to share PLAID, our new approach for co-generating sequence and all-atom protein structures by sampling from the latent space of ESMFold. This requires only sequences during training, which unlocks more data and annotations:
bit.ly/plaid-proteins
🧵
bit.ly/plaid-proteins
🧵