




vishal
@vishal-learner.bsky.social
Machine Learning. https://fast.ai community member. Will post about sports occasionally. #FlyEaglesFly
https://www.youtube.com/@vishal_learner
https://www.youtube.com/@vishal_learner
Initial tests with Claude Haiku show promise - it successfully distinguished between stronger and weaker models. Next step: building an evaluator with FastHTML to grade 450 completions (150 prompts × 3 models). Stay tuned!
April 29, 2025 at 5:42 AM
Initial tests with Claude Haiku show promise - it successfully distinguished between stronger and weaker models. Next step: building an evaluator with FastHTML to grade 450 completions (150 prompts × 3 models). Stay tuned!
My scoring system uses 0 (failure), 0.5 (partial success), or 1.0 (success) points per criterion for each category. Diff categories have diff numbers of criteria: Grammar (5), Creativity (4), Plot (4), Context-tracking (3), and Factual/Reasoning (1 each) so I'll need to normalize
April 29, 2025 at 5:42 AM
My scoring system uses 0 (failure), 0.5 (partial success), or 1.0 (success) points per criterion for each category. Diff categories have diff numbers of criteria: Grammar (5), Creativity (4), Plot (4), Context-tracking (3), and Factual/Reasoning (1 each) so I'll need to normalize
Good creativity/plot prompts provide opportunities w/o sacrificing consistency. Example: "Once upon a time, there was a tiger who liked to play the guitar" offers fertile ground for creativity without losing coherence, while others might force models to choose between them.
April 29, 2025 at 5:42 AM
Good creativity/plot prompts provide opportunities w/o sacrificing consistency. Example: "Once upon a time, there was a tiger who liked to play the guitar" offers fertile ground for creativity without losing coherence, while others might force models to choose between them.
When analyzing the 44 TinyStories eval prompts, I discovered factual prompts were the easiest to isolate, context-tracking prompts were dime a dozen, and reasoning prompts were hard to distinguish from context tracking. This led me to curate category-specific prompts.
April 29, 2025 at 5:42 AM
When analyzing the 44 TinyStories eval prompts, I discovered factual prompts were the easiest to isolate, context-tracking prompts were dime a dozen, and reasoning prompts were hard to distinguish from context tracking. This led me to curate category-specific prompts.

Project goals: Study both training dynamics of tiny models and their language capabilities (grammar, context tracking, factual knowledge, reasoning, creativity, and plot construction). Looking forward to sharing more progress soon!
/end
/end

April 27, 2025 at 7:51 AM
Project goals: Study both training dynamics of tiny models and their language capabilities (grammar, context tracking, factual knowledge, reasoning, creativity, and plot construction). Looking forward to sharing more progress soon!
/end
/end
Next steps: Pausing training to build evaluation infrastructure. Will use Gemini Flash 2.5 or Claude Haiku 3.5 as LLM judges (on TinyStories-1M/8M/28M/33M-generated stories), comparing against manual evaluation to refine scoring prompts for six capability categories.

April 27, 2025 at 7:51 AM
Next steps: Pausing training to build evaluation infrastructure. Will use Gemini Flash 2.5 or Claude Haiku 3.5 as LLM judges (on TinyStories-1M/8M/28M/33M-generated stories), comparing against manual evaluation to refine scoring prompts for six capability categories.
Details on the architectures I'm using---the LlamaConfigs are shared in the blog post above. I'm loosely referencing the official TinyStories models (intermediate dim = 4 x hidden dim). Intentionally undershooting named model sizes.

April 27, 2025 at 7:51 AM
Details on the architectures I'm using---the LlamaConfigs are shared in the blog post above. I'm loosely referencing the official TinyStories models (intermediate dim = 4 x hidden dim). Intentionally undershooting named model sizes.
Cost analysis: L4 GPU is more efficient for 5M model (~$0.20/epoch), while A100 is better for larger models. 125M model costs ~$0.84/epoch. This gives me a baseline to plan my budget for longer training runs.
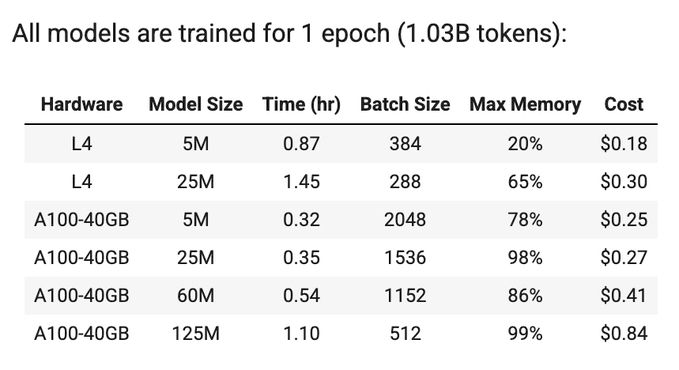
April 27, 2025 at 7:51 AM
Cost analysis: L4 GPU is more efficient for 5M model (~$0.20/epoch), while A100 is better for larger models. 125M model costs ~$0.84/epoch. This gives me a baseline to plan my budget for longer training runs.

P.S. if you are unfamiliar, here are my main takeaways from the TinyStories (Eldan/Li) and Small-scale proxies (Wortsman, et al) papers. Really incredibly inspiring work. I am giddy to jump into this project. LFG!!!


April 26, 2025 at 6:27 AM
P.S. if you are unfamiliar, here are my main takeaways from the TinyStories (Eldan/Li) and Small-scale proxies (Wortsman, et al) papers. Really incredibly inspiring work. I am giddy to jump into this project. LFG!!!
I'll end with one of my favorite quotes. I am standing on the shoulders of giants to even consider taking on this research project!

April 26, 2025 at 6:27 AM
I'll end with one of my favorite quotes. I am standing on the shoulders of giants to even consider taking on this research project!
Here's a recap of my presentation, highlighting my goals for the TinyScale Lab research project!

April 26, 2025 at 6:27 AM
Here's a recap of my presentation, highlighting my goals for the TinyScale Lab research project!
My project timeline consists of 4 phases. I expect this project to take 8-12 months (which means it will probably take two years 😅). First order of business is building the eval and logging setup, and then running initial training runs. Phase 2 involves core experimentation!

April 26, 2025 at 6:27 AM
My project timeline consists of 4 phases. I expect this project to take 8-12 months (which means it will probably take two years 😅). First order of business is building the eval and logging setup, and then running initial training runs. Phase 2 involves core experimentation!
My rough back-of-the-envelope budget is $2000. I'll closely monitor this each week. If it seems to be heading in that direction consistently, I'll have to seriously consider building my own GPU rig. But time will tell!

April 26, 2025 at 6:27 AM
My rough back-of-the-envelope budget is $2000. I'll closely monitor this each week. If it seems to be heading in that direction consistently, I'll have to seriously consider building my own GPU rig. But time will tell!
Following fastai principles, I'll build in public: sharing code, models, datasets, weekly updates, and interactive visualizations. If this work saves someone time, money, or gives them insight, that would be truly the best reward.

April 26, 2025 at 6:27 AM
Following fastai principles, I'll build in public: sharing code, models, datasets, weekly updates, and interactive visualizations. If this work saves someone time, money, or gives them insight, that would be truly the best reward.
What excites me most: I cannot wait to see some of these capabilities emerge with model size or training steps - watching grammar emerge first, then consistency, and finally creativity, just as the TinyStories paper observed.
April 26, 2025 at 6:27 AM
What excites me most: I cannot wait to see some of these capabilities emerge with model size or training steps - watching grammar emerge first, then consistency, and finally creativity, just as the TinyStories paper observed.
My plan: extensive logging of training dynamics + evaluating capabilities with LLM judge scoring. I'll train 100+ model variations across different learning rates and stability techniques (QK-layernorm and z-loss).


April 26, 2025 at 6:27 AM
My plan: extensive logging of training dynamics + evaluating capabilities with LLM judge scoring. I'll train 100+ model variations across different learning rates and stability techniques (QK-layernorm and z-loss).
Making ML research accessible to resource-constrained environments isn't trivial - it's essential for the field's diversity and progress! I'm using modest computational resources (but substantial for me) to conduct what I think is meaningful research.

April 26, 2025 at 6:27 AM
Making ML research accessible to resource-constrained environments isn't trivial - it's essential for the field's diversity and progress! I'm using modest computational resources (but substantial for me) to conduct what I think is meaningful research.
I believe this approach—using tiny models as proxies to study phenomena relevant to models of all sizes—represents an underexplored path that could benefit other resource-constrained researchers. I think this is how most of the world's potential researchers would need to work.

April 26, 2025 at 6:27 AM
I believe this approach—using tiny models as proxies to study phenomena relevant to models of all sizes—represents an underexplored path that could benefit other resource-constrained researchers. I think this is how most of the world's potential researchers would need to work.
My hypothesis: training stability directly affects specific model capabilities in predictable ways. I'll train models from 3M to 120M params, analyzing how logits, gradients, parameters, and loss relate to capabilities like grammar, consistency, and reasoning.

April 26, 2025 at 6:27 AM
My hypothesis: training stability directly affects specific model capabilities in predictable ways. I'll train models from 3M to 120M params, analyzing how logits, gradients, parameters, and loss relate to capabilities like grammar, consistency, and reasoning.