




vishal
@vishal-learner.bsky.social
Machine Learning. https://fast.ai community member. Will post about sports occasionally. #FlyEaglesFly
https://www.youtube.com/@vishal_learner
https://www.youtube.com/@vishal_learner
Pinned
vishal
@vishal-learner.bsky.social
· Dec 17

Introducing the fastbook-benchmark Information Retrieval QA Dataset
YouTube video by vishal
www.youtube.com
I published a 6-video series on Information Retrieval fundamentals!
1. fastbook-benchmark Overview
2. Document Processing
3. Full Text Search
4. Scoring Retrieval Results
5. Single Vector Search
6. ColBERT search
Code: github.com/vishalbakshi...
YT Playlist: www.youtube.com/watch?v=VsVI...
1. fastbook-benchmark Overview
2. Document Processing
3. Full Text Search
4. Scoring Retrieval Results
5. Single Vector Search
6. ColBERT search
Code: github.com/vishalbakshi...
YT Playlist: www.youtube.com/watch?v=VsVI...
Designing robust LM evals = take something squishy like language and build structure around it. For TinyScaleLab, I create separate prompt sets for factual knowledge, reasoning, context tracking, creativity, and plot. 150 prompts total. Each category needs unique prompts imo 🧵
April 29, 2025 at 5:42 AM
Designing robust LM evals = take something squishy like language and build structure around it. For TinyScaleLab, I create separate prompt sets for factual knowledge, reasoning, context tracking, creativity, and plot. 150 prompts total. Each category needs unique prompts imo 🧵
(beyond) cool to see scaling laws in action
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558

April 27, 2025 at 7:57 AM
(beyond) cool to see scaling laws in action
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
TinyScaleLab update: Completed initial training runs to estimate costs. Using 4 model sizes: 5M, 25M, 60M, and 125M parameters. Training on TinyStories dataset (4.9M stories, ~1B tokens) with Llama2 tokenizer (32k vocab).

April 27, 2025 at 7:51 AM
TinyScaleLab update: Completed initial training runs to estimate costs. Using 4 model sizes: 5M, 25M, 60M, and 125M parameters. Training on TinyStories dataset (4.9M stories, ~1B tokens) with Llama2 tokenizer (32k vocab).
Here's the blog post version of my TinyScale Lab research project kickoff video!
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.

April 27, 2025 at 3:20 AM
Here's the blog post version of my TinyScale Lab research project kickoff video!
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
Excited to kickoff a new research project: TinyScale Lab! I'm researching the connection b/w training dynamics and model capabilities in tiny LMs. Following the work of TinyStories (Eldan & Li) and Small-scale proxies (Wortsman, et al) papers, and building a bridge between them🧵

April 26, 2025 at 6:27 AM
Excited to kickoff a new research project: TinyScale Lab! I'm researching the connection b/w training dynamics and model capabilities in tiny LMs. Following the work of TinyStories (Eldan & Li) and Small-scale proxies (Wortsman, et al) papers, and building a bridge between them🧵
Just posted a new video breaking down "Small-Scale Proxies for Large-Scale Transformer Training Instabilities" from Google DeepMind - one of my favorite papers because it shows how tiny models exhibit can predict large scale training problems! 🧵

April 25, 2025 at 6:16 AM
Just posted a new video breaking down "Small-Scale Proxies for Large-Scale Transformer Training Instabilities" from Google DeepMind - one of my favorite papers because it shows how tiny models exhibit can predict large scale training problems! 🧵
Reposted by vishal
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...

April 23, 2025 at 5:04 AM
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...
April 23, 2025 at 5:04 AM
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...
Just wrapped up a deep dive into matrix multiplication optimization from fastai course part 2 Lesson 11! Started w/ naive Python loops, ended with a 12,000x speedup using Numba-compiled broadcasting!
Blog: vishalbakshi.github.io/blog/posts/2...
Video: www.youtube.com/watch?v=-t8b...
Blog: vishalbakshi.github.io/blog/posts/2...
Video: www.youtube.com/watch?v=-t8b...
Vishal Bakshi’s Blog - Optimizing Matrix Multiplication Using Numba and Broadcasting
Following the fastai course part 2 Lesson 11 video, I optimize the naive Python nested for-loop matrix multiplication using PyTorch, NumPy and Numba to achieve a 12000x speedup!
vishalbakshi.github.io
April 22, 2025 at 2:20 AM
Just wrapped up a deep dive into matrix multiplication optimization from fastai course part 2 Lesson 11! Started w/ naive Python loops, ended with a 12,000x speedup using Numba-compiled broadcasting!
Blog: vishalbakshi.github.io/blog/posts/2...
Video: www.youtube.com/watch?v=-t8b...
Blog: vishalbakshi.github.io/blog/posts/2...
Video: www.youtube.com/watch?v=-t8b...
My eyes always gloss over at the naive matmul loop so I decided to annotate it once and for all---and oh! back on the fastai part 2 course horse!

April 21, 2025 at 3:22 PM
My eyes always gloss over at the naive matmul loop so I decided to annotate it once and for all---and oh! back on the fastai part 2 course horse!
Just posted a new video breaking down the TinyStories paper - I didn't give enough credit to how amazing this paper was until I participated in a Tiny Hackathon myself! The simplicity of this work sometimes doesn't give enough credit to how incredible the insights are 🧵

April 21, 2025 at 1:32 AM
Just posted a new video breaking down the TinyStories paper - I didn't give enough credit to how amazing this paper was until I participated in a Tiny Hackathon myself! The simplicity of this work sometimes doesn't give enough credit to how incredible the insights are 🧵
Reposted by vishal

@hamel.bsky.social & his wisdom on evals, error analysis, looking at your data is what we need. Here are his 10 Don'ts:
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
April 16, 2025 at 1:05 AM
@hamel.bsky.social & his wisdom on evals, error analysis, looking at your data is what we need. Here are his 10 Don'ts:
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
Just posted a new video about looking at your data! With an iterator! This is something I do for retrieval when I have a few hundred examples, I'll even go up to 2000 for simple binary cases. Yeah, it's a bit tedious, but after you do it you KNOW your code is correct
www.youtube.com/watch?v=vD24...
www.youtube.com/watch?v=vD24...

Look at Your Data: Manual Validation of Retrieval Metrics
YouTube video by vishal
www.youtube.com
April 7, 2025 at 4:37 AM
Just posted a new video about looking at your data! With an iterator! This is something I do for retrieval when I have a few hundred examples, I'll even go up to 2000 for simple binary cases. Yeah, it's a bit tedious, but after you do it you KNOW your code is correct
www.youtube.com/watch?v=vD24...
www.youtube.com/watch?v=vD24...
I just uploaded a new video walking through how I created a custom Composer callback to track data types during mixed precision training with LLM-Foundry! Started as a simple experiment to understand what's happening with activations, gradients, weights, and optimizer states. 🧵

April 3, 2025 at 3:16 AM
I just uploaded a new video walking through how I created a custom Composer callback to track data types during mixed precision training with LLM-Foundry! Started as a simple experiment to understand what's happening with activations, gradients, weights, and optimizer states. 🧵
While vibe coding with Claude, it introduced me to unfamiliar behavior: using `__get__(obj)` to convert a function to a bound method of the given obj. This was needed to monkey patch my self attn module's forward pass to log input data types. This led me to the Python docs!🧵
April 2, 2025 at 4:13 PM
While vibe coding with Claude, it introduced me to unfamiliar behavior: using `__get__(obj)` to convert a function to a bound method of the given obj. This was needed to monkey patch my self attn module's forward pass to log input data types. This led me to the Python docs!🧵
Reposted by vishal

Check out our website: sophontai.com
Read our manifesto/announcement: tanishq.ai/blog/sophont
If you're interested in building & collaborating in this space, whether you're in genAI or medicine/pharma/life sciences, feel free to reach out at: contact@sophontai.com
Read our manifesto/announcement: tanishq.ai/blog/sophont
If you're interested in building & collaborating in this space, whether you're in genAI or medicine/pharma/life sciences, feel free to reach out at: contact@sophontai.com
April 1, 2025 at 8:49 PM
Check out our website: sophontai.com
Read our manifesto/announcement: tanishq.ai/blog/sophont
If you're interested in building & collaborating in this space, whether you're in genAI or medicine/pharma/life sciences, feel free to reach out at: contact@sophontai.com
Read our manifesto/announcement: tanishq.ai/blog/sophont
If you're interested in building & collaborating in this space, whether you're in genAI or medicine/pharma/life sciences, feel free to reach out at: contact@sophontai.com
New paper reading video: Small-scale proxies for large-scale Transformer training instabilities. This was one of the coolest papers I've read in awhile, largely because it's so applicable for small model training, and presents tangible metrics that can be measured by anyone
youtu.be/tyqfTM3enj8?...
youtu.be/tyqfTM3enj8?...

Paper Reading: Small-scale proxies for large-scale Transformer training instabilities
YouTube video by vishal
youtu.be
March 31, 2025 at 6:08 PM
New paper reading video: Small-scale proxies for large-scale Transformer training instabilities. This was one of the coolest papers I've read in awhile, largely because it's so applicable for small model training, and presents tangible metrics that can be measured by anyone
youtu.be/tyqfTM3enj8?...
youtu.be/tyqfTM3enj8?...
Published a new Paper Reading: Overtrained Language Models Are Harder to Fine-Tune where I use Claude to clarify concepts/figures about "catastrophic overtraining" where exceeding a pretraining token threshold harms FT performance (for base and new tasks)
www.youtube.com/watch?v=wmS0...
www.youtube.com/watch?v=wmS0...

Paper Reading: Overtrained Language Models Are Harder to Fine-Tune
YouTube video by vishal
www.youtube.com
March 27, 2025 at 9:50 PM
Published a new Paper Reading: Overtrained Language Models Are Harder to Fine-Tune where I use Claude to clarify concepts/figures about "catastrophic overtraining" where exceeding a pretraining token threshold harms FT performance (for base and new tasks)
www.youtube.com/watch?v=wmS0...
www.youtube.com/watch?v=wmS0...
I made a new type of video (for me): reading a paper live! I read the SmolLM2 paper, googling things along the way and asking clarifying questions to Claude (using a project with PDF paper as knowledge).
www.youtube.com/watch?v=ibsw...
www.youtube.com/watch?v=ibsw...

Paper Reading: SmolLM2
YouTube video by vishal
www.youtube.com
March 27, 2025 at 4:13 AM
I made a new type of video (for me): reading a paper live! I read the SmolLM2 paper, googling things along the way and asking clarifying questions to Claude (using a project with PDF paper as knowledge).
www.youtube.com/watch?v=ibsw...
www.youtube.com/watch?v=ibsw...
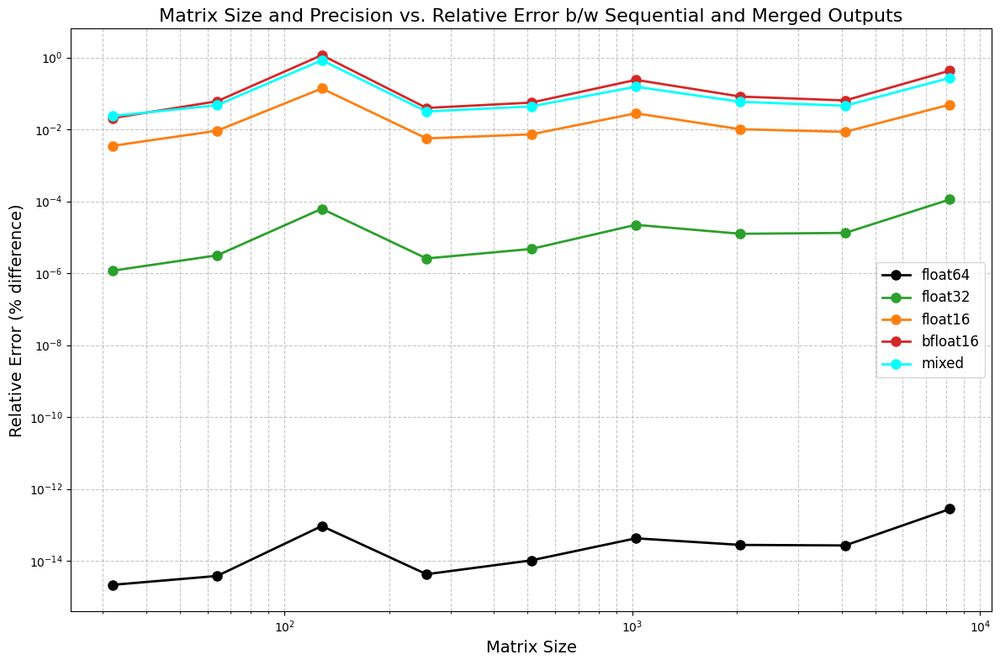
I made a video calculating the relative mean absolute difference between sequential and merged nn.Linear layer outputs. Two takeaways: relative error increases as you go from f64 < f32< f16 < bf16 and as matrix size increases. A toy example but still fun to analyze! Link below.
March 27, 2025 at 1:08 AM
I made a video calculating the relative mean absolute difference between sequential and merged nn.Linear layer outputs. Two takeaways: relative error increases as you go from f64 < f32< f16 < bf16 and as matrix size increases. A toy example but still fun to analyze! Link below.
Reposted by vishal

We also have so many other interesting details in the paper that have entirely changed the way I think about pre-training!
And thanks to my collaborators!
Sachin Goyal
Kaiyue Wen
Tanishq Kumar
@xiangyue96.bsky.social
@sadhika.bsky.social
@gneubig.bsky.social
@adtraghunathan.bsky.social
10/10
And thanks to my collaborators!
Sachin Goyal
Kaiyue Wen
Tanishq Kumar
@xiangyue96.bsky.social
@sadhika.bsky.social
@gneubig.bsky.social
@adtraghunathan.bsky.social
10/10

Overtrained Language Models Are Harder to Fine-Tune
Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this ...
arxiv.org
March 26, 2025 at 6:35 PM
We also have so many other interesting details in the paper that have entirely changed the way I think about pre-training!
And thanks to my collaborators!
Sachin Goyal
Kaiyue Wen
Tanishq Kumar
@xiangyue96.bsky.social
@sadhika.bsky.social
@gneubig.bsky.social
@adtraghunathan.bsky.social
10/10
And thanks to my collaborators!
Sachin Goyal
Kaiyue Wen
Tanishq Kumar
@xiangyue96.bsky.social
@sadhika.bsky.social
@gneubig.bsky.social
@adtraghunathan.bsky.social
10/10
Noteworthy that the synthients and the humans only collaborate on the side of resistance, whereas synthients dominate humans in the Matrix. Hard not to think about AI augmenting human capacity, not replacing it.
March 25, 2025 at 2:51 AM
Noteworthy that the synthients and the humans only collaborate on the side of resistance, whereas synthients dominate humans in the Matrix. Hard not to think about AI augmenting human capacity, not replacing it.
"Not all seek to control. Just as not all wish to be free."
March 25, 2025 at 2:44 AM
"Not all seek to control. Just as not all wish to be free."
Just realized during the umptieth watch of Matrix 4 that after they extract Neo and he comes to on the ship Bugs says "what's up doc" to Ellster. Amazing 🥕
March 25, 2025 at 2:27 AM
Just realized during the umptieth watch of Matrix 4 that after they extract Neo and he comes to on the ship Bugs says "what's up doc" to Ellster. Amazing 🥕
Over the past couple of months as I've been doing research using the HuggingFace peft library, I've created 5 videos so far, ranging from short TILs to longer deep dives. I expect more to come. It's been a fun experience so far.
www.youtube.com/playlist?lis...
www.youtube.com/playlist?lis...

March 24, 2025 at 4:43 AM
Over the past couple of months as I've been doing research using the HuggingFace peft library, I've created 5 videos so far, ranging from short TILs to longer deep dives. I expect more to come. It's been a fun experience so far.
www.youtube.com/playlist?lis...
www.youtube.com/playlist?lis...