



Yo Akiyama
@yoakiyama.bsky.social
MIT EECS PhD student in solab.org Building ML methods to understand and engineer biology
Sorry for the slow responses lots of traveling this week. We use a paired MSA for the toxin-antitoxin proteins (many rows from different species). The top row is the mutated antitoxin sequence + fixed toxin seq, and we compute the pseudolikelihood over the 4 mutated positions by masking each
August 10, 2025 at 9:13 PM
Sorry for the slow responses lots of traveling this week. We use a paired MSA for the toxin-antitoxin proteins (many rows from different species). The top row is the mutated antitoxin sequence + fixed toxin seq, and we compute the pseudolikelihood over the 4 mutated positions by masking each
Reposted by Yo Akiyama

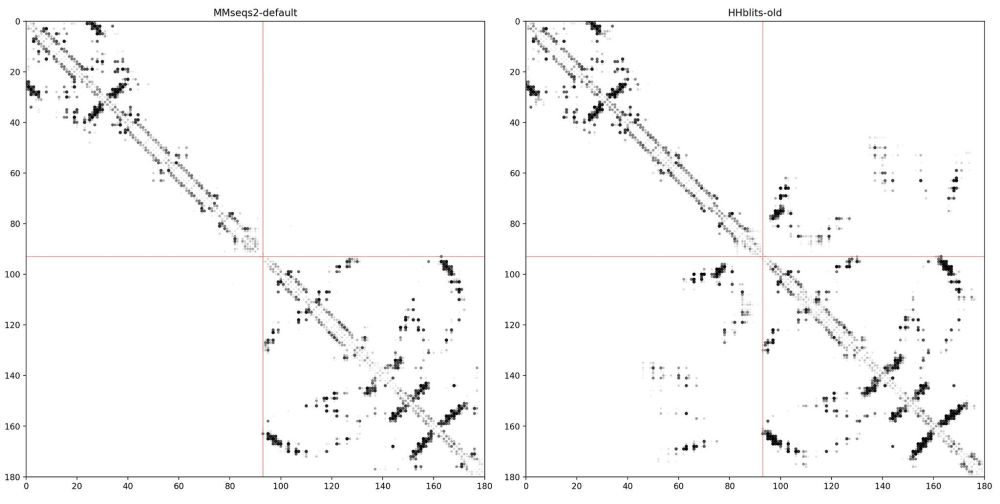
Side story: While working on the Google Colab notebook for MSA pairformer. We encountered a problem: The MMseqs2 ColabFold MSA did not show any contacts at protein interfaces, while our old HHblits alignments showed clear contacts 🫥... (2/4)
August 5, 2025 at 7:39 AM
Side story: While working on the Google Colab notebook for MSA pairformer. We encountered a problem: The MMseqs2 ColabFold MSA did not show any contacts at protein interfaces, while our old HHblits alignments showed clear contacts 🫥... (2/4)
Our code and Google Colab notebook can be found here
github.com/yoakiyama/MS...
colab.research.google.com/github/yoaki...
Please reach out with any comments, questions or concerns! We really appreciate all of the feedback from the community and are excited to see how y'all will use MSA Pairformer :)
github.com/yoakiyama/MS...
colab.research.google.com/github/yoaki...
Please reach out with any comments, questions or concerns! We really appreciate all of the feedback from the community and are excited to see how y'all will use MSA Pairformer :)

GitHub - yoakiyama/MSA_Pairformer
Contribute to yoakiyama/MSA_Pairformer development by creating an account on GitHub.
github.com
August 5, 2025 at 6:31 AM
Our code and Google Colab notebook can be found here
github.com/yoakiyama/MS...
colab.research.google.com/github/yoaki...
Please reach out with any comments, questions or concerns! We really appreciate all of the feedback from the community and are excited to see how y'all will use MSA Pairformer :)
github.com/yoakiyama/MS...
colab.research.google.com/github/yoaki...
Please reach out with any comments, questions or concerns! We really appreciate all of the feedback from the community and are excited to see how y'all will use MSA Pairformer :)
Special thanks to all members of our team! Their mentorship and support are truly world-class.
And a huge shoutout to the entire solab! I'm so grateful to work with these brilliant and supportive scientists every day. Keep an eye out for exciting work coming out from the team!
And a huge shoutout to the entire solab! I'm so grateful to work with these brilliant and supportive scientists every day. Keep an eye out for exciting work coming out from the team!

August 5, 2025 at 6:31 AM
Special thanks to all members of our team! Their mentorship and support are truly world-class.
And a huge shoutout to the entire solab! I'm so grateful to work with these brilliant and supportive scientists every day. Keep an eye out for exciting work coming out from the team!
And a huge shoutout to the entire solab! I'm so grateful to work with these brilliant and supportive scientists every day. Keep an eye out for exciting work coming out from the team!
Thanks for tuning in--we've already received incredibly valuable feedback from the community and will continue to update our work!
We're excited for all of MSA Pairformer's potential applications for biological discovery and for the future of memory and parameter efficient pLMs
We're excited for all of MSA Pairformer's potential applications for biological discovery and for the future of memory and parameter efficient pLMs

August 5, 2025 at 6:31 AM
Thanks for tuning in--we've already received incredibly valuable feedback from the community and will continue to update our work!
We're excited for all of MSA Pairformer's potential applications for biological discovery and for the future of memory and parameter efficient pLMs
We're excited for all of MSA Pairformer's potential applications for biological discovery and for the future of memory and parameter efficient pLMs
We made some updates to MSA pairing with MMseqs2 for modeling protein-protein interactions! Mispairing sequences leads to contamination of non-interacting paralogs. We use genomic proximity to improve pairing, and find that MSA Pairformer's predictions reflect pairing quality

August 5, 2025 at 6:31 AM
We made some updates to MSA pairing with MMseqs2 for modeling protein-protein interactions! Mispairing sequences leads to contamination of non-interacting paralogs. We use genomic proximity to improve pairing, and find that MSA Pairformer's predictions reflect pairing quality
We also looked into how perturbing MSAs effects contact prediction. Interestingly, unlike MSA Transformer, MSA Pairformer doesn't hallucinate contacts after ablating covariance from the MSA. Hints at fundamental differences in how they extract pairwise relationships

August 5, 2025 at 6:31 AM
We also looked into how perturbing MSAs effects contact prediction. Interestingly, unlike MSA Transformer, MSA Pairformer doesn't hallucinate contacts after ablating covariance from the MSA. Hints at fundamental differences in how they extract pairwise relationships
We ablate triangle updates and replace it with a pair updates analog. As expected, contact precision deteriorates, and the false positives are enriched in indirect correlations. These results suggest the role of triangle updates in disentangling direct and indirect correlations

August 5, 2025 at 6:31 AM
We ablate triangle updates and replace it with a pair updates analog. As expected, contact precision deteriorates, and the false positives are enriched in indirect correlations. These results suggest the role of triangle updates in disentangling direct and indirect correlations
Whereas the ESM2 family models show an interesting trade-off between contact precision and zero-shot variant effect prediction, MSA Pairformer performs strongly in both
P.S. this figure slightly differs from what's in the preprint and will be updated in v2 of the paper!
P.S. this figure slightly differs from what's in the preprint and will be updated in v2 of the paper!

August 5, 2025 at 6:31 AM
Whereas the ESM2 family models show an interesting trade-off between contact precision and zero-shot variant effect prediction, MSA Pairformer performs strongly in both
P.S. this figure slightly differs from what's in the preprint and will be updated in v2 of the paper!
P.S. this figure slightly differs from what's in the preprint and will be updated in v2 of the paper!
Using a library of mutants at four key ParD3-ParE3 toxin-antitoxin interface residues from Aakre et al. (2015), we find that MSA Pairformer's pseudolikelihood scores better discriminate binders and non-binders, directly related to its ability to model the interaction

August 5, 2025 at 6:31 AM
Using a library of mutants at four key ParD3-ParE3 toxin-antitoxin interface residues from Aakre et al. (2015), we find that MSA Pairformer's pseudolikelihood scores better discriminate binders and non-binders, directly related to its ability to model the interaction
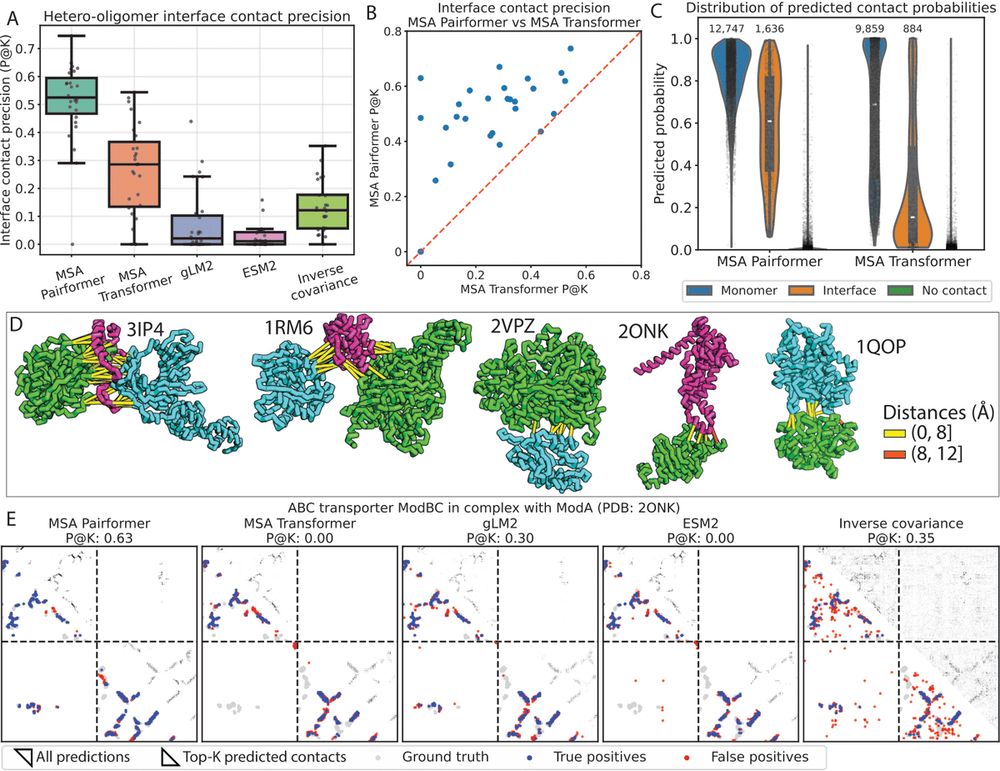
Beyond monomeric structures, accurate prediction of protein-protein interactions is crucial for understanding protein function. MSA Pairformer substantially outperforms all other methods in predicting residue-residue interactions at hetero-oligomeric interfaces
August 5, 2025 at 6:31 AM
Beyond monomeric structures, accurate prediction of protein-protein interactions is crucial for understanding protein function. MSA Pairformer substantially outperforms all other methods in predicting residue-residue interactions at hetero-oligomeric interfaces
On unsupervised long-range contact prediction, it outperforms MSA Transformer and all ESM2 family models, suggesting that its representations more accurately capture structural signals from evolutionary context

August 5, 2025 at 6:31 AM
On unsupervised long-range contact prediction, it outperforms MSA Transformer and all ESM2 family models, suggesting that its representations more accurately capture structural signals from evolutionary context
We introduce MSA Pairformer, a 111M parameter memory-efficient MSA-based protein language model that builds on AlphaFold3's MSA module to extract evolutionary signals most relevant to the query sequence via a query-biased outer product

August 5, 2025 at 6:31 AM
We introduce MSA Pairformer, a 111M parameter memory-efficient MSA-based protein language model that builds on AlphaFold3's MSA module to extract evolutionary signals most relevant to the query sequence via a query-biased outer product
Current efforts to improve self-supervised protein language modeling focus on scaling model and training data size, requiring vast resources and limiting accessibility. Can we
1) scale down protein language modeling?
2) expand its scope?
1) scale down protein language modeling?
2) expand its scope?
August 5, 2025 at 6:31 AM
Current efforts to improve self-supervised protein language modeling focus on scaling model and training data size, requiring vast resources and limiting accessibility. Can we
1) scale down protein language modeling?
2) expand its scope?
1) scale down protein language modeling?
2) expand its scope?